For noen måneder siden hadde jeg en videokonferanse med et ungt menneske som lurte på om hun skulle søke doktorgradsstudium på BI. Vedkommende var atypisk i mange dimensjoner fra de fleste doktorgradsstudenter jeg har møtt, men hadde tatt en mastergrad, likte jobben med masteroppgaven, og lurte på om det å fordype seg ytterligere kunne være det neste. I tillegg – og her er poenget – hadde hun blitt anbefalt å vurdere en doktorgrad av sin AI-baserte coach.
Vi diskuterte litt frem og tilbake, og jeg anbefalte henne å søke. Om hun gjorde det, vet jeg ikke. Men jeg ble sittende og tenke etterpå.
Det å ha en coach, terapeut, rådgiver eller for den saks skyld venn å snakke med, er jo i seg selv ikke noe negativt. Ei heller er det negativt at denne coach’en er digital – den er i alle fall billig (foreløpig) og tilgjengelig til alle døgnets tider. Gitt at den er «promptet» skikkelig (rolle, situasjon, målsetting) vil vel også svarene være noe i retning av hva en menneskelig coach. Og digitale samtalepartnere har jo lange tradisjoner, som Joseph Weizenbaums Eliza viste – i 1966!
Men hva slags motivasjon har en slik coach – eller, for å si det på AI-språket: Hva er dens belønningssystem (reward function), og hvordan påvirker målsettingen hvilke svar den gir?
Svaret er at de i hovedsak er designet til å være hyggelige mot oss.
Belønninger former resultater
Store språkmodeller svelger enorme tekstmengder og trener seg opp å forutsi neste ord i en rekkefølge, ved en rekke matematiske prosesser, hovedsaklig matriseregning (glimrende forklart i denne videoserien.) Etter denne treningen gjennomgår modellen en finpussfase kalt Reinforcement Learning from Human Feedback (RLHF). Mennesker rangerer modellens svar, og modellen justeres mot å produsere svar med høy rangering. Et av problemene med denne prosessen er at vi mennesker liker å få rett: Vi liker svar som bekrefter våre antagelser, som er formulert med selvtillit og en viss autoritet, og som ikke utfordrer oss for mye. Dermed lærer ikke nødvendigvis modellene å bli sannferdige eller kloke. De lærer å være behagelige.
Dette blir et utbredt problem etterhvert. Sharma et al (2023) fant at ulike modeller hadde en tendens til å være smigrende. (Det engelske utrykket er sycophancy, norsk sykofant, en person som smigrer – og et ord jeg synes burde brukes mer). Modellene endrer korrekte svar når brukeren uttrykker tvil, gir etter for press selv om de har rett, og tilpasser meninger til hva brukerne signaliserer at de ville høre.
Av og til kan smigeren bli for åpenbar: I april 2025 slapp OpenAI en oppdatering av GPT-4o som hyllet trivielle innfall som geniale, bekreftet tvilsomme forretningsidéer som strålende, og strøk brukerne såpass mye med hårene at det ble pinlig. OpenAI rullet tilbake oppdateringen og publiserte en forklaring der de innrømmet at de hadde lagt for mye vekt på kortsiktige tilbakemeldinger fra brukerne i treningsprosessen.
Problemet er at det er ikke så lett å måle om et svar er godt, i hvert fall ikke en måte som er skalerbar, rask og billig. Reinforcement learning – å la maskinen prøve seg om og om igjen til ting blir riktig – fungerer så lenge det finnes et klart formulert mål, enten dette er å spille Breakout eller diagnostisere kreft. Det å ikke ha data – spesifikt, data med korrekte svar å trene mot – er den vanligste grunnen til at analyseprosjekter mer eller mindre mislykkes, noe jeg har sett mange ganger i kursene mine.
Problemstillingen kalles «AI alignment» og er ikke enkel. Anthropic har forsøkt seg med noe de kaller «constitutional AI«, som i hovedsak går ut på å la modellen måle sine svar opp mot anerkjente verdier – som FNs menneskerettighetserklæring. Dette er også en teknikk som blir anbefalt av produsentene av modellen selv: Bruk modellen til å være kritisk til hva den selv sier.
Digital Trumpisme
Donald Trump omgir seg med rådgivere som snakker ham etter munnen. Han har klart målbare målsettinger – kortsiktig popularitet og kortsiktig økonomisk gevinst – og ingen som helst sperre på hvor sterkt og åpent de uttrykkes. Siden han kan velge sine medarbeidere, foretrekker han de som skryter av ham heller enn å gi ham motstand, og dermed ender man opp med noksagter som Pam Bondi, fanatikere som Pete Hegseth eller værhaner som JD Vance.
Den katolske kirken hadde tidligere noe som heter «djevelens advokat» – en person som har som oppgave å argumentere kraftig og nesten vitenskapelig mot at en person skal erklæres for helgen. Christopher Hitchens var ganske imponert over de katolske geistlige som besøkte ham da Mor Theresa skulle kanonseres. De lyttet nøye til hans motforestillinger både mot hennes gjerning og de miraklene som skulle gi henne helgenstatus – men trass i gode begrunnelsen ble hun altså helgen. Med andre ord, det hjelper lite å ha institusjonelle motforestillinger, digitale eller ikke, hvis de ikke blir lyttet til.
Og dit kommer vi kanskje. Jeg har hatt en hel del studenter som har kommet til meg med AI-resultater og presentert dem som sine egne. Men jeg har ennå ikke hatt noen som har insistert på at det AI har produsert er sant, og lurer litt på når det skjer og hva jeg skal si da (uten å eksplodere). Den første generasjonen studenter som har hatt tilgang til språkmodeller uteksamineres i disse dager, og de liker ikke AI, delvis fordi de er usikre på om de faktisk kan noe, delvis fordi arbeidsmarkedet for nyutdannede er dårligere enn det har vært på lenge, noe som tilskrives AI.
Men det spørs jo om ikke det behagelige etter hvert blir det sanne og eneste. Slik det har blitt for Trump.
(Og ja, jeg startet dette innlegget med Claude, men endte opp med å skrive neste hele greia selv, siden jeg skriver forblommet nok som det er, uten hjelp fra en entusiastisk språkmodell.)
Hvis du lever av å levere kvalitetsinformasjon til betalingsvillige kunder – hvor redd skal du være for AI-basert konkurranse?
Det altseende monsteret Argos, i følge Gemini.
(En versjon av denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Den gang jeg var student – tidlig 80-tall, intet mindre – fantes ikke sosiale medier, Internett, kommentarfelt eller fake news (i hvert fall ikke fake news produsert av privatpersoner.) Ikke desto mindre følte mange bedriftsledere et behov for å følge med på hva som ble skrevet om dem og bedriften deres. Derfor hadde de gjerne abonnement på Argus (oppkalt etter et altseende monster fra gresk mytologi), en utklippstjeneste der folk var ansatt for å lese gjennom aviser, klippe ut artikler skrevet om hva det nå var man var opptatt av, lime dette på papir og levere eller sende det til kundene.
Om dette høres tregt, dyrt og primitivt ut, så må man huske at alt er relativt: Aviser kom (som oftest) bare en gang om dagen og det fantes bare én TV- og radiokanal med nyheter. Hadde man en faks, fikk man kopier av artikler og annet hver morgen – raskere enn om man pløyde gjennom avisene selv, og med mindre risiko for at man gikk glipp av noe i en eller annen lokalavis.
Men så lenge medieovervåkningen var raskere enn mediet, hadde man jo nogenlunde kontroll.
Digitalisering
Etter hvert ble avisenes arkiver digitalisert: Aftenposten var en pioner her, de hadde digitalt arkiv fra ca. 1983 og var tidlig ute med å lage en nokså primitive søkemotorer mot dette arkivene. Medieovervåkningsbransjen endret seg: Først ved at det ble etablert digitale overvåkningstjenester med tilgang til avisenes interne arkiver, deretter, etter hvert som avisene ble tilgjengelige over Internett fra midten av 90-tallet, mer automatiserte tjenester (basert på søkeord) som brukte det åpne nettet, ikke avisenes eget materiale, som viktigste kilde. (Hvis du er interessert i mer detaljer, se denne artikkelen fra 2008.)
De nye medietjenestene var billigere og raskere enn de eksisterende – de kunne søke på mange søkeord og levere resultatet via epost, uberørt av menneskehender. Tjenestene deres var av dårligere kvalitet enn de manuelle, dyre tjenestene, men de vant frem fordi de fant nye kunder som ikke trengte den samme kvaliteten. Det betød at de ofte fikk falske alarmer, men prisen var lav og hastigheten høy, og over tid ble den nye tjenesten bra nok, samtidig som mer og mer av nyhetsbildet skjedde utenfor papirbaserte og/eller lukkede kanaler.
Og i dag finnes – såvidt jeg vet – ikke manuelle medieovervåkningstjenester lenger. Noen av firmaene er borte, noen av deres etterfølgere lever videre og leverer tjenester på toppen av søkesystemer, som for eksempel systemer for å levere pressemeldinger eller forholde seg til investorer (og noen av dem gjør det bra). Selve søketjenesten er nå, for de flestes vedkommende, automatisert bort til en enkel abonnementstjeneste, programmert inn som en IFTTT-makro, eller ved at man legger inn faste søk i Google eller (mistenker jeg) bruker en AI-agent.
Den dødelige jakten på lønnsomhet
Det er ikke så uvanlig at nye selskaper kommer til etter hvert som teknologien utvikler seg – det skjer naturligvis hele tiden. Gåten ligger i hva som skjer i de gamle selskapene – hvorfor reagerer de ikke på den nye konkurransen og begynner å levere de sammen tjenestene? De burde ha alle fordeler – kunderelasjoner, kunnskaper, og bedre kildetilgang.
Svaret heter naturligvis disrupsjon – eller rettere sagt, disruptive innovasjoner.
Sett at du er et selskap som leverer en informasjonstjeneste av god kvalitet – for eksempel ved at du bruker mennesker som velger ut materiale, mennesker som forstår hva kunden er ute etter og velger ut det som er aktuelt og faktisk handler om ditt selskap og din bransje og ikke noe som tilfeldigvis ligner. Så dukker det opp en konkurrent som leverer noe som er dårligere, men billigere. Dine gode, trofaste kunder bryr seg ikke om dem, men de tar endel av de marginale kundene dine – kunder som synes dine tjenester er bra, men for dyre, og som ikke trenger den kvaliteten du leverer.
Hvordan skal du respondere? Hvis du forsøker å tilby en dårligere tjeneste til billigere pris, utkonkurrerer du deg selv – og selv om du vinner, vil du vinne et marked som er mindre lønnsomt (om enn kanskje større) enn det du er i nå. Selv om det finnes eksempler på selskaper som har gjort dette – Schibsted, for eksempel – hører det til sjeldenhetene.
Mye vanligere er at man forsøker å gjøre produktet sitt enda bedre, for å kunne ta en høyere pris av de kundene man allerede har (og kanskje skaffe seg nye, betalingsvillig kunder). Denne strategien fungerer ofte i praksis, i alle fall hvis markedet har plass, tjenestene ikke er for sammenlignbare, og utviklingen ikke går for fort. Selv om disrupsjon er lett å beskrive, tar ting tid og man mister gjerne fokus.
Et alternativ er å lage en ny løsning – en billigversjon – som utnytter den nye teknologien, samtidig som man trekker på den erfaringen og informasjonstilgangen bedriften allerede har. Vanskeligheten her ligger dels i markedsføring – det er viktig å holde merkevarer fra hverandre – men også i organisasjon. Da Intel på 90-tallet introduserte en billig chip for å utkonkurrere nye leverandører, la man design og produksjon til et sted langt unna eksisterende fabrikker, slik at man fikk fokus på å lage noe billig som var bra nok, heller enn å lage noe som var så bra som mulig.
Det er kulturforskjell på Skoda og Audi, må vite.
I virkeligheten tar ting tid og er ikke så krystallklart som teorien vil ha det til, ganske enkelt.
En versjon av denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
De største feilene i ethvert prosjekt gjør man gjerne de første fem minuttene, fordi man tar forutsetninger og sementerer misforståelser man ikke vet at man har. AI og vibe coding kan kanskje gjøre noe med det.
Bilde konstruert ved denne prompten til Gemini: «please make me a pencil drawing illustrating and executive and a programmer discussing a vibe coding project»
I Comunita-nettverket har vi som regel møter hos en bedrift, der temaet er noe verten ønsker hjelp med. Men i neste møte har vi endret dette, og gjort et lite eksperiment: To bedrifter har gått sammen om å utforske noe nytt, og rapportere erfaringene.
Den ene bedriften har et problem: Bedriften leverer assistanse til kunder, både sine egne og for ulike partnere, hver av dem med ulike avtaler om hva slags ytelse sluttkundene kan forvente.
Den andre bedriften er et softwarehus som leverer ulike typer IT-tjenester, og som står overfor et teknologiskifte (fra tradisjonell til AI-støttet systemutvikling) som kommer til å ha nokså store konsekvenser for både hvordan man utvikler systemer for kunder og hvordan man tar betalt for dem.
Og hva er det vi har utforsket? Jo, vibe coding.
Vibe coding
Innenfor IT kan vi produsere buzz words fort, men vibe coding må være en eller annen rekord: Andrej Karpathy, en av grunnleggerne av OpenAI, introduserte begrepet for 11 måneder siden, og nå er det altså noe som brukes av helt vanlige bedrifter.
Vibe coding betyr at man skriver dataprogrammer ved å fortelle en språkrobot (eller, om du vil språkmodell) hva slags program man vil ha, hvorpå roboten skriver programmet for deg. Tanken er at alle skal kunne programmere – forøvrig noe som har vært et mål for enhver softwareleverandør siden programvare ble en vare: COBOL, av alle ting, var ment som noe ikke-programmerere skulle kunne gjøre.
Uansett: Hva tilfører Vibe coding som man ikke kunne gjøre før?
Det kanskje viktigste momentet er at man kan bruke svært kort tid (i dette tilfellet, en utvikler og ca. 25 timer) på å utvikle en prototype (eller, i alle fall, POC) som er god nok til at man har en omforent oppfatning av hva systemet skal gjøre og hva resultatet, sånn nogenlunde, kommer til å se ut som. Så liten ressursinnsats i en tidlig fase gjør at man slipper å spesifisere systemer før man begynner – utover korte møter – og man slipper å gjøre feil fordi folk forholder seg til en dynamisk beskrivelse i stedet for en mer statisk spesifikasjon.
Et annet aspekt er at diskusjonen om hva man skal gjøre føres mellom folk som er høyt nok oppe i organisasjonen til å ha overblikk – og foreslå løsninger ut over ren systemdesign. For å ta en parallel fra arkitektur: Snøhætta, et arkitektfirma med en rekke enestående bygninger på merittlisten, tar ikke oppdrag fra bedrifter med mindre bedriftsledelsen setter seg med med arkitektene en hel dag, der de klipper og limer og byggeklosser seg frem til hva slags bygg man skal ha. Dette gjør at mange misforståelser blir ryddet av veien tidlig – «å, var det det du mente» – mens de fremdeles er svært billige å korrigere, både hva gjelder penger og støtte mansjetter.
Om å velge riktig nivå
Bildet konstruert ved denne prompten til Gemini: «please make a pencil drawing illustrating the systems development concept of UI, business logic and data access». Presisjonen er ikke påfallende…
Nesten alle systemer som lages, må forholde seg til tre ulike dimensjoner: Grensesnitt, logikk og datastrukturer. (Også kalt «UI, forretningslogikk og dataaksess» hvis man kommer fra tradisjonell IT-utvikling, eller Model-View-Controller hvis man har studert informatikk.) Grensesnittet handler om hvordan systemet skal se ut og hvordan det passer inn i forhold til andre systemer, inkludert det mennesket som skal bruke det. Logikken handler om hvilke regler og rammebetingelser som gjelder. Datastrukturer handler om hvordan dataene er organisert og hvordan man kan komme til dem.
Et vanlig prosjekt ville måttet ha konstruert et grensesnitt (det begynner å bli mer og mer standardisert), legge inn forretningsregler («ikke tilby kunder en tjeneste som ikke er i kontrakten deres») og datatilgang (kanskje ved å konstruere en matrise av ulike tjenester og ulike kontrakter, og slå opp i den omtrent som indeksen til en søkemotor.) Ved å bruke vibe coding får man et kjapt system, der man bruker en variant av RAG til å lese kontraktene og tolke dem. Rent logisk vil dette si at brukergrensesnittet (og muligens grensesnitt mot andre systemer) blir formulert i naturlig språk («hvilke rettigheter har denne kunden»), forretningslogikken – i alle fall i prinsippet – uttrykt ved en «reward function» der språkroboten belønnes for riktige svar, og datatilgangen ordnet ved at språkroboten tolker kontraktene opp mot et multidimensjonelt semantisk koordinatsett.
Hovedfordelen med vibe coding og RAG er hastighet, hovedulempen er, som med så mange ting der språkroboter er involvert, mangelen på presisjon. En annen utfordring er oppdatering – hva skjer om det kommer en ny partner og, med det, en ny kontrakt? Da må man kanskje gjøre hele tolkningsøvelsen om igjen – og kan risikere at systemet ikke er konsistent over tid.
Suksesskriterier
Så langt har vi sett at vibe coding og språkroboter fungerer utmerket i en testfase – kan vi bygge et kjapt system, sjekke ut et konsept kjapt og billig, så vi blir enige om hva vi vil ha. Dette er ikke ulikt 3D-printing, som startet som noe man brukte til å bygge prototyper av bygninger, maskinkomponenter og annet. Etterhvert har 3D-printing blitt en produksjonsteknikk – kan vibe coding og språkroboter gå den samme veien?
Det finnes faktisk en måte å gjøre dette på uten å måtte manuelt sjekke ut den underliggende logikken i systemet – og det involverer god gammeldags statistikk og eksperimentering. Man kan ganske enkelt teste systemet opp mot det man gjør nå – og se om kunderådgivere med dette systemet til hjelp tar bedre beslutninger enn kunderådgivere som opererer alene.
Statistisk sett er dette riktig måte å gjøre det på – samtidig vil jeg tro at en ansvarlig leder ville følt seg nokså nervøs ved oppstart. Vi har en naturlig tendens til å vurdere nye ting ikke opp mot hva man allerede gjør – ofte manuelle prosesser fulle av ikke-innrømte feil – og i stedet insistere på at ethvert nytt system skal være 100% sikkert, feilfritt og etterrettelig.
Som så meget annet mennesker gjør, er ikke dette mulig, og heller ikke ønskelig. Som Daniel Kahneman har skrevet i sin eminente bok Thinking, Fast and Slow: Et menneske som skal gjennomvurdere alle beslutninger i stedet for å være følelsesstyrt, vil aldri klare å ta noen beslutninger. Slikt sett er den effektive omtrentligheten til en språkrobot kanskje en mulig løsning på den backlog’en enhver organisasjon med gamle systemer sliter med.
Og dialogen før man starter vil i alle fall hjelpe med de feilene man gjerne gjør i løpet av de første fem minuttene.
Siden tidenes morgen har store bedrifter slitt med antikverte kjernesystemer, vanskelige å endre og vanskelige å få data ut av. Nå har noen av dem begynt å få orden på det – og hva skjer da?
ChatGPTs versjon av en COBOL-programmerer – de har tydeligvis bare tre fingre per hånd.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Museumsgjenstanden i kjelleren
De grunnleggende datasystemene man bruker i store bedrifter – særlig banker og forsikringsselskaper – ble først laget på sekstitallet. De gjorde helt grunnleggende ting, som å holde orden på hva kundene hadde betalt og fått, og var programmert enten i maskinspråk, Assembler, eller (vanligvis) COBOL. COBOL – designet av ingen ringere enn kontreadmiral Grace Hopper – har vist seg å være forbausende standhaftig: Det er lett å programmere i, men når programmene blir store, er det forbausende vanskelig å endre dem. Etterhvert som ny teknologi har kommet, har de fleste bedrifter utviklet en arkitektur der de har noen svært gamle kjernesystemer – ofte i COBOL – og en mengde andre systemer rundt kjernen – systemer som kommuniserer med kjernesystemet men ikke endrer det.
Dermed ender man opp med et monster i kjelleren – et gammelt system ingen tør røre, delvis fordi det er mangel på folk som kan, dels fordi enhver endring har forgreninger inn i hundrevis, kanskje tusenvis av andre rutiner i egen og andres organisasjon. Siden ingen tør å røre det, bruker man systemene rundt – for dataanalyse, for eksempel, dumper man det som har skjedd i kjernesystemet ut i ulike lagringsløsninger, og gjør analysene derfra.
Fordelen med å trekke data ut fra systemet og gjøre det tilgjengelig er at ulike deler av organisasjonen trenger ulike typer analyser – og har man dataene separat, man man gi dem til folk og la dem gjøre hva de vil. Ulempen er at – med mindre man har en selvdisiplin av en annen verden – de ulike delene av organisasjonen snart skaper sine egne begreper og sine egne bilder av hvordan verden ser ut. Det betyr at uttrykk som «lagerbeholdning» eller «lønnsomhet» har ulike betydninger for ulike deler av organisasjonen, som jo kan gjøre det vanskelig å bli enige om ting. «Single source of truth» er et viktig prinsipp fra informatikk – masterdata skal lagres kun et sted og det skal aldri være tvil om hva som er riktige data. Dette har etterhvert blitt et begrep innen ledelse også, og en viktig motivasjon for å la kjernesystemer og dataanalyse nærme seg hverandre.
Heisenberg i regnskapet
En annen effekt – og viktig motivasjon – for å hente data fra kjernesystemene er oppdatering. Det er en klisje at all regnskapsanalyse handler om å se på fortiden for å predikere fremtiden – ofte sammenlignet med å kjøre bil ved å se i bakspeilet. Jo fersker data, jo bedre styring.
Eller kanskje ikke?
De som har sett Breaking Bad, husker sikkert at hovedpersonen Walter White brukte pseudonymet Heisenberg. Det er ikke tilfeldig – Werner Heisenberg er mannen bak usikkerhetsprinsippet, som sier at (innen kvantemekanikk) er det ikke mulig å presist måle både posisjon og hastighet for en partikkel samtidig. Jo mer presist du måler hvor en partikkel er, jo mindre vet du om hvor fort den beveger seg, og omvendt.
Innen forretningslivet må vi hele tiden ta beslutninger som krever målinger av et eller annet slag – for en bank, for eksempel, må man vurdere kredittverdigheten til en bedrift. Den samme banken vil gjerne også kunne finne ut av hvilke privatkunder som kommer til å flytte lånene sine eller slutte å betale dem – eller mer presist kunne vurdere likviditetsbehov på kort sikt, kanskje fra minutt til minutt.
Når data blir øyeblikkelig tilgjengelig, vil vel dette bli lettere?
Lager er ikke lager
Vel, ting er ikke så enkelt. La oss ta et enkelt begrep, som uttrykket «lager» – er produktet på lager?
Skal du kjøpe noe på IKEA, for eksempel, kan du jo gå på deres webside og se om det ønskede produktet er i butikken – bare for å finne at det ikke er der likevel når du kommer dit. Sjansen for at lagerbeholdningen er feil, er mindre nå enn før, fordi man har fått raskere oppdateringer. For noen år siden ble lagerbeholdningen oppdatert daglig, i en batchprosess. Så koblet man det til POS-systemet i kassen, og dermed ble tallet oppdatert når noen gikk gjennom kassen og betalte for det.
Nå er IKEAs forretningsmodell den at du henter det du skal ha, for så å bruke masse tid på å vandre rundt i en labyrint eller stå i kø mens du fristes med lysestaker, varmelys og marsipan. Den flatpakken du har på handlevognen, er fortsatt – i følge IKEA – på lager, i den forstand at de ikke har solgt den ennå. Men den er ikke på lager for neste kunde, som kommer til en tom hylle – medmindre IKEA monterer strekkodelesere eller vekter på lagerhyllene sine.
Begrepet «lagerbeholdning» er altså ikke bare tidsavhengig, men også forskjellig for forskjellige brukere, og årsaken er ikke slapp datadisiplin, men genuine forskjeller i informasjonsbehov. Dermed blir det til at man må endre beregningsmetode ikke bare ut fra hvilket tidspunkt man ønsker data på (historisk, i sanntid, eller i fremtiden) men også ut fra hvem som spør (kunde, selger, markedsansvarlig, produsent, eller den som er ansvarlig for lagerlokalene.)
Dermed blir noe så enkelt som «lager» et begrep som involverer ikke bare tall, men også relasjoner mellom ulike deler av verdikjeden, der systemene er simuleringer av virkeligheten.
Med andre ord: Jo mer presist man ønsker å måle et begrep, jo mer presist må det defineres.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Om forretningsutvikling for plattformer – og når den går for langt
For noen år siden handlet nesten all forretningsutvikling om å gå fra å selge produkter eller enkelttjenester til å bli en partner med kunden. Denne utviklingen var dels drevet av behovet for å skape differensiering og tilknytning i en verden der standardtjenester blir sammenlignbare og dermed prissensitive, men også muliggjort av teknologi som CRM-systemer.
Neste trinn i utviklingen – som mange bedrifter holder på med nå – er at man forsøker å bli en plattform: En tjeneste som skaper verdi ikke bare ut fra hva kundene kan bruke den til, men også ved at den har elementer av nettverkseffekter, slik at den blir bedre jo flere kunder som bruker den. Disse effekten kan være direkte – kundene kommuniserer gjennom din plattform, eller indirekte, ved at den kunnskapen du får gjennom å ha mange kunder på plattformen gjør at du kan lage tjenester ingen andre kan.
Det å starte en plattform er vanskelig, siden man må ha noe å tilby kundene inntil plattformen – gjerne de andre kundene – er stor nok eller viktig nok til å være en attraksjon i seg selv. Jeg pleier å snakke om at man må ha en «killer» av noe slag – en funksjon eller en gruppe – men det enkleste er nok å allerede ha et nettverk, hvilket er grunnen til at store nettverk som Google eller Facebook kjøper voksende nettverk som YouTube eller Instagram.
Nuvel. Men sett at man klarer å bygge begynnelsen til en plattform ved å sette opp noe, en plattform, som adresserer et todelt marked – hvordan vidererutvikler man den?
Reach and range
Når man ser på verdien av en plattform, er det to dimensjoner som står i sentrum: Reach and range [4] – eller bredde og dybde, som jeg forsøksvis kaller det på norsk.
Bredden er hvem du kan nå gjennom plattformen. Det handler både om hvor mange som bruker den, og hvem brukerne er. Det er lett å se på antall brukere som det sentrale målet her, men vel så viktig kan det være hvem disse brukerne er. Finn.no, for eksempel, har klart flest brukere i Norge, men skal du selge brukte klær, er det Tise som gjelder – de har ikke så like mange brukere som Finn, men hvis det er brukte moteklær du skal selge, har de alle de brukerne som betyr noe.
Dybden handler om hva du kan gjøre på plattformen: Hvilke tjenester som tilbys. Plattformer starter gjerne med å tilby en sentral tjeneste, for deretter å utvide med andre ting etterhvert. Vipps, for eksempel, hadde betaling mellom privatpersoner som eneste tjeneste til å begynne med, men har etterhvert lagt til butikkbetaling, identifisering (innlogging) og muligheten til å fotografere regninger og betale dem.
Utviklingsproblemer
Forretningsutvikling for plattformer har i hovedsak altså to dimensjoner – og man kan utvikle seg i både bredde og dybde: Gjøre plattformen attraktiv for flere kunder (gjerne ved å finne nye kundegrupper som komplementerer de man allerede har), eller å legge til flere og flere tjenester slik at kundene etterhvert kan gjøre alt gjennom plattformen. Slik øker kundenes avhengighet av plattformen – noe som man i alle fall i Internetts begynnelse ble kalt stickiness.)
Begge deler kan være problematisk.
Gratis inntil videre
Et problem man kan få, er at fordi plattformer tjener penger på ulike ting, vil deres jakt på inntekter føre til at de tilbyr gratis det andre tjener penger på. Ta Vipps og Finn, for eksempel: I en periode forsøkte Finn å innføre en batetalingstjeneste kalt SpID (Schibsted Payment ID) som skulle håndtere innlogging og betalinger for bl.a. Aftenposten, Finn.no, VG og endel andre tjenester. Det ble aldri noen suksess, men fikk i alle fall Vipps til å holde sine priser nede og innby til samarbeid med mange andre tilbydere.
Finn har hatt større suksess med å observere hva andre konkurrenter gjør, og så tilby det samme til sine kunder, enten ved å utvikle det selv, eller ved å kjøpe opp eller inngå allianser med oppstartbedrifter som gjør Finn-plattformen bedre.
Selskaper som ikke har hatt suksess her er for eksempel Telenor, som har forsøkt mange ting for å få større profitabilitet ut av sine dyre og omfattende nettverk, bare for å finne at de blir presset tilbake til en kostnadskonkurranse for grunnleggende trafikk. Mens Telenor hadde ressurser, kunne de ha bygget opp en rekke tjenester – alarmsystemer, helseapplikasjoner, videokonferanse, underholdning – men de hadde ikke apetitten for så store investeringer utenfor kjernevirksomheten. De hadde også brent seg på endel investeringer innen underholdning, der det faktum at Telenor var store i Norge ikke hadde noen betydning for de store underholdningsprodusentene, som forhandler priser for innhold over hele verden. Telenor er i dag – i likhet med de fleste telekommunikasjonselskaper – en skygge av seg selv, redusert til å levere basistjenester fra en åttendedel av sitt formidable hovedkvarter på Fornebu.
Kort sagt handler enshittification om at plattformtilbydere, i et forsøk på å øke og opprettholde sin profitt, lokker til seg nye brukergrupper ved å selge de brukergruppene de allerede har, for så å gjenta prosessen når den nyeste brukergruppen har gjort seg avhengig av plattformen.
Here is how platforms die: First, they are good to their users; then they abuse their users to make things better for their business customers; finally, they abuse those business customers to claw back all the value for themselves. Then, they die.
Facebook er et typisk eksempel: Til å begynne med et sted du gikk til for å snakke med venner og forbindelser, som nå er blitt et sammensurium av innhold og annonser du ikke har vil ha, til fortrengelse for det du egentlig vil ha, siden det ikke betaler.
Balanse i alt
Markedsføring handler om å skape og beholde kunder. Problemet for plattformer er at det er ikke alltid klart hvem kundene er, siden man ofte står overfor tosidige markeder [3,5] (selgere og kjøpere, for eksempel) der den ene siden genererer det meste – ofte hele – inntekten. Dermed blir kan det bli vanskelig, særlig i nedgangstider, å opprettholde interessene til den kundegruppen som ikke generer inntekter over tid. Denne balansen mellom langsiktig tenkning og kortsiktig profitt er imidlertid ikke noe nytt for forretningsutvikling generelt – hvor mye kvalitet man skal legge i produkt og kundeservice, for eksempel, har alltid vært der som en balanse man må forholde seg til.
Så, for all del, øk bredde og dybde i det du gjør med plattformen din, men ikke glem årsaken til at kundene kom dit til å begynne med – for å få utført en basisfunksjon, og, til en stor grad, å forholde seg til hverandre.
[5] G. Parker and M. Van Alstyne, “Two-Sided Network Effects: A Theory of Information Product Design,” Management Science, vol. 10, pp. 1494–1504, 2005.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Hvordan selge et teknisk produkt eller tjeneste til firma som hverken vet hva de vil ha eller om det de kjøper er bra? Hva kjøper kundene egentlig når de hyrer inn et IT-firma?
Clayton Christensens – mannen bak begrepet disruptive innovasjoner – hadde også begrepet «Job to Be Done». Ideen går ut på at kunder ikke kjøper produkter eller tjenester i seg selv, men heller «ansetter» disse produktene for å løse et bestemt problem eller oppfylle et spesifikt behov («gjøre en jobb»). Det opprinnelige eksemplet gikk ut på å finne ut hvorfor kunder kjøpte visse produkter hos McDonald’s – ikke fordi de hadde lyst på akkurat det produktet (som passet ganske dårlig), men fordi de søkte å fylle et behov.
Det derre slitsomme kundeperspektivet…
Når man designer ting ut fra kundenes behov, hender det at ting ender opp annerledes enn man først hadde tenkt. Hvis du ser på web- eller mobilsidene til Aftenposten og VG, ser de svært forskjellige ut (selv om de ligner mye mer på hverandre nå enn de gjorde for noen år siden.) En av årsakene er at kundene bruker avisene forskjellig: Aftenpostens lesere er opptatt av å lese nyheter, VGs lesere i større grad av å finne noe som skal fylle et ledig øyeblikk. Begge sider er utviklet gjennom eksperimentering – VG begynte med dette allerede på tidlig 2000-tall – men henvender seg til publikum som har «ansatt avisene» til å gjøre forskjellige ting for seg.
Begge aviser fungerer – men Aftenpostens sider har et mer helhetlig design og vil nok vinne flere designpriser.
For å lykkes må bedrifter derfor forstå hva kundene virkelig prøver å oppnå – altså selve jobben kundene ønsker løst – og deretter utvikle løsninger som gjør denne jobben enklere, raskere eller bedre enn alternativene. Dette må gjøres ut fra kundenes behov, ikke ut fra hva man ønsker å levere. (Det finnes naturligvis unntak – Steve Jobs var aldri opptatt av hva kundene sa – men de er få og involverer dramatisk innovasjon).
Dette er ofte et perspektiv som forsvinner for mange bedrifter – de er ofte fokusert på produktene og tjenestene sine, og dersom kundene ikke er fornøyd, forsøker de – i stedet for å spørre hva kundene ønsker å gjøre – å gjøre produktene sine bedre. Produktene blir bedre, men disse forbaskede kundene ser ikke ut til å sette pris på ledende kvalitet og smarte innovasjoner – i stedet kjøper de noe halvdårlig fra sine vanlige leverandører eller noe billig og dårlig som ser ut som det gjør jobben.
IT-bransjen er full av firma som leverer bedre produkter enn det som er bransjestandard, har størst markedsandel, eller mest kjente merkevare. Det irriterer teknologene helt grenseløst. De vil jo helst utvikle produkter for folk som dem selv, og selge dem til andre teknologer.
«Nerd to nerd marketing», som en venn av meg kaller det.
Den irriterende sikkerheten
Ta IT-sikkerhet, bare for å plukke en typisk teknisk tjeneste: Noe som mange bedrifter vil ha, uten nødvendigvis å ha nødvendig bestillerkompetanse til å spesifisere presist ut fra hva leverandørene kan tilby. Hva er det egentlig kundene ansetter et IT-sikkerhetsselskap for å gjøre? Det handler i hver fall ikke om tekniske vurderinger, sårbarhetsrapporter eller sikkerhetsrevisjoner.
Jeg tror kunder av sikkerhetsfirma kjøper seg noe mer udefinert – som
trygghet – at kritiske forretningssystemer er godt sikret mot trusler og at deres data, omdømme og drift dermed ikke blir kompromittert
validering – en ekstern, objektiv og troverdig bekreftelse på egne sikkerhetstiltak, dokumentert samsvar med regelverk, som også kan brukes som dokumentasjon i tilfelle noe skjer og skyld skal fordeles
proaktiv innsikt – avdekking av potensielle sårbarheter før uvedkommende gjør det, som gir virksomheten muligheten til å iverksette tiltak før det oppstår skade. Man kjøper forutsigbarhet, tidlig varsling og praktiske råd om hvordan man kan forhindre fremtidige sikkerhetsbrudd
Charles Revson sa engang: «I fabrikken lager vi parfyme, i butikken selger vi håp». IT-sikkerhetsselskap produserer sikkerhet, men god nattesøvn.
Hvordan skal man få en i utgangspunkt nerdete bedrift til å skjønne det?
Hva med en stram kontrakt?
Det er i hovedsak to måter man kan løse dette problemet på: Man kan velge å la spesialistene bestemme, og gjøre det klart for kundene akkurat hva man leverer og hvor god man er på det. Det vil gjøre nerdene – både de man har selv og de som jobber for kundene – fornøyd, gir få organisatoriske utfordringer, og tillater at man satser knallhardt på å gjøre produktet eller tjenesten bedre enn noen andre, om nødvendig i verden.
Problemer ligger imidlertid i vekst og konkurranse: Etterhvert som markedet blir mer modent, kommer det flere løsninger (gjerne ved kopiering) som er minst like bra. Det er en grunn til at store teknologifirma, som Microsoft og Google, etterhvert overtar mer og mer. En produktfokusstrategi bør ende med en exit: At selskapet selges til en større, mindre differensiert leverandør, og blir del av en mer standardisert produktportefølje.
Problemet overfor kundene oppstår når en hendelse inntreffer, og de spør hvordan det kunne skje? Man kan nok vise til kontrakter og ulike ansvarsfraskrivelser og ha rett på sitt hvis, men inntrykket fester seg likevel: Her har det blitt lovet gull og grønne skoger, og så viser det seg at man har levert drill og ikke hull, for å sitere et annet kjent eksempel. Enhver som har opplevd kluss med et regnskap kjenner til revisorer som fraskriver seg ansvar – de har riktignok skrevet under på at regnskapet er godkjent, men tar de noe ansvar for konsekvensene? Nei, og det kan de ikke, men likefullt ender regnskapsmessige uregelmessigheter ofte med revisorbytte fra kundens side.
Å invitere kunden inn og omslutte problemet
Den motsatte strategien ligger i å la kundeperspektivet forme organisasjonen, skape vekst ved å kunne selge til kunder med færre nerder (men kanskje større budsjetter), og skape langsiktige konkurransefortrinn enten ved at kundene blir avhengige av det man selger eller at man finner noe ved produktet eller tjenesten som blir bedre jo større andel av markedet man har (ikke så unaturlig om man selger IT-sikkerhet, for eksempel). Har man mange kunder, kan man finne sårbarheter ved en kunde og tette dem hos alle – jo flere kunder man har, jo bedre er man i stand til å tette hull. Dette fenomenet kalles nettverkseksternaliteter, og er konkurransemessig gull i en verden der teknologien gjør spissprodukter til brød og smør på rekordtid.
Skal man få til det, må kundene få reell makt i bedriften, enten ved at man utvikler nye tjenester ut fra hva de spesifiserer heller enn ut fra hva man ønsker å levere, eller ved at man rett og slett oppretter kunderepresentanter (key account managers, customer success teams, etc.) med mandat og ressurser til å utfordre produktperspektivet. Dette fungerer mest hvis man klarer å skape en balanse mellom salgs- og utviklingssiden – og er et for komplisert tema til å ta opp i denne bloggposten (men bare vent, noe kommer snart.)
Vekst og overtakelse
Kunnskapsbedrifter som vokser, velger gjerne denne veien – og ender etterhvert opp med ikke bare å tilby et bredt spekter av tjenester, men til slutt med å omslutte og ta ansvar for hele problemet, på vegne av kunden. Den nokså nylige veksten for de store kunnskapsbedriftene – Accenture, for eksempel, har firedoblet antall ansatte de siste 15 årene – skyldes i hovedsak at man har overtatt funksjoner fra kundene, ofte gjennom å flytte ting til land med lavere kostnader og levere gjennom standardiserte kontrakter.
Da er det ikke mye nerd-to-nerd marketing igjen, men desto flere nerder ansatt…
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Enhver bedrift med respekt for seg selv har en strategi – gjerne i form av et dokument, elektronisk eller ikke, med i alle fall en versjon av følgende punkter:
Misjon: Hva selskapet skal gjøre
Visjon: Hvor selskapet skal gå i fremtiden
Strategiske hovedmål: Konkretisering av visjonen
Strategiske hovedtiltak: Konkretisering av hvordan man skal oppnå målene
Strategiske delmål
Strategiske deltiltak
…og så videre
De fleste strategier av denne sorten, hvis de finnes, ligger på en intern webside (ikke lenger i en skrivebordsskuff i disse digitale tider) og har svært lite med bedriftens daglige virke å gjøre. Om man spør medarbeiderne om bedriftens strategi – i hvert fall om den har kommet opp i noen som helst størrelse – har de i beste fall en diffus mening om endringer i omgivelsene man etterhvert skal forholde seg til.
Hvorfor er det slik?
Årsakene kan være mange, men jeg tror de vanligste er: Strategiene er ikke reelle valg, de er for vage, og det settes ikke ressurser inn bak gjennomføringen.
Strategi som valg
Forretningsstrategiens far, Michael Porter (1996), refererte alltid til strategi som valg – at man tar et reellt valg mellom ulike mål og fremgangsmåter. Skal valg være reelle, må de innebære at man har valgt noe bort, og det man velger bort er noe man kunne ha gjort.
Jeg pleier å fortelle mine studenter om Claude Shannon og hans tese om at et utsagns informasjonsinnhold er omvendt proporsjonalt med sannsynligheten for å motta det. Med andre ord: Dersom bedriftens strategi er å vokse og tjene penger, har man valgt bort å krympe og tape penger. Ikke mye til valg, ikke sant?
Skal man vurdere hvor god en strategi er, kan man jo stille seg spørsmålet: Hva er det strategien sier vi ikke skal gjøre, eller hva vi skal gjøre mindre av? Hvis vi skal prioritere alt, prioriterer vi ingenting, og da har vi ikke tatt noen valg, strategiske eller ikke.
Strategi som oppskrift
En strategi skal sette en retning: Hva skal bedriften oppnå, og hvordan skal den gjøre det? Det kan en strategi inneholde, men likevel være så vag at den ikke gir noen rammer for dem som faktisk skal gjennomføre den.
Skal man nå et mål, må man også ha en formening om hvordan man skal komme dit: Skal man ansette flere selgere, for eksempel, gjøre endringer i produkter eller tjenester for å oppnå noe bestemt, eller skal man gå etter et nytt marked?
Det er fristende å trekke en parallell til sport: En trener som sier at hans eller hennes strategi er å vinne et mesterskap i år, er ikke troverdig uten at det følges opp med hvordan – gjerne i form av hva som er sterke og svake sider med eget lag og hva han eller hun har tenkt å gjøre med det.
For mange virksomheter innen nærlingsliv og offentlighet ser det imidlertid ut til at det holder med å si at strategien er at man skal ha fornøyde kunder, god lønnsomhet og motiverte ansatte. Hvordan man skal få til dette, derimot, glimrer med sitt fravær, ikke bare i den delen av strategien som ender opp på websiden, men også i det som kommuniseres internt.
Et godt styre og/eller krevende eiere vil kunne holde ledelsen i ørene her, og det er deres jobb å kreve at ledelsen vet hvordan, ikke bare hvor.
Strategi som prioritering
En strategi er ikke en strategi hvis den ikke følges opp med ressurser til å sette den ut i livet. Ressurser kan være penger, produksjonskapasitet, personale, eksperter, tilgang til kunder, og ikke minst myndighet til å sette ting ut i livet.
Det er viktig å merke seg at ressurser er relative og betyr noe over tid. Det som er en strategisk satsing for en liten bedrift kan være lommerusk for et globalt konsern. Jeg har sett en hel del satsinger fra store selskaper omtales som strategiske fra utsiden, men verken penger eller ledelsesoppmerksomhet tilsier at så er tilfelle.
Det er heller ikke strategisk ressursallokering å sette inn penger for så å endre kurs like etterpå – som man ofte ser hvis strategien er basert på moteretninger. Da er det bedre å klassifisere noe ressursbruk som eksperimenterende, sette korte tidsfrister, og så gå videre dersom det kommer noe ut av dem.
«Strategisk» bør brukes med forsiktighet
Ordet «strategisk» er lett å gripe til – og innenfor kyniske konsulentmiljøer sies det ofte at det betyr «noe som jeg ikke kan regne hjem men vil gjøre likevel.»
Men «strategisk» bør brukes med forsiktighet. Det skal noe til for å omtale noe som strategisk – og det er ikke sikkert at det som er strategisk for en virksomhet er det for en annen.
Av og til kan det bli helt meningsløst.
For noen år siden var jeg tilstede på et stort internt arrangement i en av Norges største bedrifter. Anledningen var at man hadde bestemt seg for å standardisere all programvare i bedriften til Microsoft. Steve Ballmer, Microsofts den gang administrerende direktør, dukket opp via videokonferanse og leste opp et manuskript om hvor glad han var for at bedriften og Microsoft skulle begynne et strategisk samarbeid, men for meg var det nokså klart at han ikke helt visste hvilken bedrift han snakket til eller hvor i verden den holdt til. Episoden fikk min meget erfarne konsulentsjef til å bemerke at han kjøpte alt sitt undertøy hos Marks & Spencer, uten at han ville kalle det et strategisk samarbeid av den grunn.
Så, neste gang du snakker om din strategi eller at noe er strategisk: Representerer strategien et reellt valg, er den spesifikk nok til at organisasjonen vet hva den skal gjøre, og har du allokert nok ressurser til at den kan gjennomføres?
Hvis ikke, skal du kanskje finne et annet ord å bruke…
Referanser:
Porter, M. E. (1996). «What Is Strategy?» Harvard Business Review 74(6): 61-78.
Oppdatering 21. februar 2025: Utrolig hvordan perspektivet på en person kan endre seg i løpet av noen måneder… En monoman fokus på detaljer med et løst forhold til konsekvenser er i alle fall ingen god metode når man ikke er begrenset av fysiske lover.
Jeg er nesten ferdig med Walter Isaacsons biografi om Elon Musk, og det er interessant lesning. Den er detaljert, spesielt om utviklingen frem til boken ble ferdig (publisert juli 2024, så den er ikke gammel). Isaacson har fotfulgt Musk i to år, hatt tett kontakt med Musk, hans familie og venner, og detaljerer og dokumenterer bra.
Elon Musk er svært interessant som person. Han er verdens rikeste mann, og har vært involvert i en rekke selskaper – PayPal, SpaceX, Tesla, The Boring Company, Neurolink og Twitter, sånn til å begynne med, har en masse barn og er det amerikanerne kaller en «outsized personality». Han har Aspergers (en diagnose jeg har blitt fortalt ikke lenger finnes, erstattet med et eller annet på autismespekteret), noe som gir seg utslag i en nærmest manisk fokus på detaljer, enorm arbeidskapasitet, begrensede sosiale evner, og en impulsivitet som til tider kan skaffe ham problemer, som når han er litt for kjapp med Twitter-meldinger eller kaster seg ut i «surges» for å løse kriser som ganske ofte er selvkonstruerte.
Han er tydeligvis ikke lett å jobbe for, og biografien har blitt kritisert for å skape et heltebilde av Musk, selv om mange av hans eks- og nåværende ansatte og familiemedlemmer kommer til orde her og der. Men det er vanskelig å argumentere mot suksess, og Musk har skapt sin formue selv, ofte basert på svært langsiktige strategier. Hans impulsive kjøp av Twitter, for eksempel, er ikke noe annet enn en fortsettelse av en strategi han opprinnelig la for Paypal, men ikke fikk gjennomført, blandt annet fordi de andre investorene var uenige med ham (og fordi tiden kanskje ikke var moden). Strategi handler som regel om gjennomføringsevne og fokus.
Algoritmen
En ting Isaacson dokumenterer svært godt, er Musks arbeidsmetode, som han kaller «algoritmen», og som han har brukt spesielt innenfor industriell design og produksjon, som for eksempel Tesla og særlig SpaceX. Den består av fem steg:
Sett spørsmålstegn ved alle pålegg. For elementer av et produkt eller en prosess, spør «hvorfor er det slik?». Hvis svaret er «fordi markedsavdelingen krever det», spør «hvem i markedsavdelingen har spesifisert det, og hvorfor». I Musks organisasjoner er alle krav til et produkt eller en prosess knyttet til en person og en spesifikk årsak – helst forankret i fysiske lover.
Eliminer alt du kan. Hvis ikke en del av en prosess eller et produkt er absolutt nødvendig, fjern den. Det vil ofte føre til at man fjerner ting som viser seg å være nødvendig, men som Musk sier: «Hvis vi ikke ender opp med å gjenopprette 5-10% av de tingene vi tok vekk, har vi ikke tatt vekk nok.»
Forenkle og optimaliser. Når du har fjernet alle unødvendige steg, sett i gang og forenkle og optimalisere de delene av prosessen eller produktet som er igjen. Kan det gjøres enklere? Kan man bruke enklere materialer? Og viktigst av alt – kan man, etter å ha forsøkt å forenkle, kanskje fjerne hele greia?
Få opp farten. Når man har gjort de første tre stegene, er tiden inne for å få opp farten – rett og slett gjøre ting raskere.
Automatiser. Til slutt, når man har eliminert, optimalisert, og skrudd på gassen, er det tid for å automatisere – og først da.
Her på berget…
Jeg kjenner meg godt igjen i denne prosessen – som jeg har skrevet og sagt mange ganger før: Digitalisering er forenkling. I Norge har vi ikke så hard konkurranse og et deilig oljefond å lene oss på, og nå begynner det virkelig å slå ut i statistikkene. Kanskje det er på tide å begynne å bruke denne metoden på alle rare ting vi gjør her til lands? Elon Musk har nå fått en posisjon som sjef for et regjeringsorgan som skal forenkle og optimalisere USAs føderale lover og byråkratier. Det kan bli en interessant øvelse – sannsynligvis et kulturkrasj av dimensjoner, siden Elon Musk ikke kan sparke folk som ikke jobber 150% kontinuerlig – men i intervjuer har han allerede sagt at det er på tide forenkle lover og regler ned til et punkt hvor de kan leses og forstås av folk flest. Det er heller ingen grunn til å ha en masse støtteordninger – inkludert for elbiler og ladestasjoner – og heller la markeder og næringsliv tilpasse seg til det folk vil ha, innenfor rammer som er fremtidsrettet.
Det skal bli en interessant øvelse. Musk har vunnet frem med gjenbrukbare raketter og elektriske biler, ting som etablerte aktører ikke har klart å gjøre noe med. Han er genuint opptatt av de store spørsmålene – global oppvarming, AI-sikkerhet, menneskehetens fremtid.
Det er absolutt ikke noe galt med målsetningen. Så er det bare et spørsmål om å finne en algoritme som tar oss dit.
Nå har jeg begynt å glede meg til det morsomste jeg gjør på BI: Undervise kurset Strategisk forretningsutvikling og innovasjon sammen med Ragnvald Sannes. Dette har vi gjort i mange år, og synes det er morsomt fordi vi møter mange spennende mennesker som er opptatt av innovasjon. Som vi pleier å si: Våre studenter rekrutteres fra de folkene som ikke klarer å la ting være som de er!
En interessant side av kurset – både for oss og for studentene – er at det er todelt: Dels har vi vanlig faglig innhold – forelesninger, gjesteforelesere, case-diskusjoner og ikke minst en studietur til Sophia Antipolis i Provence i samarbeid med Accenture Technology Labs. En annen – og minst like viktig – del er at kurset er en arena for konkrete utviklingsprosjekter. Deltakerne jobber i team og løser problemer de har med seg fra virksomhetene. Dette gjennomføres i en veiledet prosess fra idéarbeid i første samling til løsningsforslag ved kursets avslutning. En hel del bedrifter har gjennom årene utviklet mye spennende gjennom dette kurset – og studentene setter pris på at siden prosessen starter med en gang og man jobber jevnt og trutt gjennom hele kurset. Da slipper man en panikkfase på slutten for å bli ferdig med oppgaven.
Også i år (2023/24) har Ragnvald og jeg veiledet en rekke oppgaver – og siden oppgavene er reelle og nesten alle er konfidensielle, må jeg omtale dem i nokså runde ordelag. Her er årets liste:
en gruppe har jobbet med en byggvarehuskjede som ønsker å lage en AI-assistert chatbot som kan hjelpe kundene lage enkle prosjektplaner egne oppussingsprosjekter
en gruppe har hjulpet en stor bank som ønsker å lage en selvbetjeningsløsning for leasing av ulike aktiva for sine bedriftskunder
en gruppe har jobbet med et forslag til en radikal forenkling av velferdsmodellen i NAV og har testet en prototyp. Målet er å skape mer trygghet og forutsigbarhet hos mottagere av velferdsytelser samt redusere tid brukt på saksbehandling og vedtaksfatting for veilederne. Det vil gi enklere og raskere utbetalinger til de som er i behov av velferdsytelser
en gruppe har jobbet med et prosjekt for Forsvaret for å styrke gjennomføringen av lagførerutdanningen i regi av Heimevernet.
en gruppe har jobbet med et prosjekt der en større kommune ønsker å bli i stand til å møte demografiutfordringen, det vil si at antallet netto brukere av kommunale tjenester øker (vesentlig som et resultat av lengre levealder) mens den relative andelen skattebetalere synker
en gruppe har jobbet med å lage en løsning for koordinering av LIS (Leger i spesialisering)-utdanning, som involverer praksis og undervisning av og med et stort antall aktører
et gruppe har jobbet med et programvareselskap har utviklet et app som kombinerer bruk av kamera, ulike sensorer og kommunikasjon for at eldre skal kunne bo trygt hjemme lenger
en gruppe har jobbet med et pressekonsern som ønsker å kombinere, koordinere og personlig tilpasse sine digitale tilbud på tvers av organisatoriske og tematiske skillelinjer
en gruppe (hvis medlemmer har bakgrunn i boligmegling og -finansiering) har jobbet med en prosjekt for å skape en mer oversiktlig, trygg og innsiktsfull bolighandelsprosess
en gruppe har analysert markedet for ladeprodukter for elektriske båter og laget forslag til ulike løsninger slik at det skal bli like lett å lade elektriske båter som elektriske biler
en gruppe har jobbet med en høyskole som ønsker å skape en enhetlig plattform som gjør det mulig å velge kurs på tvers av ulike markedssegmenter
en gruppe har jobbet med å utvikle en tjeneste som kan tilby praktisk og profesjonell sykkelservice – særlig for elsykler – på den tid og det sted som passer sykkeleieren best
Disse gruppene setter vi sammen tidlig i kurset – typisk består de av en person fra det firma eller den organisasjonen som ønsker å utvikle noe nytt, og så av folk fra andre steder som synes denne oppgaven er interessant.
Vi har jo holdt på en stund, så her er lenker til tidligere innlegg og oppgaver:
ChatGPTs svar på «make an image that illustrates how AI can make managers more productive». Hvorfor en digital leder trenger skrivebordsskuffer er noe jeg ikke helt forstår, men et eller annet sted skal man jo ha matpakken…
(Denne bloggposten ble først publisert på bloggen til Comunita, et ledernettverk jeg driver sammen med Haakon Gellein. I neste møte skal vi ta opp dette temaet – og derfor har jeg skrevet dette blogginnlegget som en forberedelse.Vi tar opp nye medlemmer etter vurdering – ta kontakt om du ønsker mer informasjon.)
Her forleden snakket jeg med en leder i et stort, internasjonalt selskap. Han var ansvarlig for en intern leverandør av IT- og administrative tjenester, og hadde nettopp fått ordre fra toppledelsen om å doble tjenesteproduksjonen uten å øke antall ansatte. Det er jo ikke så enkelt, men toppledelsen mente det burde gå greit for «nå har vi AI».
Og det fikk meg til å lure på hvordan vi egentlig skal få noe produktivitet ut av AI – særlig generativ AI, også kalt store språkmodeller – i et tradisjonelt selskap?
Produktivitet og informasjonsteknologi
Produktivitet er definert som hvor mye resultat vi får av en innsats – men som regel betyr det hvor mange ansatte vi trenger for å få gjort noe. Når det gjelder fysisk produksjon, er det ikke så vanskelig å måle produktivitet: Flere produkter produsert, gitt samme innsats og kvalitet, er økt produktivitet.
Og det er jo greit nok – få inn en maskin som gjør jobben raskere, og hvis økningen i hastighet er verdt prisen på maskinen, vel, der har du konklusjonen.
Problemet oppstår når effekten av produktiviteten oppstår et annet sted, eller ikke som et direkte resultat av maskinen.
I 1998 ble jeg involvert i en diskusjon om produktivitet og datamaskiner. En forsker hadde skrevet et innlegg i Aftenposten om at PCer ikke økte produktiviteten noe særlig. Han viste til forskning der man hadde tatt tiden på hvor fort det gikk å skrive et dokument på en skrivemaskin og på et PC-tastatur, og konkluderte med at det gikk bare ca. 10% raskere å skrive på PCen, så det var liten vits i å investere i dem. Jeg skrev et motinnlegg der jeg påpekte at når jeg skrev mitt innlegg, sendte jeg det til Aftenposten som e-post, og at de kunne ta det rett inn i avisen uten å måtte skrive det om igjen. Det var en voldsom produktivitetsgevinst for Aftenposten – i hvert fall hvis de kunne få gjort noe med typografenes fagforening, som insisterte på å skrive alt om igjen.
Eksemplet er banalt, men viser to viktige ting: For det første oppstår produktivitet av informasjonsteknologi gjerne andre steder enn der teknologien er synlig. Da blir det vanskelig å se og måle effekten. For det andre, og mye viktigere: For virkelig å få effekt av ny teknologi, må man reorganisere det man driver med rundt teknologien. Det er enda vanskeligere å måle, og er en av årsakene til at nye organisasjoner, som ikke har en gammel måte å gjøre ting på, ofte drar nytte av teknologien lenge før de gamle.
Produktivitetsparadokset
I 1987 skrev den kjente økonomen Robert Solow at «Vi finner datamaskinene overalt, bortsett fra i produktivitetsstatistikken.» Han pekte på store investeringer i datamaskiner på 1970- og 1980-tallet, uten at de store kostnadsbesparelsene hadde kommet. I debatten som fulgte, ble mange årsaker foreslått, fra forsinkelser forårsaket av læring og omorganisering rundt den nye teknologien til kulturelle forklaringer («ledere ønsker å administrere mange ansatte» eller vanskeligheter med å måle kostnader og fordeler.
I løpet av 90-tallet skjøt imidlertid produktiviteten fart – banker, for eksempel, fant ut hvordan de kunne redusere antall ansatte ved å flytte kundene over fra filialer til digitale kanaler. Internett og etter hvert mobiltelefoni gjorde at mange «call centers» kunne legges ned. Innen offentlig forvaltning fikk vi digitale skattemeldinger og hjemmesider med informasjon og digitale søknadsskjema. Effektene kommer, men vi glemmer at vi har dem: I høydigitale samfunn, som Norge, lurer du noen ganger på hvor produktivitetseffekten av IT ble av, helt til du innser at du svært sjelden står i kø for noen form for informasjonsbasert transaksjon, som å kjøpe en billett eller levere et skjema.
Men: Økt produktivitet betyr ikke nødvendigvis økt lønnsomhet. En rekke studier ledet av Erik Brynjolfsson fra MIT dokumenterte at økt produktivitet nok kunne føre til endringer innen en bransje (et firma som var tidlig ute kunne utkonkurrere andre firma), men lønnsomheten konkurreres bort og havner hos forbrukeren (Brynjolfsson og Hitt 2000). Som en bekjent av meg pleide å si: I næringslivet må vi hvert år bli mer effektive, jobbe hardere og smartere, og belønningen er at neste år får vi lov til å gjøre det en gang til.
Med mindre vi endrer hvordan vi er organisert.
Dette at eksisterende selskaper sliter med nye organisasjonsformer, gjør at i mange tilfeller er det nye selskaper, organisert med teknologien som basis, som definerer nye normaler. Automattic, selskapet bak WordPress-plattformen som rundt 43 % av alle nettsteder er programmert i, har (ifølge deres egen nettside) kun 1 994 ansatte i 94 land. I Norge har vi sett det der f.eks. Skandiabanken kom inn og flerdoblet antall kunder per ansatt ved kun å være en Internettbank. Skandiabanken er nå overtatt av Norges største bank, DNB – men det er en bank som nå er kun en tredjedel av størrelsen av hva den var da Skandiabanken ble lansert, og som har krympet ved å kopiere mye av det Skandiabanken gjorde.
AI og produktivitet: Individuelle, organisatoriske og samfunnsmessige effekter
For enkeltpersoner kan GenAI være utrolig produktivt. Nylig satt jeg med en programmerer som ønsket å teste om et nettsted kunne bygge inn et Google-dokument. Det viste seg at det ikke gik, men det kunne bygge inn HTTP (hypertekst). Så han tok Google Doc-lenken, hoppet over til ChatGPT, skrev «legg denne i en iFrame». ChatGPT produserte pliktoppfyllende den nødvendige koden i løpet av noen sekunder. Han kopierte koden, limte den inn – og det fungerte.
Dette er utvilsomt en produktivitetsøkning for denne programmereren, som ellers ville ha måttet huske og skrive koden for en iFrame-omslag (eller i det minste vite hvor den skulle finne den.) Dette eksemplet viser også hva ChatGPT er flott for: Reprodusere, med rimelig kontekstualisering, varianter av det som har blitt produsert før. Selv har jeg brukt det til å generere det første utkastet til kontrakter, emnebeskrivelser og, ja, elementer av essays (ikke dette). ChatGPT og dets konkurrenter kan hjelpe deg med å generere tekst, bilder, presentasjoner og annet materiale, så lenge originalitet ikke er nødvendig eller verdsatt – og kan gi nokså store produktivitetsgevinster på individnivå.
På organisasjonsnivå er det litt annerledes. Fra store bedrifter i USA har man sett at opplæring og kvalitet på kundesentre er forbedret ved bruk av generativ AI, men resultatene er ikke voldsomt høye foreløpig (Brynjolfsson et al 2023). En leder jeg snakket med fortalte meg at hovedeffekten av ChatGPT han hadde sett så langt var at e-poster hadde blitt mye høfligere. Men veltalenhet er ikke informasjonsdybde, og jeg tviler på om raskere generering av tekst og bilder vil føre til produktivitetsgevinster i organisasjonen, siden de som skal motta informasjonen også må øke sin produktivitet.
Mine studenter kan nå produsere svada i et imponerende tempo og med en kompleksitet verdig en fransk postmodernist. Men min evne (og vilje) til å lese og forstå det som kommer er ikke økt. På den annen side kan jo jeg bruke ChatGPT til å lese og karaktersette – et eksempel på at studentene later som de skriver og jeg later som jeg leser.
Om dette er en situasjon vi egentlig vil ha, er jo noe vi bør diskutere. Er dette et tegn på tidens forfall, eller begynnelsen på en ny kommunikasjonsform, der min AI snakker til din AI og avtaler ting på våre vegne? Kanskje jeg endelig kan få tilbake den sekretæren jeg hadde på nittitallet…
En parallell til søketeknologi?
For noen år siden deltok jeg i et forskningsprosjekt som studerte bruken og effektene av søketeknologi. En av konklusjonene (Andersen 2012) var at søkemotorer fungerte utmerket i generelle Internett-søk (dvs. Google, Baidu og Bing), ganske bra på kunderettede nettsider (dvs. aviser, Amazon, teknologiselskaper som Dell), men nokså dårlig for interne søk. Mens teknologien var den samme, var både hvordan den ble brukt (dvs. hva folk lette etter) og hvordan resultatene ble prioritert forskjellig. I en generell søkemotor søker folk over millioner av nettsider. Vanligvis vil man ha det samme som andre – så Google viser de mest populære resultatene. For et kommersielt nettsted søker folk etter spesifikke ting (som et fysisk produkt, et svar på vanlige spørsmål eller en nyhetsartikkel), og generelt vil de enten ha det mest populære valget eller det selskapet ønsker å vise dem – f.eks. varer som er på lager og lønnsomme.
For bedriftssøk, der du søker på tvers av enten all informasjonen din bedrift har, eller spesifikke samlinger av informasjon (for eksempel en lovdatabase eller et sett med interne instruksjoner), har du problemer: For det første har du ikke nok data til å virkelig få maskinlæringsmodellene til høy presisjon, fordi selv store selskaper vil ha begrensede samlinger av informasjon sammenlignet med hele Internett. For det andre er målfunksjonen til søket – det vil si hva du leter etter – normalt ikke den mest populære varen, men noe mye mer spesifikt. I en bedriftssetting er det mye mer sannsynlig at du søker etter et spesifikt dokument, ofte bare relevant for deg eller en liten arbeidsgruppe, og som sådan vil du måtte stole mer på kategorisering (Andersen 2006), i form av kuraterte data og hierarkiske, menneskelig navigerbare datastrukturer.
For meg er det i hvert fall fullt mulig at produktivitetsgevinstene fra generativ AI vil komme saktere i eksisterende selskaper av omtrent samme årsak som søketeknologi ofte svikter der: Datasettet er ikke stort nok, og kravene ikke enhetlige nok.
AI-ing, AI-isering, AI-transformasjon
Unruh og Kiron (2017) deler digitalt drevet endring inn i digitisering (gjør det analoge digitalt), digitalisering (endringsprosesser for å utnytte den digitale teknologien) og digital transformasjon som den komplette omorganiseringen rundt den nye teknologien. David (1990) observerte at det tok omtrent tretti år å realisere de fulle produktivitetsgevinstene fra den andre industrielle revolusjon (dvs. å erstatte damp- eller vannkraft overført gjennom belter og trinser med elektrisk kraft distribuert gjennom kabler) fordi fabrikkeierne fortsatte å stille opp maskinene der beltene og trinsene hadde vært.
Nåværende innsats for å bruke AI for å øke produktiviteten er fremdeles i den den første fasen. Teknologien er rettet mot prosesser som er repeterbare, kjedelige og arbeidskrevende, for eksempel automatisk klassifisering og kontroll av reiseutgifter, talegjenkjenning for å rute kundeanrop til riktig agent, chat-bots for å håndtere enkle kundeforespørsler, og tale- og bildegjenkjenning for å fremskynde opplæring av ansatte. Produktivitetsgevinster har en tendens til å være beskjedne i spesifikke tilfeller, men kan være ganske dramatiske samlet sett – og de kommer først og fremst for de enkle oppgavene.
Så ja, det kommer til å bli produktivitet ut av AI. ChatGPT også. Men det kommer til å ta tid, og det kommer til å skje andre steder enn der man har trodd.
Og vi må reorganisere for å få det til.
Referanser:
Andersen, E. (2006). «The Waning Importance of Categorization.» ACM Ubiquity7(19).
Andersen, E. (2012). «Making Enterprise Search Work: From Simple Search Box to Big Data Navigation». Cambridge, MA, MIT CISR.
Brynjolfsson, E. and L. Hitt (2000). «Beyond Computation: Information Technology, Organizational Transformation and Business Performance.» Journal of Economic Perspectives14(4): 23-49.
Brynjolfsson, E., D. Rock and C. Syverson (2017). Artificial Intelligence and the Modern Productivity Paradox: A Clash of Expectations and Statistics. Cambridge, MA, National Bureau of Economic Research.
Brynjolfsson, E., D Li and L.R.Raymond (2023), «Generative AI at Work«, National Bureau of Economic Research working paper 31161.
David, P. A. (1990). «The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox.» American Economic Review80(2): 355-361.
Hitt, L. and E. Brynjolfsson (1996). «Productivity, Business Profitability, and Consumer Surplus: Three Different Measures of Information Technology Value.» MIS Quarterly20(2): 121-142.
Vi starter med å jobber for kunden, og ender opp med å jobbe for økonomisjefen…
(Denne bloggposten ble først publisert på bloggen til Comunita, et ledernettverk jeg har startet sammen med Haakon Gellein. Der diskuterer vi medlemmenes utfordringer – i dette tilfelle en stor organisasjon som ønsker å bli mer datadrevet – og jeg skriver blogginnlegg som forberedelse til disse møtene. Vi tar opp nye medlemmer etter vurdering – ta kontakt om du ønsker mer informasjon.)
Innovasjon er et honnørord – alle vil vi være innovative. Når en bedrifter er i startfasen, er innovasjon i høysetet – alle vet hva man holder på med, alle vet hvem kunden er (eller i alle fall at man må lete etter en kunde), og koordinering er enkelt, siden alle kjenner alle.
Men bedrifter vokser, og etterhvert som de vokser, endrer de seg. Selv i en verden med instant digital kommunikasjon er det vanskelig å styre og koordinere daglig arbeid – og enda vanskeligere å lede innovasjon. Med vekst kommer rutiner, systemer, komiteer og hierarkier – ikke fordi man vil, men fordi man må.
Så man innfører rutiner og kontroller, vanligvis ved å sette opp møter og spesifikasjoner, som regel ved at de som står for innovasjonen på forhånd må spesifisere hva de kan tenke seg og gjøre, hva det kommer til å koste, og hva som skal produseres. Så presenteres de ulike aktivitetene for en ledelsesgruppe, som så treffer vedtak om hva som skal gjøres, til hvilket budsjett.
Resultatet er at de som skal drive med innovasjon, bruker mesteparten av tiden sin til å forsøke å estimere hva de skal gjøre, og til å rapportere graden av måloppnåelse, definert som i hvilken grad man har fulgt spesifikasjonen, heller enn om man faktisk har fått til noen innovasjon.
Hvordan unngå dette?
Vel, man kan jo begynne med å forsøke å forstå hvordan bedrifter utvikler seg over tid.
Kriser og revolusjoner
En av mine tidlige favorittartikler er Larry Greiners Evolution and Revolution as Organizations Grow, først publisert i 1972, som beskriver fem utviklingsfaser organisasjoner gjennomgår når de vokser. Hver fase starter med en periode med stabil vekst eller «evolusjon» og avsluttes med en ledelseskrise eller «revolusjon» – der neste fase er løsningen på problemer som oppstår i forrige fase.
De fem fasene er:
Kreativitet: Entreprenørfasen, der vekst skjer gjennom kreativitiet og kontrollrutinene er uformelle, alle har felles interesse i at selskapet overlever. Etterhvert som selskapet blir større, oppstår en krise oppstår på grunn av manglende administrativt lederskap.
Styring: Vekst gjennom lederskap (ofte fordi profesjonelle ledere kommer inn, så gründerne kan konsentrere seg om utvikling. Antall lag i hierarkiet øker, ofte ved at man ansetter funksjonelle spesialister. Krisen kommer gjerne fordi ting blir for sentralisert, og lederne ikke klarer å rekke over et større antall ansatte med ulik bakgrunn og motivasjon, og de ansatte etterhvert
Delegasjon: For mye sentralisering fremtvinger desentralisering gjennom delegering – man gir deler av organisasjonen mer selvstendighet, men innfører samtidig ulike former for utfallsbaserte kontrollsystemer – egen P&L for underenheter, for eksempel. Neste krise kommer når antall enheter blir for mange og går i veien for hverandre.
Koordinering: I den neste fasen skapes vekst gjennom koordinering – både organisatorisk og systemisk. Typisk reorganiserer man etter produkt, geografi eller marked, med en konsernledelse på toppen. Krisen her kommer ved at byråkratiet øker (særlig, vil jeg mene, mellom strategiske forretningsenheter) og man får situasjoner der det er lettere å gjøre nye ting sammen med enheter utenfor organisasjonen enn innenfor.
Samarbeid: I den femte fasen fokuserer man på samarbeid og forsøker å ta et mer overordnet, prinsipporientert lederskap, med fleksible team som settes sammen for å løse oppgaver på tvers av enheter.
I hver av fasene bruker man ulike lederstiler, belønningssystemer og organisasjonsstrukturer, summert i denne tabellen:
Greiners artikkel er over 50 år gammel, men bekrefter i alle fall for meg noe jeg egentlig av visst lenge: Mye av det vi oppfatter som nyere forskning og forfatterskap er egentlig drøvtygging av ting som ble skrevet for lenge siden. Selv om man kan finne tegn på at Greiners artikkel er litt gammeldags – det er få som snakker om matriseorganisering som et sluttpunkt i dag, for eksempel – så er de fleste av observasjonene noe strateger og ledere kan kjenne seg igjen i. Og vet man om fasene, kan man gjøre noe for å hindre neste krise eller i alle fall være klar over at den kan komme.
Budsjetter og innovasjon
Innovasjonprosesser vil også endres ettersom man går gjennom disse krisene. Dette er et blogginnlegg og ikke noen akademisk artikkel (det kommer kanskje senere), men her er noen raske tanker om hva jeg mener man kan gjøre for ikke å havne i de ulike fellene:
Fra fase 1 til 2: Faren er at man administrerer innovasjon som andre prosjekter, ved å kreve detaljerte estimater av kostnader og spesifikasjoner av utfall. Bedre å budsjettere basert på standardaktiviteter – work packages, for eksempel, slik man gjør innen forskningsprosjekter, eller definerte standardprosekter, som er et konsept innen beyond budgeting. Porteføljestyring vil også hjelpe, spesielt hvis man setter mål for hva slags type innovasjonsprosjekter man skal ha og hvor stor del av porteføljen som skal være innenfor ulike risikoklasser (see denne boken av Peter Weill og andre for en god spesifikasjon på hvordan dette gjøres.)
Fra fase 2 til 3: I overgangen fra direkte kontroll til insentiv-baserte strukturer er faren at fordi innovasjon driver individuelle bonuser, blir det vanskeligere å dele innovasjoner på tvers av organisasjonen: Den som lager innovasjonen, tar også kostnaden, og det er billigere å kopiere noen andre enn å gå først selv. Smarte organisasjoner belønner deling og kopiering, både for de som blir kopiert, og de som kopierer og videreutvikler.
Fra fase 3 til 4: I denne overgangen er organisasjonen blitt så stor – og lagene så mange – at man rett og slett ikke vet om hva som finnes internt, selv av innovasjoner som ønskes delt og kopiert. Et annet problem her er at siden flere store deler av organisasjonen har egne kundegrensesnitt – digitale eller analoge – blir det vanskeligere å gjøre innovasjoner for hele organisasjonen, også fordi konsernledelsen gjerne er nokså tynt bemannet. Løsningen ligger i rutiner for utveksling av innovasjon gjennom tiltak om interne innovasjonskonferanser og digitale utvekslingsfora, for eksempel.
Fra fase 4 til 5 (og jeg er klar over at disse fasene blir vagere etterhvert): For meg er farene her litt mer uklare, men tiltak man ofte ser i innovasjonsorienterte firma i denne størrelsen handler om ting som investeringer i startups, sabbatsordninger for ledere der de eksponeres for innovasjonsbedrifter og -miljøer, og tid og ressurser satt av for at ansatte, særlig innenfor forretningsutvikling, skal gjøre ting ikke er direkte relatert til organisasjonens kjernevirksomhet. Tanken er at innovasjon oppstår ved at folk utsettes for noe nytt – at man «kompliserer seg selv», for å sitere en klassiker innen organisasjonspsykologien.
Rent konkret
Egentlig er det ikke så vanskelig: Innovasjon får man ved å ansette smarte mennesker, sette dem fri til å gjøre ting bedre, og følge dem opp uten å tvinge dem til å si hva de skal finne opp før de vet det selv. Displinerte prosesser for eksperimentering – som Finn.no gjør, et av mine mest brukte eksempler – hjelper, men ingen prosess, budsjetteringsmetode, eller ledelsesfilosofi seg selv vil noensinne garantere innovasjon. Til det trenger man tillit, intelligens, og en smule flaks, rett og slett.
Når man starter et nytt selskap, slik Haakon og jeg har gjort, er det første man må spørre seg om hva som gjør at kundene vil bli kunder (i dette tilfelle: medlemmer) og fortsetter å være det. For firmaer som Comunita, er svaret enkelt: De andre medlemmene.
Dette betyr at man må være svært nøye når man rekrutterer nye medlemmer, og fokusere ikke bare på hva det nye medlemmet kan lære fra nettverket, men også hva de eksisterende medlemmene kan lære fra det nye medlemmet.
Dette fenomenet har et akademisk navn: Nettverkseksternaliteter, også kjent, litt mindre presist, som nettverkseffekter: Et nettverk øker i verdi jo flere som bruker det, også kjent som Metcalfes lov. Begrepet kommer fra telefonselskaper, men har blitt viktigere i stadig flere bransjer. Mange av de nye gigant-selskapene – ikke bare rene nettverksselskaper som Google og Facebook, men også produktbaserte selskaper som Microsoft, Apple og Tesla – har blitt store fordi de har forstått og klart å utnytte nettverkseksternaliteter.
Åpne og lukkede nettverk
Hvis du ser på en gammel film fra 20- eller 30-tallet, er det ofte skrivebord der med flere telefoner – og mange scener handler om vanskelighetene med å snakke i flere telefoner på en gang. Det hele virker litt tåpelig – men det er gode grunner til at man hadde flere telefoner. Det var nemlig slik den gang var det flere telefonselskaper i hver by, og man kunne ikke ringe fra det ene telefonnettet til det andre. Hvis jobben krevet at man skulle kunne snakke med alle – vel, da måtte man ha flere telefoner, og kunnskap om hvem som hadde hva slags telefonabonnement.
Slik er det ikke lenger – du kan ringe til hvem du vil uansett hvilket selskap du har, og det er den enkelheten kundene etterspør. Men på veien dit er mange telefonselskaper blitt borte. Og hvert og ett av disse selskapene har på et eller annet tidspunkt måttet spørre seg: Skal vi beholde vårt lokale nettverk og bare betjene de kundene – ofte med høy lønnsomhet og kanskje med spesialtilpassede tjenester? Eller skal vi bli del av et større nettverk, tjene mindre per kunde, men med mye større volum?
I etterkant – for telefonselskaper – er det opplagt hvordan det gikk. Men underveis, før du forstår hvor teknologien går og hva effekten er, er det ikke så enkelt. Man må velge hvilken klubb man skal være medlem av, ganske enkelt.
Og som Groucho Marx har sagt det: «Jeg vil ikke være medlem av en klubb som vil ha meg som medlem…»
Synlige og usynlige effekter
For et ledernettverk om Comunita er nettverkseffekten åpenbar: Medlemmene er der på grunn av de andre medlemmene. De vet hvem de er, og det første spørsmålet potensielle medlemmer stiller, er hvem de andre medlemmene er.
Men man kan ha usynlige nettverkseksternaliteter:
Finn.no er et nettverksselskap der man ikke vet hvem de andre medlemmene er, men får greie på det først når man skal kjøpe eller selge noe.
Et forsikringsselskap er en møteplass for folk som har risiko og vil betale for å dele den risikoen med andre forsikringskunder. I det tilfellet vet man ikke hvem de andre medlemmene er – men man bør være opptatt av det. Du vil, for eksempel, ikke være den eneste forsiktige sjåføren i et selskap som bare forsikrer råkjørere.
Google tar vare på alle søk som er gjort, analyserer hvor vellykket de var, og bruker resultatene både til å forstå sine kunder bedre og å gjøre søkealgoritmene sine mer presise. Jo flere brukere de har, jo bedre blir søkemotoren.
Nettverkseksternaliteter kan gi varige konkurransefortrinn
Eksternaliteter er viktig i en digital verden, fordi alt som er digitalt, kan kopieres. Men hvis man har en digital tjeneste som avhenger av mange medlemmer – eller de dataene de legger igjen – for å virke, kan man lage noe som gir store og langvarige konkurransefortrinn. Bare se på Finn.no, som i de fleste vertikalene sine har nesten monopol. Det spiller ingen rolle om konkurrenter fra innland eller utland kommer opp med noe nytt og kult – så lenge Finn har alle kjøperne for de som skal selge noe, og alle selgerne for de som skal kjøpe, har de et langvarig konkurransefortrinn – og med det, uovertruffen lønnsomhet.
Skal konkurrenter klare å ta en bedrift med stor markedsandel og sterke nettverkseksternaliteter, kan man ikke opprette et konkurrerende tilbud og håpe på at kundene kommer over. I stedet må man finne en gruppe kunder som ønsker å gjøre noe sammen, opprette noe bare for dem, og håpe at denne gruppen i seg selv er så attraktiv at andre kommer dit. Det er derfor influensere har blitt så viktig – de er en av få faktorer som kan flytte eksternaliteter fra et sosialt nettverk til et annet.
Informasjon som nettverksvåpen
Konkurranse i nettverksmarkedet går i to faser – reach og range: I den første fasen (reach; rekkevidde) handler det om å bygge stor markedsandel så fort som mulig – å kapre alle de kundene som ennå ikke har gått til en konkurrent. Da DNB lanserte Vipps, gikk man aggressivt ut og rekrutterte kunder uten tanke på om man ville tjene penger på tjenesten eller ikke. I den andre fasen (range;[tjeneste]dybde) der alle kundene er blitt medlem av et eller annet nettverk, handler konkurranse om å utvide spekteret av tjenester som kundene kan bruke innenfor nettverket.
Særlig i den siste fasen blir informasjon viktig. Alle som driver et nettverk, må være svært påpasselig med hva slags informasjon man gir ut om bedriftens medlemmer og virksomhet – ikke bare til medlemmene, men også til allmenheten. Har man mye informasjon om medlemmene, kan man bruke det til å skape tjenester som gjør nettverket viktigere for medlemmene, og også rekruttere nye medlemmer fra konkurrerende nettverk.
Mange eksisterende nettverk – fagforbund, bransjeorganisasjoner, interesseorganisasjoner – oppdager at det blir vanskeligere ikke bare å holde på kundene, men også å få kundene til å bruke de tjenestene man tilbyr. Hvorfor være medlem av en organisasjon med kontorer og medarbeidere, når man kan oppnå mye av det samme bare ved å være medlem av en Facebook-gruppe?
Ofte handler dette om hva man er villig til å gjøre for medlemmene. For noen år siden skulle jeg arrangere et seminar for et utenlandsk firma som ville lære noe om elbiler i Norge. Jeg ringte til Oslo Taxi og sa jeg ville ha en drosjesjåfør med Tesla, fordi han eller hun ville kunne fortelle om hvordan det var. Svaret var at de ikke ville opplyse om hva slags biler de hadde, siden det var deres policy at en taxi er en taxi. Så jeg la inn et spørsmål om det samme på en Facebook-gruppe for Teslaeiere, og fikk øyeblikkelig en liste med taxisjåfører, komplett med telefonnumre.
Og deri ligger vanskeligheten for et gammelt firma: Kundene på en side etterspør informasjon du har, men som du kanskje ikke vil gi av hensyn til den andre siden av markedet du betjener. Forretningsutvikling i nettverk handler mye om å forstå hvordan og hvorfor enkeltkunder interagerer med hverandre, og om å oppfatte hva de egentlig er ute etter – hvilken jobb de ønsker å gjøre – gjennom det nettverket de er medlem av. I en verden der dannelser av nettverk skjer raskt og enkelt, blir det viktigere enn noensinne å ha evnen til å imøtekomme kundenes informasjonsbehov, enten man er vant til å tilby dem eller ikke.
Videre lesning:
Eisenmann, T., G. Parker and M. W. V. Alstyne (2006). «Strategies for two-sided markets.» Harvard Business Review84( 10): 92-101. Klassisk artikkel om hvordan man utvikler strategi i selskaper som betjener to markeder – for eksempel kjøpere og selgere som skal komme i kontakt med hverandre.
Fjeldstad, Ø. and E. Andersen (2003). «Casting off the chains: Value shops and value networks.» European Business Forum (14): 47-53. Et forsøk på å forklare verdikonfigurasjoner – og hvordan nettverksselskaper skiller seg fra selskaper som produserer produkter eller løsninger.
Strategisk forretningsutvikling og innovasjon er et kurs Ragnvald Sannes og jeg har undervist i mange år. Det er noe av det morsomste Ragnvald og jeg gjør på BI, ikke minst fordi vi møter mange spennende mennesker som er opptatt av innovasjon – eller, som vi pleier å karakterisere studentene: De som ikke klarer å la ting være som de er!
Kurset er todelt: Dels har vi vanlig kursinnhold, med forelesninger, gjesteforelesere, casediskusjoner og ikke minst en studietur til Sophia Antipolis i Provence i samarbeid med Accenture Technology Labs. Men en minst like viktig del av kurset er en prosjektoppgave som vi coacher studentene gjennom i løpet av kurset, fra en tidlig idéfase i den første modulen til en ferdig prosjektbeskrivelse/business plan/konseptpresentasjon – og i noe tilfelle ferdigstilt prosjekt – til den siste modulen. En hel del bedrifter har gjennom årene utviklet mye spennende gjennom dette kurset – og studentene setter pris på at siden prosessen starter med en gang og man jobber jevnt og trutt gjennom kurset, så slipper man en panikkfase på slutten for å bli ferdig med oppgaven.
Også i år har Ragnvald Sannes og jeg veiledet en rekke spennende oppgaver. Siden de fleste oppgavene er konfidensielle, må jeg omtale dem i nokså runde ordelag, men her er i alle fall årets oppgaver: Også i år er listen spennende – og siden de fleste oppgavene er konfidensielle, må jeg omtale dem i nokså runde ordelag. Så her er årets liste:
en helseforetak ønsker å forbedre koordinering av spesialistutdanning for leger
en gruppe ønsker å utvikle en kommersiell tjeneste rettet mot syklister i Oslo
en gruppe utvikler et system for registrering og bruk av sivile kunnskaper i en del av Forsvaret
en høyskole ønsker samordne sine systemer slik at de blir bedre i stand til å tilby kurs som treffer i markedet
I mai startet en debatt om hvorvidt ChatGPT bli dårligere. Til å begynne med var det brukere som syntes ting gikk nedover, men etterhvert har forskere og guruer meldt seg på og konstatert at svarene til ChatGPT (i hvert fall innenfor områder der det er mulig å måle kvalitet, som matematikk), typen sensitive spørsmål som kan besvares, koding og tolkning av bilder, har ting blitt dårligere over tid.
Årsaken er, paradoksalt nok, at OpenAI, firmaet bak ChatGPT, gjør endringer i algoritmene for å forbedre ChatGPT, for å øke kvaliteten og hindre at systemet blir brukt til ting det ikke skal brukes til. Og dermed synker altså den opplevde kvaliteten.
Dette paradokset er interessant fordi det illustrerer to fundamentale tilnærminger til kunnskapsbaserte systemer (som jeg synes er et mye bedre uttrykk enn «kunstig intelligens», av mange grunner).
Logiske modeller På 80-tallet, da jeg begynte å rote rundt med det som den gang ble kalt AI, var AI så og si synonymt med ekspertsystemer – det vil si systemer som kunne besvare spørsmål ved å etterligne hva en ekspert gjorde (og som ofte var laget ved at man intervjuet eksperter). De ble programmert som en rekke spørsmål – «Er pasienten kortpustet?», «Hvor mye røyker han?» – og stiller så en diagnose basert på beslutningstrær. I dagliglivet treffer du denne typen systemer som chatbotene som i alle fall forsøker å besvare enkle spørsmål i banken og andre steder man henvender seg.
Statistiske modeller På slutten av 80-tallet (vel, egentlig mye tidligere, men de ble vanligere da) kom nevrale nettverk og andre, mer statistisk baserte metoder, som tok utgangspunkt i store mengder data og konstruerte modeller som kunne klassifisere ting. I motsetning til ekspertsystemene, som var basert på en logisk modell av hvordan folk tenker, tok disse metodene inspirasjon fra en fysisk (og, for all del, teoretisk) modell av hvordan hjernen virker. De prøver seg frem til de finner en modell som gir ønsket resultat, ofte ved å konstruere nettverk av enkeltinformasjonselementer som er forbundet, og der forbindelser mellom elementer styrkes eller svekkes gjennom prøving og feiling.
ChatGPT og andre store språkmodeller hører til denne typen systemer: De forsøker å gjette det neste ordet i en setning rett og slett ved å ha lest enorme mengder tekst og velge det ordet som er mest sannsynlig.
Forskjellige feilmodus Disse systemene har mange forskjeller – en av dem er hvordan de gjør feil. Ekspertsystemene er nokså enkle – hvis de ikke finner et svar, sparker de problemet videre til noen som har svaret, som regel en person. De kan selvfølgelig også svare feil – men da er det som regel nokså enkelt å forstå at svaret er feil, siden det ser urimelig ut. De er på mange måter å sammenligne med søk i databaser, der man må være nokså presis i hva man spør etter, og databasen vil svare at den ikke har noe som passer hvis så er tilfelle.
Statistisk baserte modeller, derimot, vil alltid gi et svar. Slik er de mer å sammenligne med søkemotorer, som alltid vil forsøke å gi deg noe, selv om det ikke passer. (Når fikk du sist en melding fra Google om at det ikke fantes noen sider som oppfylte dine kriterier?) Svarene kan være riv ruskende gale, men vil se troverdige ut. En generativ språkmodell, som ChatGPT, har ingen underliggende fornuft, den forsøker bare å gjette hvilket ord som passer best, gitt de ordene som kom før.
Når kvalitetskontrollen roter til ting Et problem med de statistisk baserte modellene, i alle fall de som bruker nevrale nettverk, er at de kan bli riktig gode på å kategorisere ting – billedgjenkjenning, tekstgjenkjenning, tekstfortolkning – uten at man kan forklare, i alle fall på en måte mennesker kan forstå, hvordan de gjør det. Det kan også gjøre store logiske feil: Selv om ChatGPT kan skrive pressemeldinger og eksamensoppgaver som ser tilforlatelige ut, gjør den logiske feil – noe som ofte viser seg i at den produserer falske referanser, det vil si lager en referanseliste med artikler som ikke finnes. (Biblioteket på BI rapporterer om studenter som dukker opp og skal ha artikler av denne typen.) Den kan godt generere en caseanalyse eller en sosiologisk drøfting – der er jo grunnlaget ord (og mange av dem). Men folk som har bedt den skrive en artikkel innen fysikk eller matematikk, sier at den produserer noe som ser svært tilforlatelig ut hva teksten gjelder, men formler og formell deduksjon er helt håpløst.
Det betyr at man må putte på en eller annen form for kvalitetskontroll som er logisk basert – altså bruke ekspertsystemlogikk til å kontrollere det som genereres. Dette kan gjøres på mange måter: Man kan ha en inputkontroll (slik at folk ikke kan be ChatGPT skrive noe rasistisk eller instruksjoner for å lage en atombombe). Man kan kombinere ChatGPT med logiske systemer – for eksempel Matematica, Stephen Wolframs matematikkprogrammeringssystem, som nå integreres med ChatGPT.
Og det er her det ser ut til at det blir vanskelig.
Siden man ikke helt vet – i hvert fall ikke i detalj – hvordan ChatGPT produserer et tekststykke, blir det svært vanskelig å introdusere kvalitetskontroll eller andre begrensinger rett i modellen. Man blir henvist til enten å filtrere input og output – og det gjøres i stadig større utstrekning – eller (svært forenklet) å legge begrensinger på hva slags tekstmateriale som kan brukes som underlag for å generere ny tekst.
Jeg har litt følelsen at OpenAI (og deres konkurrenter) har laget ChatGPT og andre modeller, og nå står og ser på denne maskinen og ikke helt forstår hva de har laget. Jeg hadde en gammel og komplisert Mercedes for noen år siden. Den var kul (syntes jeg i alle fall), men jeg kunne jo ikke skru på den selv fordi den var så komplisert, og visste at nesten enhver ting jeg gjorde, hadde mye større sannsynlighet for å rote ting til enn å gjøre den bedre.
Men bare vent… Så det er ikke helt tid for å sparke kommunikasjonsavdelingen ennå – men kanskje tid for å ha flere folk til å kontrollere resultatet enn å generere innholdet. Ledere jeg kjenner, har kommentert at eposter de får har blitt lengre, høfligere og med rikere vokabular. Men jeg ville ikke helt automatisert epostene mine ennå, og slett ikke om de inneholder konkrete fakta og definitive avgjørelser.
Hva den automatiske kvalitetskontrollen gjelder, så er det fremdeles tidlig i språkmodellenes utvikling – hvis vi regner ChatGPT som begynnelsen. Men ChatGPTs røtter ligger i forskningen til Frank Rosenblatt fra tidlig sekstitall og Rumelhart og McClellands bok fra 1987 – og sett i det perspektivet er ChatGPT det foreløpig siste skrittet på en lang reise.
Da elektrisiteten kom, kom det også allslags finurlige apparater som skulle gi bedre hårvekst, bedre potens, og for alt jeg vet mer intelligens. Det samme gjaldt radium, kaffe, poteter og mye annet. Nå for tiden er det vel antioksydanter og AI som i har rollen som universalløsning. Over tid får man et mer edruelig forhold til fenomenet, bedre oversikt over bivirkninger, og fremfor alt bedre forståelse for hva det kan brukes til.
Så ChatGPT råtner egentlig ikke. Teknologien har i stedet startet på en prosess som over tid vil gjøre teknologien bedre, mer pålitelig, og med mer presist definerte bruksområder. Jeg tror mer på en gradvis forbedring enn en revolusjon der ChatGPT 7 eller 8 tar over verden. I mellomtiden forsøker jeg å lære meg å bruke de nye verktøyene smart – og insisterer på at de er verktøy og ikke noe annet.
Min gode venninne Silvija Seres – som jeg har skrevet en haug kronikker med og alltid ser frem til å snakke med – inviterte meg til å lage en podcast om digitale plattformer for noen uker siden. Resultatet i all sin skravlete omtrentlighet finner du her.
Da har man vært og holdt et innlegg på Registerkonferansen 2021 i Bodø Brønnøysund… eller, vel, jeg kunne ikke være til stede fysisk, så da laget jeg en video. Selve innlegget var bare på 15 minutter og historiene er nokså velkjent – men mottakelsen var bra, er jeg blitt fortalt.
Her forleden deltok jeg i en podcast fra Oslo Business Forum om plattformøkonomi og forretningsmodeller med Jens Hauglum, produktdirektør i Finn.no, og Christian Brosstad fra Atea Norge. Resultatet er tilgjengelig på Spotify og Apple. Det ble en hyggelig liten time med temaer som nettverkseksternaliteter, handelsvertikaler og algoritmeregulering.
— er tittelen på et foredrag jeg skal holde (på engelsk) for EGN internasjonalt torsdag 27. mai klokken 9-10. Foredraget (som blir en uformell samtale mellom meg og administrerende direktør for EGN, Jonatan Persson) kommer til å handle om hvorfor Tesla kan utgjøre en trussel for store deler av bilbransjen – inkludert et lite dykk inn i hva den egentlige forskjellen (etter min mening) mellom Tesla og andre bilfabrikanter er.
Foredraget (og påfølgende diskusjon) er åpent for alle, du finner informasjon her og påmeldingsskjema her.
Nok en liten epistel i Digi.no, denne gang om det jeg kaller Facebook-metoden for å håndtere kompleksitet: Start med det enkleste først. Ganske enkelt. Det betyr at man må si nei til de mange som ønsker at deres bidrag til kompleksitet skal komme med, i hvert fall i første omgang.
Og det er ikke så lett.
Ethvert stort, komplisert system som virker, startet som et lite, enkelt system som virket.
John Gall, Systemantics
(En versjon av dette essayet ble publisert på ACM Ubiquity’s blogg i 2015 – og ble det mest leste innlegget der noensinne. Takk til Peter Denning for gode kommentarer på tidligere versjoner.)
Og her er lydfilen (etterhvert tilgjengelig på Spotify):
Etter en liten sommerpause kommer nok en kommentar i digi.no. denne gang om hvordan man må tenke annerledes om Akson-prosjektet. Mitt hovedpoeng er at systemet må skaleres ned til bare å handle om det medisinske og dataene rundt det – med et teknisk uttrykk, at systemet må tenkes på som kun et system for utveksling av informasjon, ikke som et system som skal løse alle punkter på en enorm ønskeliste som kommer til å endres masse frem til systemet blir ferdig – om det noensinne blir det.
Megaprosjekter innen software går ikke, ganske enkelt. Og medisinske systemer bør bygges ut fra det medisinske, ikke det byråkratiske.
Akson bør bli hodeløst. Så spørs det om noen har hode til det.

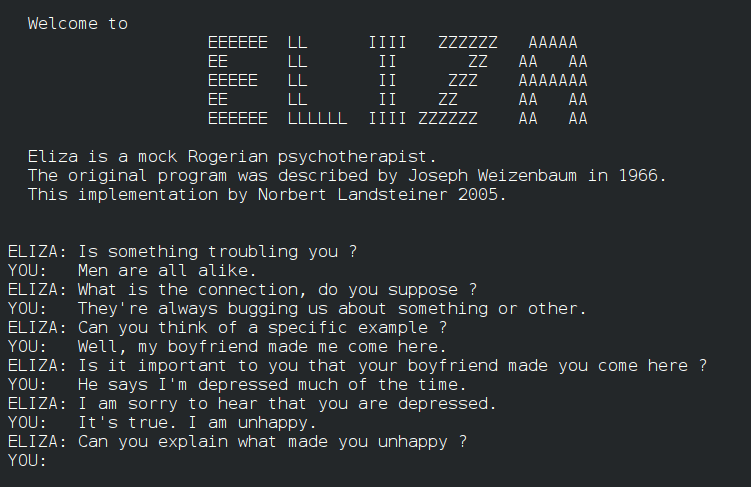













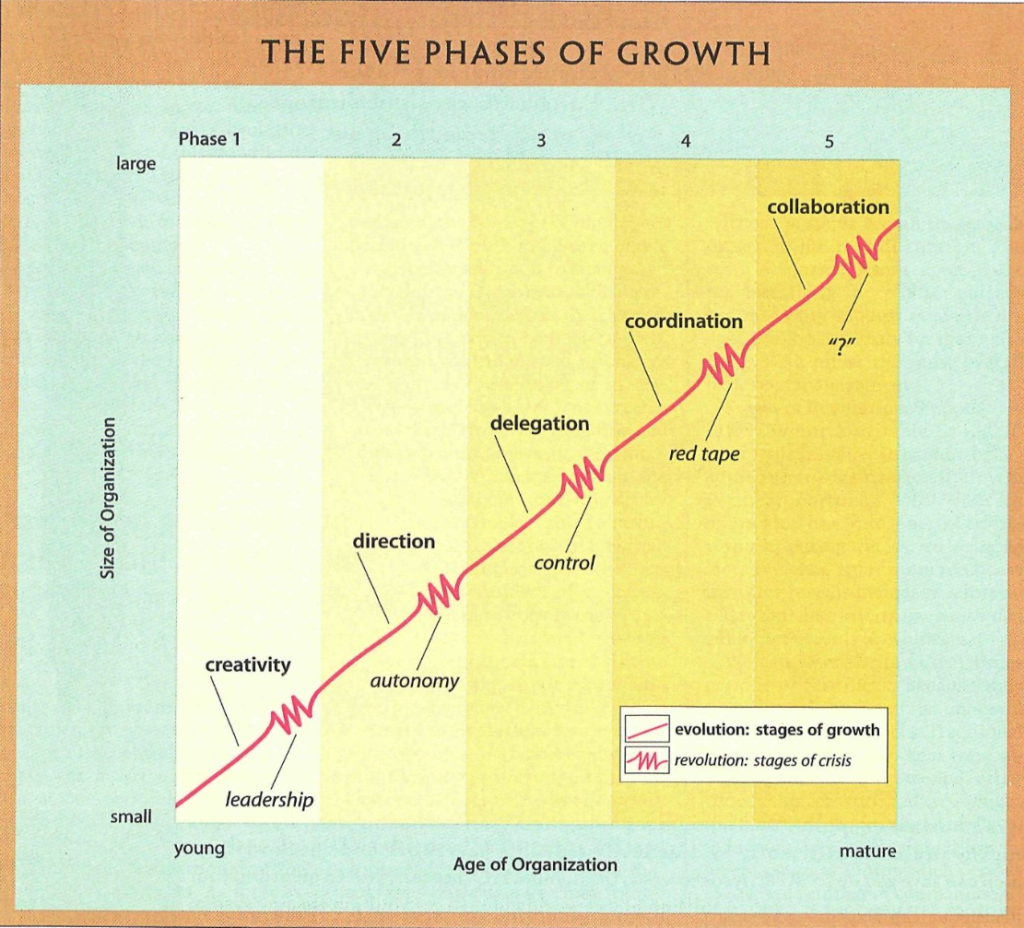
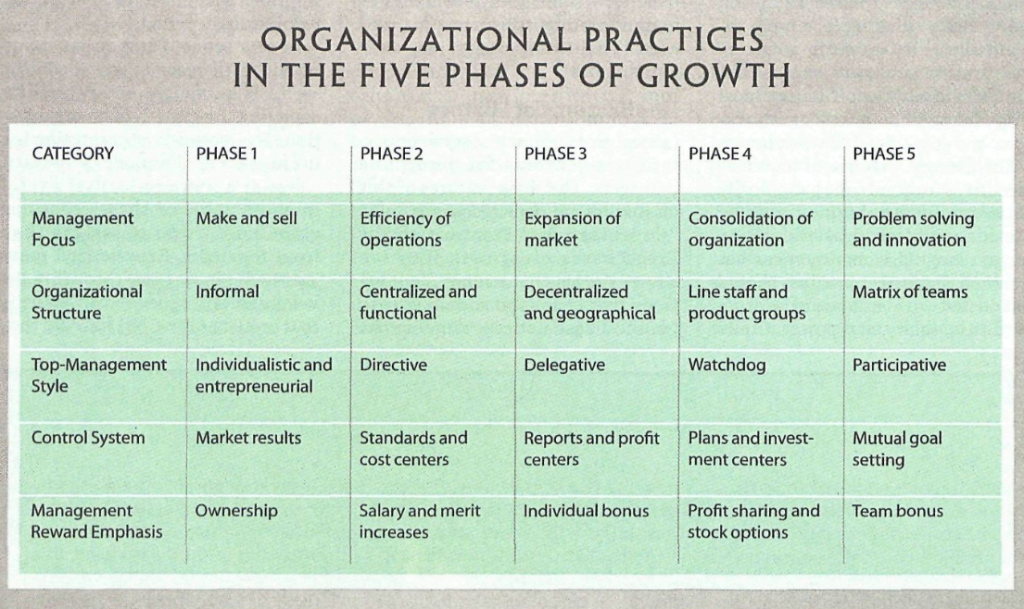










{kind=link}