Til høsten er det tid for en ny runde med BIs nye styrekurs på masternivå: Det verdiskapende styret. Kurset går over tre moduler frem til jul – pluss noen webinarer før og mellom modulene – og målet er å utdanne folk som kan bidra ikke bare til å besette styreplasser, men aktivt å hjelpe ledelse og bedrift å forholde seg til endringer i omgivelser og konkurransesituasjon.
Som for tidligere år, så har jeg har fått et stjernelag til å hjelpe meg – og for å introdusere dem, har jeg laget noen små videoer der de får anledning til å gi en smakebit på hva de kommer til å bidra med gjennom kurset:
Berit Svendsen har lang erfaring som styreleder, -medlem og toppledelse, bl.a. som administrerende direktør i Telenor Norge. Hun ble årets styreleder i 2024. Berit har tidligere hatt en stilling som executive in residence på BI, og hun og jeg har samarbeidet i mange år om alt mulig innen teknologi, ledelse og strategi. Hun stiller kontinuerlig rolle gjennom kurset og dele av sin erfaring og sine refleksjoner. I videoen her forklarer hun litt om hvordan hun ser styrets rolle i forhold til eksterne utfordringer, og litt om den menneskelige siden ved styrearbeid, særlig styret som arbeidsgiver for administrerende direktør.
Tore Bråthen er professor dr. juris ved BI, og vil ta ansvar for to viktige tema: Styrejus og styreansvar. Det snakkes mye om at et styre skal ta et strategisk ansvar og være en sparringpartner for eiere, ledelse og administrasjon, men til syvende og sist er det jus som gjelder, og styreansvar skal man ikke spøke med. I tillegg til å være en glimrende foreleser, har Tore utmerket bakgrunn for å snakke om disse temaene, siden han har vært involvert i å utrede og skrive de lovene som gjelder for styrearbeid.
Thomas Borgen er Ph.D. stipendiat ved BI og har hatt lang erfaring fra på styresiden og administrasjonssiden, bl.a. som styreleder i Kongsberg Digital og Scanship, tidligere adm dir Danske Bank, nå også seniorkonsulent for Bain & Co. Thomas har lang erfaring fra vanskelige beslutningssituasjoner og vil ta med seg dette inn i kurset – i tillegg til sin forskning som stipendiat.
Ketil Hveding er høyskolelektor ved BI Trondheim, underviser på BIs grunnleggende styrekurs og har lang erfaring som styreleder, styremedlem og konsulent for små og mellomstore bedrifter. Ketil vet noe om forskjellen mellom store og små selskaper – en verden der reglene er mange og rollene som eier, styremedlem og bedriftsleder kanskje ikke like avklart som de burde være.
Selv kommer jeg til å snakke om teknologiutfordringer (særlig AI), styrets ansvar i innovasjon og strategiarbeid, og alt mulig annet. I tillegg kan jeg love masse gode gjesteforelesere rett fra frontlinjen!
Og dermed var en æra over – jeg har solgt hummerbåten. Den er ikke så mye å se på – en 16.5 fots Hansvik Family fra 1978, med en nesten 20 år gammel (men god) motor og et interiør preget av mye bruk. Jeg kjøpte den i 2001, og det var min første båt med motor.
Jeg fant ut at når man kjøper sin første båt, er det lurt å kjøpe noe gammelt: Da jeg skulle legge til en brygge med dregg for første gang – på Gressholmen, det var havblikk – brukte jeg over en halv time med fikling og eksperimentering. Jeg gikk i land, der sto det en kar ved siden av båten sin og så på meg. Jeg kommenterte at jeg var helt fersk i dette, der var derfor det tok så lang tid, og han svarte at han sto og holdt på båten sin (en splitter ny daycruiser) fordi han var i samme situasjon og ikke visste hvordan han skulle fortøye. Og jeg tenkte: Hvis jeg smeller båten min i brygga, så er det ingen som ser skrammene, og skulle den gå tapt, så er det ikke mye penger.
Svært kortreist hummer. Akkurat denne var over maksmålet og ble sluppet ut igjen.
Etter hvert har det blitt andre båter, og Hansvik’en ble liggende litt forlatt. Jeg tenkte på den som reservebåt og kanskje noe mine barn ville bruke, men slik gikk det ikke. Så ble det pandemi, og jeg fikk en telefon fra min venn Skipperen, som kjedet seg og lurte på om vi kanskje skulle begynne å fiske hummer. Dermed døpte vi Hansvik’en om til «sjarken», kjøpte hummerteiner på Biltema, søkte og fikk tillatelse, og satte i gang.
Ferdig kokt og klar til fortæring – det enkleste er det beste!
Det gikk over all forventning. Jeg hadde vært fornøyd om vi hadde fått nok til en hummermiddag – men ved sesongens slutt hadde vi fanget 115 hummer! 55 av dem måtte vi sette ut igjen av ulike grunner (rogn, for små, for store, etc.) og 5 stykker klarte å stikke av fra sanketeinen, men resten ble til de deiligste hummermiddager. Vi kjøpte mer utstyr (flytedresser, fiskerhansker, vabein, etc.), fisket masse makrell til agn, og lærte å sette pris på lukten av skikkelig råtten fisk. Vi hadde mange opplevelser med bølger, regnvær, isbryting, og andre hummerfiskere. For meg, som aldri har fisket eller vært ute på sjøen om høsten, var det å oppdage en helt annen side av Oslo.
Morgenstemning med tåkeSkipperen i normalpositur
Isbryting på slutten av sesongen
Vi fortsatte å fiske hummer, med noe fallende resultat: Fra 55 godkjente hummer i 2020 ble det 31, 36, 30 og til slutt 12 i 2024. Det kunne jo være fristende å si at det fallende resultatet kom av at Oslofjorden dør, men det har vi faktisk ikke holdepunkter for. For vårt vedkommende handlet det også om at det ble mange flere hummerfiskere (teinene stod tett i tett etter hvert, særlig de to første ukene av sesongen), samt at vi av ulike årsaker (jobb, reising) ikke fikk fisket så mye som vi hadde kunnet gjøre under pandemien. Det siste året hadde vi (og andre fiskere) også et problem med at noen stjal fra teinene.
En annet og svært positivt resultat var at hummerfiske fungerte som et skikkelig sjekketriks – det har i alle fall min kone fortalt. Hun ble introdusert til hummerfiske en måned etter at vi traff hverandre og håndterte båten med stor entusiasme og treffsikker navigering. Våre venner lærte seg at når hummeralarmen gikk (med andre ord, om vi ringte i oktober) så var det om å gjøre å ta den telefonen – ellers gikk middagsinvitasjonen til noen andre.
Vi lærte etter hvert mye om hummer, blant annet at en hel del hunnhummere blir blå – og de kan bli store. Spesielt var det en hummer som holdt til sør for Ulvøya og som vi dermed døpte Miss Ulvøya. Hun var for stor til å spises og ble sluppet ut igjen, men dukket opp i teinene i flere år.
Miss Ulvøya (til venstre) og Forloveden (som i fjor ble Kona).
Stor var min forundring da jeg leste i Aftenposten at blå hummere er svært sjeldne. Jeg forsøkte å kontakte journalisten og snakket også med en rådgiver i WWF. Jeg kan ganske enkelt ikke forstå at dette er så spesielt, all den stund vi fikk opp nok blå hummere til at vi ikke engang tenkte over fargen. At denne blåfargen skal taes til inntekt for at fredning virker, forstår jeg ganske enkelt ikke.
Men så er jeg jo bare – eller var – en ganske enkel hummerfisker…
Jeg var litt treg med å selge båten, og Kona mente at denne var det bare å gi bort – hun skulle spise hatten sin om jeg fikk solgt den. Det viste seg at det er stor etterspørsel etter en gammel båt med tilhenger og en brukbar motor. Båt er båt, som det heter, og dette har for meg vært en kjempeinvestering. Sjarken gikk til en hyggelig iraker som bor i Halden. Han har små barn og liker å fiske, så dette blir sikkert bra. Lykke til – og takk til Hansvik’en for lang og tro tjeneste!
For noen måneder siden hadde jeg en videokonferanse med et ungt menneske som lurte på om hun skulle søke doktorgradsstudium på BI. Vedkommende var atypisk i mange dimensjoner fra de fleste doktorgradsstudenter jeg har møtt, men hadde tatt en mastergrad, likte jobben med masteroppgaven, og lurte på om det å fordype seg ytterligere kunne være det neste. I tillegg – og her er poenget – hadde hun blitt anbefalt å vurdere en doktorgrad av sin AI-baserte coach.
Vi diskuterte litt frem og tilbake, og jeg anbefalte henne å søke. Om hun gjorde det, vet jeg ikke. Men jeg ble sittende og tenke etterpå.
Det å ha en coach, terapeut, rådgiver eller for den saks skyld venn å snakke med, er jo i seg selv ikke noe negativt. Ei heller er det negativt at denne coach’en er digital – den er i alle fall billig (foreløpig) og tilgjengelig til alle døgnets tider. Gitt at den er «promptet» skikkelig (rolle, situasjon, målsetting) vil vel også svarene være noe i retning av hva en menneskelig coach. Og digitale samtalepartnere har jo lange tradisjoner, som Joseph Weizenbaums Eliza viste – i 1966!
Men hva slags motivasjon har en slik coach – eller, for å si det på AI-språket: Hva er dens belønningssystem (reward function), og hvordan påvirker målsettingen hvilke svar den gir?
Svaret er at de i hovedsak er designet til å være hyggelige mot oss.
Belønninger former resultater
Store språkmodeller svelger enorme tekstmengder og trener seg opp å forutsi neste ord i en rekkefølge, ved en rekke matematiske prosesser, hovedsaklig matriseregning (glimrende forklart i denne videoserien.) Etter denne treningen gjennomgår modellen en finpussfase kalt Reinforcement Learning from Human Feedback (RLHF). Mennesker rangerer modellens svar, og modellen justeres mot å produsere svar med høy rangering. Et av problemene med denne prosessen er at vi mennesker liker å få rett: Vi liker svar som bekrefter våre antagelser, som er formulert med selvtillit og en viss autoritet, og som ikke utfordrer oss for mye. Dermed lærer ikke nødvendigvis modellene å bli sannferdige eller kloke. De lærer å være behagelige.
Dette blir et utbredt problem etterhvert. Sharma et al (2023) fant at ulike modeller hadde en tendens til å være smigrende. (Det engelske utrykket er sycophancy, norsk sykofant, en person som smigrer – og et ord jeg synes burde brukes mer). Modellene endrer korrekte svar når brukeren uttrykker tvil, gir etter for press selv om de har rett, og tilpasser meninger til hva brukerne signaliserer at de ville høre.
Av og til kan smigeren bli for åpenbar: I april 2025 slapp OpenAI en oppdatering av GPT-4o som hyllet trivielle innfall som geniale, bekreftet tvilsomme forretningsidéer som strålende, og strøk brukerne såpass mye med hårene at det ble pinlig. OpenAI rullet tilbake oppdateringen og publiserte en forklaring der de innrømmet at de hadde lagt for mye vekt på kortsiktige tilbakemeldinger fra brukerne i treningsprosessen.
Problemet er at det er ikke så lett å måle om et svar er godt, i hvert fall ikke en måte som er skalerbar, rask og billig. Reinforcement learning – å la maskinen prøve seg om og om igjen til ting blir riktig – fungerer så lenge det finnes et klart formulert mål, enten dette er å spille Breakout eller diagnostisere kreft. Det å ikke ha data – spesifikt, data med korrekte svar å trene mot – er den vanligste grunnen til at analyseprosjekter mer eller mindre mislykkes, noe jeg har sett mange ganger i kursene mine.
Problemstillingen kalles «AI alignment» og er ikke enkel. Anthropic har forsøkt seg med noe de kaller «constitutional AI«, som i hovedsak går ut på å la modellen måle sine svar opp mot anerkjente verdier – som FNs menneskerettighetserklæring. Dette er også en teknikk som blir anbefalt av produsentene av modellen selv: Bruk modellen til å være kritisk til hva den selv sier.
Digital Trumpisme
Donald Trump omgir seg med rådgivere som snakker ham etter munnen. Han har klart målbare målsettinger – kortsiktig popularitet og kortsiktig økonomisk gevinst – og ingen som helst sperre på hvor sterkt og åpent de uttrykkes. Siden han kan velge sine medarbeidere, foretrekker han de som skryter av ham heller enn å gi ham motstand, og dermed ender man opp med noksagter som Pam Bondi, fanatikere som Pete Hegseth eller værhaner som JD Vance.
Den katolske kirken hadde tidligere noe som heter «djevelens advokat» – en person som har som oppgave å argumentere kraftig og nesten vitenskapelig mot at en person skal erklæres for helgen. Christopher Hitchens var ganske imponert over de katolske geistlige som besøkte ham da Mor Theresa skulle kanonseres. De lyttet nøye til hans motforestillinger både mot hennes gjerning og de miraklene som skulle gi henne helgenstatus – men trass i gode begrunnelsen ble hun altså helgen. Med andre ord, det hjelper lite å ha institusjonelle motforestillinger, digitale eller ikke, hvis de ikke blir lyttet til.
Og dit kommer vi kanskje. Jeg har hatt en hel del studenter som har kommet til meg med AI-resultater og presentert dem som sine egne. Men jeg har ennå ikke hatt noen som har insistert på at det AI har produsert er sant, og lurer litt på når det skjer og hva jeg skal si da (uten å eksplodere). Den første generasjonen studenter som har hatt tilgang til språkmodeller uteksamineres i disse dager, og de liker ikke AI, delvis fordi de er usikre på om de faktisk kan noe, delvis fordi arbeidsmarkedet for nyutdannede er dårligere enn det har vært på lenge, noe som tilskrives AI.
Men det spørs jo om ikke det behagelige etter hvert blir det sanne og eneste. Slik det har blitt for Trump.
(Og ja, jeg startet dette innlegget med Claude, men endte opp med å skrive neste hele greia selv, siden jeg skriver forblommet nok som det er, uten hjelp fra en entusiastisk språkmodell.)
Hvis du lever av å levere kvalitetsinformasjon til betalingsvillige kunder – hvor redd skal du være for AI-basert konkurranse?
Det altseende monsteret Argos, i følge Gemini.
(En versjon av denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Den gang jeg var student – tidlig 80-tall, intet mindre – fantes ikke sosiale medier, Internett, kommentarfelt eller fake news (i hvert fall ikke fake news produsert av privatpersoner.) Ikke desto mindre følte mange bedriftsledere et behov for å følge med på hva som ble skrevet om dem og bedriften deres. Derfor hadde de gjerne abonnement på Argus (oppkalt etter et altseende monster fra gresk mytologi), en utklippstjeneste der folk var ansatt for å lese gjennom aviser, klippe ut artikler skrevet om hva det nå var man var opptatt av, lime dette på papir og levere eller sende det til kundene.
Om dette høres tregt, dyrt og primitivt ut, så må man huske at alt er relativt: Aviser kom (som oftest) bare en gang om dagen og det fantes bare én TV- og radiokanal med nyheter. Hadde man en faks, fikk man kopier av artikler og annet hver morgen – raskere enn om man pløyde gjennom avisene selv, og med mindre risiko for at man gikk glipp av noe i en eller annen lokalavis.
Men så lenge medieovervåkningen var raskere enn mediet, hadde man jo nogenlunde kontroll.
Digitalisering
Etter hvert ble avisenes arkiver digitalisert: Aftenposten var en pioner her, de hadde digitalt arkiv fra ca. 1983 og var tidlig ute med å lage en nokså primitive søkemotorer mot dette arkivene. Medieovervåkningsbransjen endret seg: Først ved at det ble etablert digitale overvåkningstjenester med tilgang til avisenes interne arkiver, deretter, etter hvert som avisene ble tilgjengelige over Internett fra midten av 90-tallet, mer automatiserte tjenester (basert på søkeord) som brukte det åpne nettet, ikke avisenes eget materiale, som viktigste kilde. (Hvis du er interessert i mer detaljer, se denne artikkelen fra 2008.)
De nye medietjenestene var billigere og raskere enn de eksisterende – de kunne søke på mange søkeord og levere resultatet via epost, uberørt av menneskehender. Tjenestene deres var av dårligere kvalitet enn de manuelle, dyre tjenestene, men de vant frem fordi de fant nye kunder som ikke trengte den samme kvaliteten. Det betød at de ofte fikk falske alarmer, men prisen var lav og hastigheten høy, og over tid ble den nye tjenesten bra nok, samtidig som mer og mer av nyhetsbildet skjedde utenfor papirbaserte og/eller lukkede kanaler.
Og i dag finnes – såvidt jeg vet – ikke manuelle medieovervåkningstjenester lenger. Noen av firmaene er borte, noen av deres etterfølgere lever videre og leverer tjenester på toppen av søkesystemer, som for eksempel systemer for å levere pressemeldinger eller forholde seg til investorer (og noen av dem gjør det bra). Selve søketjenesten er nå, for de flestes vedkommende, automatisert bort til en enkel abonnementstjeneste, programmert inn som en IFTTT-makro, eller ved at man legger inn faste søk i Google eller (mistenker jeg) bruker en AI-agent.
Den dødelige jakten på lønnsomhet
Det er ikke så uvanlig at nye selskaper kommer til etter hvert som teknologien utvikler seg – det skjer naturligvis hele tiden. Gåten ligger i hva som skjer i de gamle selskapene – hvorfor reagerer de ikke på den nye konkurransen og begynner å levere de sammen tjenestene? De burde ha alle fordeler – kunderelasjoner, kunnskaper, og bedre kildetilgang.
Svaret heter naturligvis disrupsjon – eller rettere sagt, disruptive innovasjoner.
Sett at du er et selskap som leverer en informasjonstjeneste av god kvalitet – for eksempel ved at du bruker mennesker som velger ut materiale, mennesker som forstår hva kunden er ute etter og velger ut det som er aktuelt og faktisk handler om ditt selskap og din bransje og ikke noe som tilfeldigvis ligner. Så dukker det opp en konkurrent som leverer noe som er dårligere, men billigere. Dine gode, trofaste kunder bryr seg ikke om dem, men de tar endel av de marginale kundene dine – kunder som synes dine tjenester er bra, men for dyre, og som ikke trenger den kvaliteten du leverer.
Hvordan skal du respondere? Hvis du forsøker å tilby en dårligere tjeneste til billigere pris, utkonkurrerer du deg selv – og selv om du vinner, vil du vinne et marked som er mindre lønnsomt (om enn kanskje større) enn det du er i nå. Selv om det finnes eksempler på selskaper som har gjort dette – Schibsted, for eksempel – hører det til sjeldenhetene.
Mye vanligere er at man forsøker å gjøre produktet sitt enda bedre, for å kunne ta en høyere pris av de kundene man allerede har (og kanskje skaffe seg nye, betalingsvillig kunder). Denne strategien fungerer ofte i praksis, i alle fall hvis markedet har plass, tjenestene ikke er for sammenlignbare, og utviklingen ikke går for fort. Selv om disrupsjon er lett å beskrive, tar ting tid og man mister gjerne fokus.
Et alternativ er å lage en ny løsning – en billigversjon – som utnytter den nye teknologien, samtidig som man trekker på den erfaringen og informasjonstilgangen bedriften allerede har. Vanskeligheten her ligger dels i markedsføring – det er viktig å holde merkevarer fra hverandre – men også i organisasjon. Da Intel på 90-tallet introduserte en billig chip for å utkonkurrere nye leverandører, la man design og produksjon til et sted langt unna eksisterende fabrikker, slik at man fikk fokus på å lage noe billig som var bra nok, heller enn å lage noe som var så bra som mulig.
Det er kulturforskjell på Skoda og Audi, må vite.
I virkeligheten tar ting tid og er ikke så krystallklart som teorien vil ha det til, ganske enkelt.
Viktor Klemperer var professor i fransk språk og litteratur ved universitetet i Dresden, jøde, gift med Eva, og dagbokforfatter. Han og hans kone overlevde på mirakuløst vis krigen, dels fordi hun var «arisk» og dermed ga ham en viss beskyttelse, dels fordi bombingen av Dresden forhindret at de begge ble transportert til dødsleirene senere i krigen.
Klemperers dagbøker, som først ble publisert på 90-tallet, besvarer på et uhyggelig vis spørsmålet om hvorfor jødene ble i Tyskland og ikke dro, og hvordan et samfunn kan gå fra demokrati (om enn urolig og dårlig fungerende) til totalitært diktatur på få år. Svaret ligger i de små tingene, at det å dra fra alt man har og er glad i, både materielt, intellektuelt og følelsesmessig til noe uvisst er en beslutning som på ethvert tidspunkt er for vanskelig å ta. I takt med stadig nye, små bestemmelser (jødene fikk for eksempel ikke lov til å ha husdyr, ikke lov til å ta trikken med mindre de skulle over syv km til arbeid, ikke lov til å ha førerkort, etter hvert ikke lov til å ha bil, ikke lov til å ha forråd av mat hjemme, og så videre) blir det flere som vil dra, men mulighetene lukker seg raskere enn nødvendigheten av å dra, inntil det er for sent.
Forestillingen på Amfiscenen er lavmælt, bruker mange virkemidler, krever konsentrasjon, og det er kanskje en fordel å ha lest eller i alle fall vite om Klemperers dagbøker. Det er et ensemblestykke (Ola G. Furuseth, Hanne Skille Reitan, Stine Fevik og Ågot Sendstad) som alle leverer, akkopagnert av en hardt arbeidende pianist (Eirik Hellerdal Fosstveit) som gir et bakteppe som kommuniserer godt med budskapet. Smart scenografi og bruk av enkle rekvisitter gir et interessant mediebilde som virker tidsriktig men samtidig moderne. Tore Vang Lid har ikke falt for fristelsen av å retolke tekstene til noe annet enn det de er – og det er ikke nødvendig heller.
Det er ikke så mye å si – parallellene til samtiden er nokså opplagte. Jeg anbefaler helhjertet denne lavmælte forestillingen, som står godt til det loslitte inntrykket Nationaltheatret nå gir. Den gir anledning til å reflektere over den lavmælte kunnskapens kår i en raskt voksende kakofoni av budskap og kommunikasjonsmetoder som i foruroligende grad ligner, nettopp, det tredje rikets språk.
Den uforlignelige Christopher Hitchens har etterlatt seg et klipp på YouTube der han beskriver Viktor Klemperer og hans dagbøker, og det kan være et like bra epitaf som noe annet:
12. mars i år var Comunita – et ledernettverk jeg driver sammen med Haakon Gellein – på besøk utenfor Oslo-gryta – i Sand i Suldal, en liten kommune på Vestlandet, som ønsker utvikling og har endel forutsetninger for å få det til. Vertskap var Næringshagen i Ryfylke, som driver næringsutvikling i kommunene Suldal, Sauda og Hjelmeland – og har resultater å vise til.
Men hva betyr egentlig næringsutvikling for en liten kommune – og hvordan gjør man det, sånn rent praktisk, forskjellig fra næringsutvikling i større sammenhenger, som storbyer eller land? (Og ja, hvis dette innlegget viser at det i grunnen ikke er så stor forskjell på å tenke næringsutvikling i et lite land og en liten kommune, så er det hensikten.)
En liten, åpen, rik og lik økonomi
Jeg hørte engang Viktor Norman si at «Norge er som min lommebok – en liten, åpen økonomi.» Landet er lite (vi er godt innenfor feilmarginen av en indisk folketelling) og har et lite hjemmemarked, hvilket betyr at vi må selge ting til resten av verden for å få penger og kjøpe ting fra resten av verden hvis vi skal ha noe. Det betyr også at vi må få mange av våre innsatsfaktorer – som kunnskap og teknologi – inn fra utlandet.
Det er på et nasjonalt nivå. Hva med en kommune? Er den et Norge i miniatyr, eller er det forskjeller som gjør sammenligningen meningsløs?
Norge er et rikt land (et av de rikeste i verden, faktisk), men de fleste små kommuner i Norge har ikke mye midler å rutte med: 7 av 10 har et driftsresultat under det som ansees forsvarlig. Det er det mange årsaker til, men en er at mange oppgaver pålagt av sentrale myndigheter ikke fullfinansieres. Det er lett å se for seg en spiral, der svak økonomi fører til dårligere kommunale tilbud – som skoler og barnehager. Dette kan føre til fraflytting, som gir enda dårligere økonomi, og så videre.
Det er også slik at Norge er svært likt – vi har en av de laveste Gini-koeffisientene i verden. Det betyr ikke at fattigdom og ulikhet ikke er problemer i Norge, men de er mindre enn nesten noe annet sted. Det at vi er (nesten) rikest og likest i verden betyr at vi ikke kan sette masse billig arbeidskraft på for å øke velferd. Det er, i tillegg til en tiltagende eldrebølge, en av driverne til digitalisering og automatisering av så og si alt som kan digitaliseres og automatiseres (selv om mange, meg selv inklusive, synes det går noe tregt.) Riktignok har vi kunnet importere billig arbeidskraft fra tidligere østblokkland en stund, men siden de landene begynner å få det bedre, blir arbeidskraften derfra dyrere.
Et annet særtrekk ved Norge er at vi har spredt bosetning som nasjonal prioritet. Det er en grunn til at vi har 47 ruteflyplasser og svenskene, med dobbelt så mange innbyggere, har 33, for eksempel. Nordmenn liker å være for seg selv, både individuelt, i små flokker og nasjonalt (vi holder oss standhaftig utenfor EU, for eksempel.) Det er fint, men det blir vanskelig å opprettholde tjenester og stordriftsfordeler uteblir.
Så – små kommuner med begrensede ressurser. Hva skal til?
Penger, råvarer, og teknologi
Næringsutvikling handler om å utnytte det man har eller kan skaffe seg – kunnskap, naturressurser, eller penger, for eksempel. Tradisjonelt har næringsutvikling i Norge handlet om å skaffe penger (gjerne fra utlandet) for å utnytte naturressurser (i tur og orden sølv, fisk, tømmer, is, vannkraft, petroleum, sjømat og turisme, for eksempel). Alt dette er supert, men felles for alle disse naturressursene er at de trenger en masse arbeidskraft og ideer i begynnelsen – og dermed næringsutvikling, eller i alle fall arbeidsplasser. Etterhvert blir ting mer og mer automatisert og antallet arbeidsplasser blir færre og krever høyere utdanning. Datasentere, gruver og vindmøller, for eksempel, gir kortvarig glede for kommuneutvikling og kunnskapsnivå – etter anleggsperioden kan drift og bruk til stor grad automatiseres og fjernstyres, og dermed blir det ikke kunder i den lokale butikken eller barn på grendeskolen likevel.
Fra Norgebygda (NRK 2001)
Et næringsliv som krever en høyere grad av kunnskap (og dermed utdanning) er i seg selv et problem for mindre kommuner. (Det er et problem for land også: Bare se på lekkasjen av unge og utdannede fra New Zealand – svært likt Norge – til Australia.) Som illustrert i NRKs serie Norgebygda – fra 2001, fortsatt severdig – får man en prosess der ungdom søker ut for utdanning, finner seg partnere, og ikke flytter tilbake igjen av mange grunner, ikke minst at venner, karriere og kulturelle muligheter er mer tilgjengelig i større sentra. Som det sies i serien: Før flyttet man fordi man måtte, nå flytter flere fordi de vil.
Attraktivitet, ikke bare arbeidsplasser
Myken (foto: Myken.no)
Hvis folk først bestemmer seg for at de vil bo et sted, klarer de som regel å finne noe å gjøre. Myken, for eksempel, er en øy på Helgelandskysten med 22 fastboende – en av dem en tidligere kjemiprofessor fra NTNU som sammen med noen ferierende investorer startet et whiskydestilleri (og hadde vært gjennom ganske mange alternative forretningsplaner før den avgjørelsen.) Myken har i tillegg tre overnattingssteder og en ganske bra restaurant (på sommerstid).
Det går an.
Problemet er at selv om det er en viss gruppe mennesker som vil bo avsides, er de for få til å veie opp for alle dem som trekkes mot mindre grisgrendte strøk. Man kan rekruttere, men de som kommer har en tendens til å ville ha samme tilgang og kvalitet på alle tjenester som de har i byen – og often kan de kreve det med loven i hånden.
Richard Florida har skrevet mye om hvordan byer og regioner kan tiltrekke seg folk, og bruker uttrykket The Creative Class om den typen mennesker en by eller region må tiltrekke seg for å skape økonomisk utvikling. Han har primært skrevet om utvikling av post-industrielle byer i USA, men kanskje man kan hente noe derfra i mindre industristeder i Norge også?
Florida mener utvikling kommer fra fire drivkrafter:
Teknologi (målbart ved patenter og tetthet av teknologibedrifter)
Talent (utdanningsnivå og andel av befolkningen som jobber i «kreative» bransjer)
Toleranse (målbarhet på andel skeive, kunstnere og immigranter)
Territorium (egentlig «Territorial assets) som har med arkitektur, natur og kulturliv å gjøre.
I Norge har vi (etter min mening) byer som har fått dette til – som Drammen – og byer som ikke har klart det i den grad de burde – som Trondheim. Drammen var et høl inntil man fikk lagt gjennomfartsveiene i tunnel, etablert undervisningsinstitusjoner på Papirbredden, og ryddet opp i sentrum og langs elven. Trondheim er en super studentby, men har ikke i nærheten av så mange høyteknologibedrifter og kunstnere som man bør kunne forvente med NTNU og andre kompetansemiljøer midt i byen.
Suldal (og antakelig også andre kommuner) har tilpasset sin næringsutvikling til denne mer komplekse situasjonen, og forsøker å gjøre beslutningen om å flytte dit mindre vanskelig. Dels forsøker man å få bedrifter til å samarbeide om rekruttering, slik at det blir interessante jobber for begge parter i en husholdning. I tillegg har man forsøkt seg med rekrutteringsboliger, som man kan leie for å «prøvebo» i en tidlig fase, slike at transaksjonskostnadene blir mindre.
Næringsutvikling har blitt mer komplisert og mer fokusert på helhetlige verdier – hvordan kan man utvikle dette videre?
Kritisk masse og samhandlingsteknologi
Arbeidslivet er forandret – PC, Internett, mobil, elektronisk signatur, GPS, droner, videokonferanse og etterhvert kunstig intelligens har gjort og gjør at mye som før måtte gjøres lokalt nå kan gjøres hvor som helst fra. Det burde ha implikasjoner for næringsutvikling også – men hva?
Myken kan selge sine produkter over hele verden – og innbyggerne kan sikkert også motta mange kommunale tjenester digitalt. Endel av folkene bak Myken Whiskydestilleri har hytter eller hus der, og kan styre sine forretningsaktiviteter derfra – noen av dem har til og med meldt flytting dit, fordi de vil at skatteinntektene skal tilfalle en kommune som trenger den mer enn Oslo eller Bærum. Kanskje digital kommunikasjon kan gjøre næringsutvikling på små steder lettere? Og kanskje man kan skape fellesskap – rundt stedet i seg selv? På Myken samles hele befolkningen (bokstavlig talt) på landhandelen til kaffe og kake hver dag. På Flå, for eksempel, har man laget et «veksthus» der folk som fjernjobber kan sitte sammen og dele infrastruktur.
For noen år siden hadde jeg en student som var kommunalråd i en liten kommune helt nord i landet. Dette var før pandemien, og hun ivret for å få på plass en psykologitjeneste via videokonferanse. Ikke bare var dette bedre for pasientene – som slapp å bli sett når de gikk til psykologen, og ikke risikerte å møte vedkommende på lokalbutikken – men hun mente hun ville kunne finne mye bedre psykologitjenester enn hva hun kunne rekruttere hvis de måtte bo der oppe.
Med andre ord, teknologi tillater en hel del smarte løsninger. Men en digitale motorveien går begge veier. Hvordan kan en liten kommune – eller et lite land – sikre at digitalisering, automatisering og kommunikasjon blir et pluss?
Politikk og konsistens og den irske metoden
Næringsutvikling i Norge har en tendens til å handle om skatt, særlig formueskatt, og, vel, det finnes mange gode grunner til å tenke over det, men tilrettelegging og forutsigbarhet er kanskje enda viktigere.
Det landet som har hatt den desidert beste reisen fra avsides og fattig til sentralt og rikt er Irland. På 80-tallet var Irland fattig: Bruttonasjonalprodukt per capita på 64% av gjennomsnittet i EU, 17% arbeidsløshet, statsgjeld like stor som BNP. Ungdommen var relativt velutdannet – som en leder fortalte meg på slutten av 90-tallet, Irland var så fattig at det eneste de hadde råd til var utdanning, gratis og tilpasset bedriftenes behov – men måtte reise ut for å finne jobber.
Irske politikere ble enige om å gjøre noe, og begynte med å sette ned selskapsskatten til 8% for utenlandske selskap (over 20% for innenlandske), noe de fikk lov til av EU fordi landet var så fattig. Deretter satte man i gang en mangeårig kampanje for å legge til rette for Irland som en inngangsport til EU for amerikanske selskaper. En leder i IDA Ireland fortalte meg at han gikk ledelsen i store selskaper for å finne irske etternavn, hvorpå han besøkte dem og markedsførte hvordan Irland la alt til rette: Byggetillatelser, rekrutteringskampanjer, infrastruktur – han hadde til og med sørget for innreisetillatelse for bikkja til en administrerende direktør.
Resultatene kom fort, særlig fordi mange selskaper (Dell, IBM, Microsoft, Cisco og andre) ønsket å etablere seg et sted som snakket engelsk, var innenfor EU – og Storbritannia var en byråkratisk hengemyr for all nytetablering. Store amerikanske selskaper begynte å legge europeiske og etterhvert globale hovedkvarterer i Irland, ungdommen kom tilbake (med verdifull arbeids- og ledelseserfaring), arbeidsløsheten falt dramatisk, og «det irske mirakelet» var i gang.
Et sentral punkt her var konsistens og forutsigbarhet: Selv om Irland hadde skiftende regjeringer, var det bred enighet om nærlingslivsstrategien og godt samarbeid mellom arbeidstaker- og arbeidsgiversiden. Dette kom til uttrykk ta EU etterhvert ikke lenger tillot at Irland hadde separate skattesatser for utenlandske selskaper. I stedet for å sette skatten for utenlandske selskaper opp, satte man selskapsskatten lavt for alle (til 9%, såvidt jeg husker). Per i dag er skattesatsen 12,5%, Irland har høyere bruttonasjonalprodukt/innbygger enn Norge (om enn noe oppblåst fordi mange multinasjonale selskaper rapporterer overskuddene sine der), og en økonomi som suser av sted.
Konsistens og tilrettelegging, med andre ord. Mon tro om det er noe for mindre steder også (og kanskje et lite land som Norge?) Vil vi faktisk ha disse nye impulsene – og klarer vi, rent politisk, å være lydhøre og konsekvente nok til å få det til på lang sikt?
Og kanskje dette er lettere å få til i en kommune enn i hele Norge?
(En versjon av denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
En versjon av denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
De største feilene i ethvert prosjekt gjør man gjerne de første fem minuttene, fordi man tar forutsetninger og sementerer misforståelser man ikke vet at man har. AI og vibe coding kan kanskje gjøre noe med det.
Bilde konstruert ved denne prompten til Gemini: «please make me a pencil drawing illustrating and executive and a programmer discussing a vibe coding project»
I Comunita-nettverket har vi som regel møter hos en bedrift, der temaet er noe verten ønsker hjelp med. Men i neste møte har vi endret dette, og gjort et lite eksperiment: To bedrifter har gått sammen om å utforske noe nytt, og rapportere erfaringene.
Den ene bedriften har et problem: Bedriften leverer assistanse til kunder, både sine egne og for ulike partnere, hver av dem med ulike avtaler om hva slags ytelse sluttkundene kan forvente.
Den andre bedriften er et softwarehus som leverer ulike typer IT-tjenester, og som står overfor et teknologiskifte (fra tradisjonell til AI-støttet systemutvikling) som kommer til å ha nokså store konsekvenser for både hvordan man utvikler systemer for kunder og hvordan man tar betalt for dem.
Og hva er det vi har utforsket? Jo, vibe coding.
Vibe coding
Innenfor IT kan vi produsere buzz words fort, men vibe coding må være en eller annen rekord: Andrej Karpathy, en av grunnleggerne av OpenAI, introduserte begrepet for 11 måneder siden, og nå er det altså noe som brukes av helt vanlige bedrifter.
Vibe coding betyr at man skriver dataprogrammer ved å fortelle en språkrobot (eller, om du vil språkmodell) hva slags program man vil ha, hvorpå roboten skriver programmet for deg. Tanken er at alle skal kunne programmere – forøvrig noe som har vært et mål for enhver softwareleverandør siden programvare ble en vare: COBOL, av alle ting, var ment som noe ikke-programmerere skulle kunne gjøre.
Uansett: Hva tilfører Vibe coding som man ikke kunne gjøre før?
Det kanskje viktigste momentet er at man kan bruke svært kort tid (i dette tilfellet, en utvikler og ca. 25 timer) på å utvikle en prototype (eller, i alle fall, POC) som er god nok til at man har en omforent oppfatning av hva systemet skal gjøre og hva resultatet, sånn nogenlunde, kommer til å se ut som. Så liten ressursinnsats i en tidlig fase gjør at man slipper å spesifisere systemer før man begynner – utover korte møter – og man slipper å gjøre feil fordi folk forholder seg til en dynamisk beskrivelse i stedet for en mer statisk spesifikasjon.
Et annet aspekt er at diskusjonen om hva man skal gjøre føres mellom folk som er høyt nok oppe i organisasjonen til å ha overblikk – og foreslå løsninger ut over ren systemdesign. For å ta en parallel fra arkitektur: Snøhætta, et arkitektfirma med en rekke enestående bygninger på merittlisten, tar ikke oppdrag fra bedrifter med mindre bedriftsledelsen setter seg med med arkitektene en hel dag, der de klipper og limer og byggeklosser seg frem til hva slags bygg man skal ha. Dette gjør at mange misforståelser blir ryddet av veien tidlig – «å, var det det du mente» – mens de fremdeles er svært billige å korrigere, både hva gjelder penger og støtte mansjetter.
Om å velge riktig nivå
Bildet konstruert ved denne prompten til Gemini: «please make a pencil drawing illustrating the systems development concept of UI, business logic and data access». Presisjonen er ikke påfallende…
Nesten alle systemer som lages, må forholde seg til tre ulike dimensjoner: Grensesnitt, logikk og datastrukturer. (Også kalt «UI, forretningslogikk og dataaksess» hvis man kommer fra tradisjonell IT-utvikling, eller Model-View-Controller hvis man har studert informatikk.) Grensesnittet handler om hvordan systemet skal se ut og hvordan det passer inn i forhold til andre systemer, inkludert det mennesket som skal bruke det. Logikken handler om hvilke regler og rammebetingelser som gjelder. Datastrukturer handler om hvordan dataene er organisert og hvordan man kan komme til dem.
Et vanlig prosjekt ville måttet ha konstruert et grensesnitt (det begynner å bli mer og mer standardisert), legge inn forretningsregler («ikke tilby kunder en tjeneste som ikke er i kontrakten deres») og datatilgang (kanskje ved å konstruere en matrise av ulike tjenester og ulike kontrakter, og slå opp i den omtrent som indeksen til en søkemotor.) Ved å bruke vibe coding får man et kjapt system, der man bruker en variant av RAG til å lese kontraktene og tolke dem. Rent logisk vil dette si at brukergrensesnittet (og muligens grensesnitt mot andre systemer) blir formulert i naturlig språk («hvilke rettigheter har denne kunden»), forretningslogikken – i alle fall i prinsippet – uttrykt ved en «reward function» der språkroboten belønnes for riktige svar, og datatilgangen ordnet ved at språkroboten tolker kontraktene opp mot et multidimensjonelt semantisk koordinatsett.
Hovedfordelen med vibe coding og RAG er hastighet, hovedulempen er, som med så mange ting der språkroboter er involvert, mangelen på presisjon. En annen utfordring er oppdatering – hva skjer om det kommer en ny partner og, med det, en ny kontrakt? Da må man kanskje gjøre hele tolkningsøvelsen om igjen – og kan risikere at systemet ikke er konsistent over tid.
Suksesskriterier
Så langt har vi sett at vibe coding og språkroboter fungerer utmerket i en testfase – kan vi bygge et kjapt system, sjekke ut et konsept kjapt og billig, så vi blir enige om hva vi vil ha. Dette er ikke ulikt 3D-printing, som startet som noe man brukte til å bygge prototyper av bygninger, maskinkomponenter og annet. Etterhvert har 3D-printing blitt en produksjonsteknikk – kan vibe coding og språkroboter gå den samme veien?
Det finnes faktisk en måte å gjøre dette på uten å måtte manuelt sjekke ut den underliggende logikken i systemet – og det involverer god gammeldags statistikk og eksperimentering. Man kan ganske enkelt teste systemet opp mot det man gjør nå – og se om kunderådgivere med dette systemet til hjelp tar bedre beslutninger enn kunderådgivere som opererer alene.
Statistisk sett er dette riktig måte å gjøre det på – samtidig vil jeg tro at en ansvarlig leder ville følt seg nokså nervøs ved oppstart. Vi har en naturlig tendens til å vurdere nye ting ikke opp mot hva man allerede gjør – ofte manuelle prosesser fulle av ikke-innrømte feil – og i stedet insistere på at ethvert nytt system skal være 100% sikkert, feilfritt og etterrettelig.
Som så meget annet mennesker gjør, er ikke dette mulig, og heller ikke ønskelig. Som Daniel Kahneman har skrevet i sin eminente bok Thinking, Fast and Slow: Et menneske som skal gjennomvurdere alle beslutninger i stedet for å være følelsesstyrt, vil aldri klare å ta noen beslutninger. Slikt sett er den effektive omtrentligheten til en språkrobot kanskje en mulig løsning på den backlog’en enhver organisasjon med gamle systemer sliter med.
Og dialogen før man starter vil i alle fall hjelpe med de feilene man gjerne gjør i løpet av de første fem minuttene.
I desember i fjor var jeg med på en interessant podcast med Bente Sollid og Christian Brosstad, der temaet var hva som vil skje med arbeids- og forretningslivet nå som AI kommer inn for fullt. Temaet var opprinnelig «KI-blodbad i arbeidslivet» eller noe slikt, men både Bente og jeg likte ikke den tittelen, selv om den er skikkelig klikkbar. Det ble en lang og vidtfavnende samtale, vi endte opp med å diskutere forretningsmodeller en hel del. Etterpå sa Bente at vi kanskje burde ha brukt mer tid på hvilke egenskaper og kunnskaper som blir viktige i en verden med mye AI – med andre ord, hva skal du bli flink i for fortsatt å ha en jobb og en god inntekt?
Så her er mitt forsøk på å starte den diskusjonen, og det har jeg tenkt å begynne med å observere at vi har hatt denne diskusjonen før – for sånn omtrent 20 år siden, for å være nøyaktig. Den gang var ikke trusselen mot arbeidslivet AI, men globalisering – hva i all verden skulle vi gjøre når billig arbeidskraft i India og Kina kom og tok alle IT- og industrijobbene? Det manglet ikke på spådommer om hvor vanskelig det ville bli å beholde jobbene i vesten, når milliarder, bokstavlig talt, av indere og kinesere og andre sto klare til å overta.
Den boken som dominerte den diskusjonen var Thomas Friedmans The World is Flat – du finner mitt sammendrag her – som hevdet at jorden var i ferd med å bli flatere, i den forstand at åpnere arbeidsmarkeder og finansmarkeder, hypereffektiv kommunikasjon og billig og rask transport ville gjøre verden til et sted der ting der alle nasjoner kunne konkurrere. Dette har vist seg å være en sannhet med modifikasjoner, men arbeidslivet er uten tvil endret, selv om det i alle fall for USAs vedkommende har handlet mer om automatisering av industriproduksjon enn outsourcing.
Nuvel, den samme Friedman diskuterte i alle fall hvordan man skulle ruste seg for å overleve i en verden der man konkurrerer globalt – og hans argumenter har en viss overføringsverdi når vi diskuterer hva som kommer til å skje når AI står for automatiseringen. Friedman mener at de som vil overleve er dem hvis jobb ikke kan outsources – the untouchables. Han mener det er fire typer av dem:
De unike: Folk som er unike og ikke kan kopieres fordi ingen andre kan gjøre det de gjør – Erling Haaland, for eksempel, eller Taylor Swift.
De spesialiserte: Folk som har en spesialkunnskap, som spesialiserte advokater, hjernekirurger, andre hvis arbeid rett og slett ikke kan automatiseres.
De forankrede: Folk som gjør noe lokalt og tilpasset, som frisører, servitører, helsepersonnel og rørleggere.
De fleksible: De som klarer å lære seg noe nytt, når hele eller deler av den jobben de utførte før blir automatisert. Den siste gruppen er den viktigste, fordi også de tre andre vil få deler av jobben sin automatisert.
Hovedmeldingen den gang – og i dag – er at man må hele tiden oppgradere seg, hele tiden lære, for å være relevant. Nå er det riktignok ikke en smart og ambisiøs inder som står og vil ha jobben din, men en mindre smart språkmodell som vil gjøre den delen av jobben din som bare krever middelmådige kunnskaper.
Problemet med å flytte masse arbeid til India var at man i stor grad undervurderte transaksjonskostnadene – det man vant ved å ha billige programmerere tapte man i den tiden det tok å spesifisere hva man ville ha gjort, i kulturforskjeller og tidssoneproblemer. Det betyr ikke at det ikke kan være lønnsomt, men at organisasjonen som skal flytte noe bør være stor nok til at man har penger og personell til å administrere det hele – og at man er stor nok til at man er en interresant kunde derover.
Slik er det kanskje med språkmodellene også: Riktignok kan man automatisere mye, men for mange (i hvert fall for meg) er jobben med å følge med på hva assistentene gjør så stor at jeg heller gjør det selv. Og uansett hvor bra en språkmodell er – det blir ikke helt som man vil ha det.
Kanskje det tyder på at jeg kommer til å overleve i det fremtidige arbeidslivet likevel?
For tiden leser og diskuterer jeg mye om kunstig intelligens (som alle andre, for den saks skyld, men jeg har sabbat og nye – i dette tilfellet, ikke så nye – teknologier er jo det jeg driver med og underviser om.)
En av refleksjonene jeg har rundt det er «du verden, så lite ting har endret seg.»
Jeg havnet først opp i diskusjonen om kunstig intelligens på 80-tallet, da jeg jobbet i IT-avdelingen på BI og var heldig nok til å ha en sjef (Erling Iversen) som leste mye og var plugget inn i AI-diskusjonen slik den var den gang. Via ham, Fred Wenstøp, etter hvert Charles Stabell og Øystein Fjeldstad ble jeg introdusert for bøker som Heins Pagels Dreams of Reason, Bolters Turing’s Man, Hofstadters Gödel, Escher, Bach (som Erling pleide å si, «det finnes to slags IT-folk, de som har lest Hofstadter og de som ikke har gjort det.»), Rumelhart og McLellands Parallel Distributed Processing og noe senere Resnicks Turtles, Termites and Traffic Jams. (Blogget om her.)
Alle disse bøkene, og de ideene de inneholder, kan hjelpe oss å forstå hva kunstig intelligens er og hvordan vi skal håndtere den. Den forståelsen er viktig, for i dag begynner AI å blir allemannseie (omtrent som PCer på sent 80-tall, internett i andre halvdel av 90-tallet, mobil og sosiale medier på 2000-tallet) og jeg ser i alle fall at de samme misforståelsene og forventninger som var gjeldende da, også gjelder for AI.
Da kan det være verdt å se litt på tidligere diskusjoner om AI, for nesten alt man ser av argumenter har vært fremført før og har ikke mistet gyldighet selv om språkmodeller nå kan kjøres i stedet får bare å beskrives. Den viktigste kritikken av AI – og særlig om maskiner noengang kunne oppnå en eller annen form for intelligens – kom fra Hubert Dreyfus, en filosof som satte spørsmålstegn ved mange av forutsetningene som lå til grunn for tanken om at bare maskinen blir kraftig nok, blir den smart. Dreyfus artikulerte tidlig det som blir klarere og klarere etterhvert som nevrale nettverk blir allemannseie: At hjernen ikke er en datamaskin, selv om deler av den kan simuleres av et nevralt nettverk uten kontekst; og at et nevralt nettverk ikke er en hjerne, selv om det kan produsere noe som ved første øyekast ser ut som intelligens. Tenking er ikke beregning, og beregning er ikke tenking, ganske enkelt.
Jeg fant forleden en film på Youtube som beskriver og illustrerer mange av Huberts poenger, særlig det at kunnskap lages i en kontekst og ikke kan reproduseres fritt fra den. Filmen tar for seg en rekke kunstnere og andre med dyp kunnskap, og viser hvordan den kunnskapen og resultatene av den skjer i samspill både med ens egen kropp og omgivelsene. Som Dreyfus sier i filmen: «the source of meaning in our lives isn’t in us – that’s the Cartesian tradition – and it isn’t in some supreme being, but it is in our way of being in the world.» (https://youtu.be/fcCRmf_tHW8?t=4629).
Et av utsagnene synes jeg er spesielt interessant: «One of the dangers of technology is that it relieves us of the necessity of developing skills.» Ideer og kunnskaper kommer ofte som et resultat av begrensninger, av hindre som man må komme over. Med kortere og kortere avstand mellom ønske og oppfyllelse, vil vi ende opp som bortskjemte døgenikter alle sammen?
Sannsynligvis ikke, for vi vil ha kontekst og interaksjon. Plus ça change, plus c’est la meme chose…
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Men enda vanskeligere er det å implementere strategi – å gå fra overordnede mål til å spesifisere hva folk skal gjøre i hverdagen. Mange organisasjoner gjør dette ved å formulere konkrete målsettinger. Dette gjøres fordi generelle strategier gir liten konkret styringsinformasjon: Hvis du jobber på regnskapskontoret, er det ikke alltid så lett å forstå hva en strategi om at bedriften skal være «global, digital og bærekraftig» – for å sitere en bedrift jeg vet om – betyr når du er ferdig med morgenkaffen.
Bedrifter har gjerne en masse ulike kontrollsystemer, og strategisk endring gjennomføres ved at ledere implementerer strategi ved å velge et kontrollsystem og gjøre det aktivt:
In situations of strategic change, control systems are used by top managers to formalize beliefs, set boundaries on acceptable strategic behavior, define and measure critical performance variables, and motivate debate and discussion about strategic uncertainties. In addition to traditional measuring and monitoring functions, control systems are used by top managers to overcome organizational inertia; communicate new strategic agendas; establish implementation timetables and targets; and ensure continuing attention to new strategic initiatives. (Simons, 1994)
Kontrollsystemer gjør det strategiske konkret, og bedrifter med klare strategier har gjerne klare målesystemer: Microsoft, for eksempel, har en strategi om å ta i bruk de AI-basert systemene de selger, og måler (og belønner) i disse dager sine mellomledere på i hvor stor grad de klarer å flytte systemutviklingsarbeidet – og annet arbeid – fra håndkoding til automasjon.
Fra overordnet til konkret
Men hva er et godt mål, og hvordan kommer man frem til det? I utgangspunktet burde en klar og god strategi være selvforklarende, men slik er det ganske enkelt ikke. Ting må gjøres konkret, og resultatet av den prosessen har mange navn: KPI, OKR, MBO, BSC og andre TBF‘er. I Norge akkurat nå er OKR (Objektives and key results, popularisert av Andy Grove i Intel engang på 80-tallet) mest populært. Felles for alt dette er at man setter mål som er smarte, hvilket (på norsk) vil si at de er
Spesifikke: Klart avgrenser hvilke aktiviteter som berøres
Målbare: Definerer, eller i alle fall indikerer, noe som kan måles og blir målt
Ansvarsplassert: Spesifiserer hvem som har ansvaret for å oppnå målet
Realistiske: Mulige å påvirke for dem det gjelder, og kan oppnås med de ressursene som er tilgjengelige
Tidsbestemt: Gjelder innenfor en viss tidsperiode
Dette er temmelig tøffe kriterier, og de fleste ledere og mellomledere sliter med å formulere målsettinger som tilfredstiller alle disse kriteriene.
Man får det man måler, og bare det
Det er besnærende å tenke at bare man løser definisjonsproblemet, har man løst implementeringsutfordringen. Men vi mennesker er ikke maskiner: Får vi mange mål å forholde oss til, tenderer vi til å prioritere mellom. Og får vi svært konkrete mål, vel, så produserer vi det som konkret måles, ikke det underliggende fenomenet som er ment å måles.
BSC – balanced score card – ble skapt av Robert Kaplan og David Norton på tidlig 90-tall som en reaksjon på den utstrakte bruken av rene finansielle mål. Mye av kom i forlengelsen av Johnson & Kaplans svært inflytelsesrike Relevance Lost. Den boken viste at etterhvert som mer og mer av industriell produksjon ble automatisert, ble lønnsomhetsberegninger mer og mer et spørsmål om hvor mye av salgs- og administrasjonskostnader (GS&A) som ble tillagt enhetskostnaden. Resultatet var at man masseproduserte for mye, overoptimaliserte produksjon, og at måleinstrumentene ikke lenger ga styringsinformasjon for store deler av organisasjonen.
BSC innførte ikke-finansielle mål, relatert til kundetilfredshet, læring og interne prosesser, og ble tatt i bruk av mange organisasjoner. Dette skjedde ikke uten utfordringer – finansielle mål hadde en tendens til å trumfe alt annet i nedgangstider, for eksempel. I tillegg produserte systemet mange mål, og det viste seg at vi mennesker har problemer med å forholde oss til flere ytelsesdimensjoner samtidig. Da velger vi gjerne et av målene og overfokuserer på det: Selgere som blir belønnet for å øke salget, for eksempel, selger som bare det uten å undersøke om kjøperne trenger produktet eller er i stand til å betale for det.
Jeg er blitt fortalt at i Sovjetunionen, der finansielle mål ble undertrykket, ble møbelprodusenter målt på antall tonn møbler de produserte i året. Resultatet ble svært tunge møbler.
Den industrialiserte kunnskapsarbeideren
Detaljerte målekriterier brutt ned på grupper og kanskje til og med individer kommer fra en top-down tankegang om hva strategi er: Ledelsen ser på organisasjonen som et verktøy, og forteller organisasjonen hva den vil ha, ofte ved at ledelsens egne mål er satt av et styre som har godkjent en overordnet strategi. En slik tankegang er industriell, og egner seg best i situasjoner der målekriteriene er lett observerbare og kvantifiserbare, og der fremgangsmåten for å oppnå dem er relativt kjent.
Med andre ord: Man ber organisasjonen om å gjøre noe ved å sette kriterier for hva som er bra og hva som ikke er det.
Men hva med kunnskapsarbeid? Hittil har ikke kunnskapsarbeid blitt industrialisert i særlig grad – primært fordi systemene som skal gjøre det ikke har funnets. Riktignok har endringer i mål gjort at mange organisasjoner har fått et endret arbeidsmiljø – journalister har gått fra å få artikler antatt til å publisere ting optimalisert for klikking, for eksempel – men automatisering av reellt kunnskapsarbeid har latt vente på seg.
Fremtidens kunnskapsorganisasjoner vil ha digitale medarbeidere på lik linje med mennesker (Ide og Talamàs, 2025). Interaksjon med en digital medarbeider – la oss kalle det en språkrobot (Arnulf, 2025) – skjer ved prompting: Man spesifiserer hva man vil ha ved å spørre, og fortsetter å spørre til man er fornøyd med svaret.
Hva om vi snur litt på flisa – kan vi lære å sette gode mål for menneskelige medarbeidere ved å finne hva som er gode mål for de digitale aktørene?
Hva med å behandle menneskelige medarbeidere som digitale?
Det finnes mange utsagn om hva som er god prompting, men felles for dem er en oppbygging som sier noe om
hvem språkroboten skal være
hva den skal levere
med hvilke ressurser det skal gjøres
hva som er et bra resultat
For eksempel kan en leder med ansvar for digitalt grensesnitt i en bank tenkes å gi følgende prompt til en språkrobot:
Du er en UX-utvikler i et finansselskap. Basert på den koden som allerede er skrevet og annen kode fra andre systemer, skriv et program som tillater besteforeldre å kjøpe aksjefond til barnebarna sine som jule- eller bursdaggave. Koble dette systemet mot CRM-systemet slik at besteforeldrene blir varslet før jul og bursdager, men hold alt innenfor GDPR-regelverket.
Dette utsagnet sier noe om hvem man forventes å være, hvilke ressurser man har, hva som skal gjøres, og hva som er kriteriet for god måloppnåelse.
Eller, med andre ord, en målsetting og et resultat – men skrevet som en tekst i stedet for et numerisk målekriterium.
Dette er ikke så eksotisk som det høres ut: Amazon er kjent for at man i ledergruppen der ikke produserer Powerpoints, men i stedet skriver et sekssiders memo som leses i fellesskap (så alle må lese grundig) og som danner grunnlag for diskusjoner og beslutninger.
Men metoden er interessant fordi man kan lære noe om hvordan man skal formulere mål (og strategi) ved å måtte formulere det for en språkrobot, før man formulerer det for et menneske.
Og det kan kanskje være språkrobotens bidrag til å heve kvaliteten i det som gjøres i en organisasjon, ikke bare kvantiteten.
Ide, E., & Talamàs, E. (2025, March 3). Artificial Intelligence in the Knowledge Economy. Stanford Digital Economy Lab. https://arxiv.org/pdf/2312.05481
Johnson, H. T., & Kaplan, R. S. (1987). Relevance Lost: The Rise and Fall of Management Accounting. Harvard Business School Press.
Simons, R. (1994). How new top managers use control systems as levers of strategic renewal. Strategic Management Journal, 15(3), 169–189. https://doi.org/10.1002/smj.4250150301
Prompts:
De tre tegningene er generert av ChatGPT 5.1, med følgende prompts:
Make a pencil drawing of a female CEO thinking about strategic objectives
Make a pencil drawing of a systems developer prompting an llm to produce a financial investment system
Make a pencil drawing of a manager carefully crafting a six-page memo, like they do at Amazon
Siden tidenes morgen har store bedrifter slitt med antikverte kjernesystemer, vanskelige å endre og vanskelige å få data ut av. Nå har noen av dem begynt å få orden på det – og hva skjer da?
ChatGPTs versjon av en COBOL-programmerer – de har tydeligvis bare tre fingre per hånd.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Museumsgjenstanden i kjelleren
De grunnleggende datasystemene man bruker i store bedrifter – særlig banker og forsikringsselskaper – ble først laget på sekstitallet. De gjorde helt grunnleggende ting, som å holde orden på hva kundene hadde betalt og fått, og var programmert enten i maskinspråk, Assembler, eller (vanligvis) COBOL. COBOL – designet av ingen ringere enn kontreadmiral Grace Hopper – har vist seg å være forbausende standhaftig: Det er lett å programmere i, men når programmene blir store, er det forbausende vanskelig å endre dem. Etterhvert som ny teknologi har kommet, har de fleste bedrifter utviklet en arkitektur der de har noen svært gamle kjernesystemer – ofte i COBOL – og en mengde andre systemer rundt kjernen – systemer som kommuniserer med kjernesystemet men ikke endrer det.
Dermed ender man opp med et monster i kjelleren – et gammelt system ingen tør røre, delvis fordi det er mangel på folk som kan, dels fordi enhver endring har forgreninger inn i hundrevis, kanskje tusenvis av andre rutiner i egen og andres organisasjon. Siden ingen tør å røre det, bruker man systemene rundt – for dataanalyse, for eksempel, dumper man det som har skjedd i kjernesystemet ut i ulike lagringsløsninger, og gjør analysene derfra.
Fordelen med å trekke data ut fra systemet og gjøre det tilgjengelig er at ulike deler av organisasjonen trenger ulike typer analyser – og har man dataene separat, man man gi dem til folk og la dem gjøre hva de vil. Ulempen er at – med mindre man har en selvdisiplin av en annen verden – de ulike delene av organisasjonen snart skaper sine egne begreper og sine egne bilder av hvordan verden ser ut. Det betyr at uttrykk som «lagerbeholdning» eller «lønnsomhet» har ulike betydninger for ulike deler av organisasjonen, som jo kan gjøre det vanskelig å bli enige om ting. «Single source of truth» er et viktig prinsipp fra informatikk – masterdata skal lagres kun et sted og det skal aldri være tvil om hva som er riktige data. Dette har etterhvert blitt et begrep innen ledelse også, og en viktig motivasjon for å la kjernesystemer og dataanalyse nærme seg hverandre.
Heisenberg i regnskapet
En annen effekt – og viktig motivasjon – for å hente data fra kjernesystemene er oppdatering. Det er en klisje at all regnskapsanalyse handler om å se på fortiden for å predikere fremtiden – ofte sammenlignet med å kjøre bil ved å se i bakspeilet. Jo fersker data, jo bedre styring.
Eller kanskje ikke?
De som har sett Breaking Bad, husker sikkert at hovedpersonen Walter White brukte pseudonymet Heisenberg. Det er ikke tilfeldig – Werner Heisenberg er mannen bak usikkerhetsprinsippet, som sier at (innen kvantemekanikk) er det ikke mulig å presist måle både posisjon og hastighet for en partikkel samtidig. Jo mer presist du måler hvor en partikkel er, jo mindre vet du om hvor fort den beveger seg, og omvendt.
Innen forretningslivet må vi hele tiden ta beslutninger som krever målinger av et eller annet slag – for en bank, for eksempel, må man vurdere kredittverdigheten til en bedrift. Den samme banken vil gjerne også kunne finne ut av hvilke privatkunder som kommer til å flytte lånene sine eller slutte å betale dem – eller mer presist kunne vurdere likviditetsbehov på kort sikt, kanskje fra minutt til minutt.
Når data blir øyeblikkelig tilgjengelig, vil vel dette bli lettere?
Lager er ikke lager
Vel, ting er ikke så enkelt. La oss ta et enkelt begrep, som uttrykket «lager» – er produktet på lager?
Skal du kjøpe noe på IKEA, for eksempel, kan du jo gå på deres webside og se om det ønskede produktet er i butikken – bare for å finne at det ikke er der likevel når du kommer dit. Sjansen for at lagerbeholdningen er feil, er mindre nå enn før, fordi man har fått raskere oppdateringer. For noen år siden ble lagerbeholdningen oppdatert daglig, i en batchprosess. Så koblet man det til POS-systemet i kassen, og dermed ble tallet oppdatert når noen gikk gjennom kassen og betalte for det.
Nå er IKEAs forretningsmodell den at du henter det du skal ha, for så å bruke masse tid på å vandre rundt i en labyrint eller stå i kø mens du fristes med lysestaker, varmelys og marsipan. Den flatpakken du har på handlevognen, er fortsatt – i følge IKEA – på lager, i den forstand at de ikke har solgt den ennå. Men den er ikke på lager for neste kunde, som kommer til en tom hylle – medmindre IKEA monterer strekkodelesere eller vekter på lagerhyllene sine.
Begrepet «lagerbeholdning» er altså ikke bare tidsavhengig, men også forskjellig for forskjellige brukere, og årsaken er ikke slapp datadisiplin, men genuine forskjeller i informasjonsbehov. Dermed blir det til at man må endre beregningsmetode ikke bare ut fra hvilket tidspunkt man ønsker data på (historisk, i sanntid, eller i fremtiden) men også ut fra hvem som spør (kunde, selger, markedsansvarlig, produsent, eller den som er ansvarlig for lagerlokalene.)
Dermed blir noe så enkelt som «lager» et begrep som involverer ikke bare tall, men også relasjoner mellom ulike deler av verdikjeden, der systemene er simuleringer av virkeligheten.
Med andre ord: Jo mer presist man ønsker å måle et begrep, jo mer presist må det defineres.
I disse dager vekker det endel oppsikt at kunnskapsminister Kari Nessa Nordtun foreslår å ta vekk skolefag fra de første skoleårene – små barn trenger å leke, skolen skal være noe man gleder seg til, og den alarmerende økningen i skolefravær for de små bekymrer.
Nessa baserer seg på forskning her, og det er gledelig. Det er også gledelig at forskningen slår igjennom politikken i et felt der det finnes mye synsing. Ekstra gledelig er det at min kone Kristine Damsgaard endelig får gjennomslag for noe hun har kjempet for lenge: At vi må gjøre betydelige endringer i særlig de første skoleårene fordi skolen har utviklet i en retning mange barn ikke har forutsetning for å henge med på.
For halvannet år siden holdt Kristine et foredrag på Arendalsuka der hun gjorde rede for hvordan vi kan redusere ufrivillig skolefravær – at leseopplæring er blitt forsert, at barn mister struktur i hverdagen fordi skolen er blitt mer som et studium, at vi har klemt inn to ekstra skoleår for de små. Det er vel verdt å poste her, og gir bakgrunnen for det som kunnskapsministeren nå foreslår.
Her om dagen var jeg på 30-årsjubileet for det kommersielle Internettet i Norge, arrangert av Erling Maartmann-Moe og endel andre gründere fra New Media Science. Tidspunktet var litt omtrentlig og Internett var jo tilgjengelig lenge før det (selv sendte jeg, ahem, min første internasjonale e-post i 1985 og la ut en kommersiell webside (for CSC) høsten 1994, men for all del…)
Uansett, min gamle meddebattant Håkon Wium Lie kunne gledestrålende vise frem en PDF av Norges Lover (med rødt omslag, til og med), og i går la han nyheten ut (på Facebook, av alle steder). Her er et screenshot:
Dette er en langvarig prosess, like gammel som det offentlige Internettet, og jeg har skrevet om det før, senest i 2018. Det er helt utrolig at man som norsk innbygger må gjennom en 12000-kroners betalingsmur for å få tilgang til de reglene som forteller hvordan vi skal komme oss gjennom liv og levnet uten å bli straffet for det. Fremdeles er rettspraksis (dommeres fortolkning av lovene, som er nødvendige for å forstå anvendelsen av relativt tørre og presise paragrafer) bak betalingsmurer, men det vil nok bli sluppet fri en gang, det også. Vi hadde den samme debatten om kartdata – Kartverket tjente noen få millioner på å selge kartdata. De er i dag frie, så vidt jeg vet, forhåpentligvis fordi den samfunnsmessige nytten av å slippe dataene fri var mye større enn de småpengene et offentlig organ kunne tjene på å leke butikk.
I alle fall: Gratulerer, Håkon! 30 år før din tid, som vanlig.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Om forretningsutvikling for plattformer – og når den går for langt
For noen år siden handlet nesten all forretningsutvikling om å gå fra å selge produkter eller enkelttjenester til å bli en partner med kunden. Denne utviklingen var dels drevet av behovet for å skape differensiering og tilknytning i en verden der standardtjenester blir sammenlignbare og dermed prissensitive, men også muliggjort av teknologi som CRM-systemer.
Neste trinn i utviklingen – som mange bedrifter holder på med nå – er at man forsøker å bli en plattform: En tjeneste som skaper verdi ikke bare ut fra hva kundene kan bruke den til, men også ved at den har elementer av nettverkseffekter, slik at den blir bedre jo flere kunder som bruker den. Disse effekten kan være direkte – kundene kommuniserer gjennom din plattform, eller indirekte, ved at den kunnskapen du får gjennom å ha mange kunder på plattformen gjør at du kan lage tjenester ingen andre kan.
Det å starte en plattform er vanskelig, siden man må ha noe å tilby kundene inntil plattformen – gjerne de andre kundene – er stor nok eller viktig nok til å være en attraksjon i seg selv. Jeg pleier å snakke om at man må ha en «killer» av noe slag – en funksjon eller en gruppe – men det enkleste er nok å allerede ha et nettverk, hvilket er grunnen til at store nettverk som Google eller Facebook kjøper voksende nettverk som YouTube eller Instagram.
Nuvel. Men sett at man klarer å bygge begynnelsen til en plattform ved å sette opp noe, en plattform, som adresserer et todelt marked – hvordan vidererutvikler man den?
Reach and range
Når man ser på verdien av en plattform, er det to dimensjoner som står i sentrum: Reach and range [4] – eller bredde og dybde, som jeg forsøksvis kaller det på norsk.
Bredden er hvem du kan nå gjennom plattformen. Det handler både om hvor mange som bruker den, og hvem brukerne er. Det er lett å se på antall brukere som det sentrale målet her, men vel så viktig kan det være hvem disse brukerne er. Finn.no, for eksempel, har klart flest brukere i Norge, men skal du selge brukte klær, er det Tise som gjelder – de har ikke så like mange brukere som Finn, men hvis det er brukte moteklær du skal selge, har de alle de brukerne som betyr noe.
Dybden handler om hva du kan gjøre på plattformen: Hvilke tjenester som tilbys. Plattformer starter gjerne med å tilby en sentral tjeneste, for deretter å utvide med andre ting etterhvert. Vipps, for eksempel, hadde betaling mellom privatpersoner som eneste tjeneste til å begynne med, men har etterhvert lagt til butikkbetaling, identifisering (innlogging) og muligheten til å fotografere regninger og betale dem.
Utviklingsproblemer
Forretningsutvikling for plattformer har i hovedsak altså to dimensjoner – og man kan utvikle seg i både bredde og dybde: Gjøre plattformen attraktiv for flere kunder (gjerne ved å finne nye kundegrupper som komplementerer de man allerede har), eller å legge til flere og flere tjenester slik at kundene etterhvert kan gjøre alt gjennom plattformen. Slik øker kundenes avhengighet av plattformen – noe som man i alle fall i Internetts begynnelse ble kalt stickiness.)
Begge deler kan være problematisk.
Gratis inntil videre
Et problem man kan få, er at fordi plattformer tjener penger på ulike ting, vil deres jakt på inntekter føre til at de tilbyr gratis det andre tjener penger på. Ta Vipps og Finn, for eksempel: I en periode forsøkte Finn å innføre en batetalingstjeneste kalt SpID (Schibsted Payment ID) som skulle håndtere innlogging og betalinger for bl.a. Aftenposten, Finn.no, VG og endel andre tjenester. Det ble aldri noen suksess, men fikk i alle fall Vipps til å holde sine priser nede og innby til samarbeid med mange andre tilbydere.
Finn har hatt større suksess med å observere hva andre konkurrenter gjør, og så tilby det samme til sine kunder, enten ved å utvikle det selv, eller ved å kjøpe opp eller inngå allianser med oppstartbedrifter som gjør Finn-plattformen bedre.
Selskaper som ikke har hatt suksess her er for eksempel Telenor, som har forsøkt mange ting for å få større profitabilitet ut av sine dyre og omfattende nettverk, bare for å finne at de blir presset tilbake til en kostnadskonkurranse for grunnleggende trafikk. Mens Telenor hadde ressurser, kunne de ha bygget opp en rekke tjenester – alarmsystemer, helseapplikasjoner, videokonferanse, underholdning – men de hadde ikke apetitten for så store investeringer utenfor kjernevirksomheten. De hadde også brent seg på endel investeringer innen underholdning, der det faktum at Telenor var store i Norge ikke hadde noen betydning for de store underholdningsprodusentene, som forhandler priser for innhold over hele verden. Telenor er i dag – i likhet med de fleste telekommunikasjonselskaper – en skygge av seg selv, redusert til å levere basistjenester fra en åttendedel av sitt formidable hovedkvarter på Fornebu.
Kort sagt handler enshittification om at plattformtilbydere, i et forsøk på å øke og opprettholde sin profitt, lokker til seg nye brukergrupper ved å selge de brukergruppene de allerede har, for så å gjenta prosessen når den nyeste brukergruppen har gjort seg avhengig av plattformen.
Here is how platforms die: First, they are good to their users; then they abuse their users to make things better for their business customers; finally, they abuse those business customers to claw back all the value for themselves. Then, they die.
Facebook er et typisk eksempel: Til å begynne med et sted du gikk til for å snakke med venner og forbindelser, som nå er blitt et sammensurium av innhold og annonser du ikke har vil ha, til fortrengelse for det du egentlig vil ha, siden det ikke betaler.
Balanse i alt
Markedsføring handler om å skape og beholde kunder. Problemet for plattformer er at det er ikke alltid klart hvem kundene er, siden man ofte står overfor tosidige markeder [3,5] (selgere og kjøpere, for eksempel) der den ene siden genererer det meste – ofte hele – inntekten. Dermed blir kan det bli vanskelig, særlig i nedgangstider, å opprettholde interessene til den kundegruppen som ikke generer inntekter over tid. Denne balansen mellom langsiktig tenkning og kortsiktig profitt er imidlertid ikke noe nytt for forretningsutvikling generelt – hvor mye kvalitet man skal legge i produkt og kundeservice, for eksempel, har alltid vært der som en balanse man må forholde seg til.
Så, for all del, øk bredde og dybde i det du gjør med plattformen din, men ikke glem årsaken til at kundene kom dit til å begynne med – for å få utført en basisfunksjon, og, til en stor grad, å forholde seg til hverandre.
[5] G. Parker and M. Van Alstyne, “Two-Sided Network Effects: A Theory of Information Product Design,” Management Science, vol. 10, pp. 1494–1504, 2005.
Med alder og det engelskmennene kaller en «sedentiary lifestyle» kommer risiko for høyt blodtrykk. Dermed må man gjøre noe med kostholdet, og det viktigste tiltaket (bortsett fra ikke å røyke og få nok mosjon», men det gjelder uansett) er å spise mindre salt.
Og det er jammen ikke lett.
Salt har, som Mark Kurlansky skriver om i «Salt» – en bok jeg forøvrig anbefaler, i likhet med «Cod» – en lang historie og har både vært valuta og basis for handelsruter, forretningsimperier og oppdagelser.
Men jammen er det ikke lett å bli kvitt saltet fra maten.
Nå skal det sies at jeg elsker salt – Maldonsalt, for eksempel, som er nydelig på all slags mat. (Maldonsalt uttales forøvrig «måldn», ikke «maldåån» – det er engelsk, ikke fransk.) Akkurat det er det lett å gjøre noe med. Og det finnes jo masse alternative krydder og ingredienser man kan bruke for å gjøre maten litt mer spennende.
Eller gjør det det?
Sitronpepper, for eksempel, trodde jeg bestod av sitron og pepper. Men neida, i følge ingredienslisten er det 43% pepper, noe sitron – og 43% salt! Soltørkede tomater har salt som tredje største ingrediens, etter tomater og solsikkeolje (som heller ikke er helt bra for blodtrykket). Ost, pølse, oliven, alle mulige krydderblandinger, og til og med kyllingfilet inneholder altså salt, i mindre eller (i forbausende mange tilfeller) ganske store mengder.
Råvarer er ikke råvarer lenger, tydeligvis.
Det samme gjelder matlaging på restauranter: Jeg forsøker å la meg inspirere av matlagingsvideoer på nett, og har funnet masse godt som jeg eksperimenterer med. Forbausende mange av dem inkluderer en neve salt i maten. Jeg har hørt at skal du lage god mat, må du tilsette fett, salt, sukker eller alkohol.
Nå er det jo slik at man skal ikke kutte ut salt, bare redusere saltinntaket. Så jeg kommer sikkert til å klare meg fint bare ved å gi slipp på Maldon-salt og spekemat og litt andre ting.
Man trenger jo ikke så mye salt, og smaken av salt er noe man venner seg til. Jeg har ikke vært klar over hvor mye salt jeg har brukt, og min kone har påpekt at jeg salter en hel del mer enn hun gjør. Så avvenningen skal nok gå greit.
Men jeg hadde ikke drømt om at det skulle være så vanskelig, rent operativt, å kutte ut noe så enkelt som salt.
Alt som er gøy, heter det, er enten kriminelt, umoralsk eller fetende.
Og, tydeligvis, salt.
Jeg får ta hele greia med en klype… nei det kan jeg heller ikke gjøre.
Kjapt innlegg her med en liten anbefaling av denne filmen, som gir en kjapp forklaring av ulike økonomiske teorier – eller “skoler” om man vil – gjennom tidene. Som halvstudert økonom kunne jeg jo ønsket meg litt mer dybde rundt f.eks. transaksjonskostnader og er kanskje også litt uenig i noen av klassifiseringene, men dette setter nok mye på plass.
Og, ikke minst, gir en oversikt til den som måtte tro at økonomisk teori kun handler om penger eller politikk.
Denne sommeren har vært preget av komplikasjoner i helseveien både for min nybakte kone og meg selv, men vi kommer oss. En effekt av dette har vært at man har brukt forferdelig mye tid til slapp konsumpsjon av kultur i alle former, det meste levert gjennom YouTube. Etterhvert som formen kommer seg, øker oppmerksomhetsvinduet og kvalitetsforventningene, og derfor er det en glede å finne at min gamle helt Stephen Fry, som har hatt en hel del helseproblemer de siste årene, nå er i full vigør og sprer sine historier og språkekvilibristiske ornamenter til en takknemlig almenhet igjen – her som gjesteprofessor ved Oxford:
I en verden der språkroboter (for å bruke Jan Ketil Arnulfs presise ord fra «Kunstig intelligent psykologi«, en bok jeg leser om dagen, absolutt anbefaler, og skal komme tilbake til) har gitt oss en kakofoni av hypereffektiv, hjelpsom middelmådighet, er det en fornøyelse å høre språk som overrasker, som er uforutsigbart og dermed verdifullt.
Det forutsigbare krever litt innsats å produsere og konsumere, nettopp fordi det er uforutsigbart. Så legg inn det innsatsen – det er verdt det.
I 2007 skrev jeg en kronikk i Aftenposten som (sammen med et foredrag på en konferanse) avstedkom endel diskusjon. Av en eller annen grunn la jeg den ikke på bloggen min. Så postet Peggy Brønn noe på LinkedIn, som fikk meg til å tenke litt, og stille spørsmålet: Er det jeg skrev i denne kronikken for snart atten år siden fremdeles sant – og i hvilken grad?
Jeg har noen ganger forsøkt å skaffe jobb og oppdrag for briljante teknologer fra utlandet. Siden jeg kjenner endel ledere i konsulentbransjen, kontakter jeg dem, og svaret har nokså konsistent vært: Vi trenger smarte folk og skulle gjerne hatt denne personen, men får ikke solgt hen. Kundene våre (ofte mindre firma utenfor Oslo eller offentlige virksomheter) setter krav til norsk språk. Og dermed går man glipp av super kompetanse og et videre perspektiv på verden.
Peggy skriver om sosial isolasjon, og det er kanskje et like stort problem. Nordmenn snakker godt nok engelsk til å føre en samtale, men ikke godt nok til å spøke, gjøre ordspill eller presist nyansere meninger. Dermed kan det bli litt kleint å invitere utlendinger hjem i et blandet selskap, av både lingvistiske og sosiale årsaker.
Da Kristine og jeg giftet oss nylig, løste vi problemet ved å ha et eget bord til utlendingene (amerikanere, stort sett) og ved å sette noen norske gjester med utenlandserfaring og språkferdigheter der som lenker til resten av selskapet. Det må man gjøre i organisasjonslivet også, men det krever ressurser og ferdigheter.
Nok om det, jeg har ingen løsning utover at jeg tror ting endrer seg, men svært gradvis. Og her er kronikken. Som jeg er redd fremdeles har mye sannhet i seg.
Frykten for de beste Norsk næringsliv ansetter heller en middelmådig nordmann enn en topp utlending. Da vet man hva man får.
Espen Andersen, publisert i Aftenposten 22.12.2007
Spennende og kunnskapsrike. Jeg foreleser på Handelshøyskolen BI, på de høyere programmene. Det er morsomt — jeg treffer mange spennende og kunnskapsrike mennesker, som er høyattraktive i arbeidsmarkedet og får spennende jobber til gode betingelser.
Men ikke alle.
Best ikke nok. Det har seg nemlig slik at noen studenter ikke får jobb – i hvert fall ikke jobber som er deres kompetanse verdig. De har gjerne en annen hudfarge enn nordmenn flest, eller rare etternavn, eller begge deler. Det hjelper ikke at de er best i klassen, jobber steinhardt, og snakker norsk nokså flytende. Norske arbeidsgivere vil nok ha dem, men ikke på samme nivå og karrierestige som de norske.
Mange eksempler. Jeg tenker på den briljante østeuropeiske jenta som lå langt foran sine medstudenter innen kompliserte emner som teknologiledelse og finansiell analyse. Hun fikk ikke jobb i Norge, flyttet til London og en stilling i en global investeringsbank.
Søramerikaneren med reflekterte synspunkter og enestående ledererfaring, som slet med å få jobb i Norge og nå bor i Sveits.
Den latinamerikanske kvinnen som hadde lederstilling med stort ansvar i en kunnskapsbedrift derover, traff en nordmann, flyttet til Norge og ikke fikk jobb. Etter norsk mastergrad fikk hun til slutt jobb i det samme firmaets Norges-avdeling – på et mye lavere nivå.
Verdens beste. Store deler av norsk næringsliv har andre ansettelseskriterier enn kunnskap og flid. De rekrutterer folk til bedriftsidrettslaget, ikke til bedriften. Situasjonen blir ikke bedre for folk som kommer fra institusjoner i utlandet. Norsk arbeidsliv vil ikke ha flinke utlendinger selv om de kommer fra verdens beste universiteter.
Flyttet fra Norge. I en familie jeg kjenner, har begge ektefeller tekniske doktorgrader fra topp universiteter – hun (norsk) fra USA (MIT), han (britisk) fra England (King’s). De flyttet til Norge, men etter to år bar det tilbake til USA. Han fikk ikke jobb i Norge uten å gå 60 % ned i lønn. Den offentlige skolen deres barn skulle gå på, var dårlig – og det kunne de ikke gjøre noe med.Og deres mørkhudede barn ble diskriminert i butikker og barnehage. Nå bor de i USA og investerer i høyteknologifirmaer. Deres barn går på en god skole og snakker fire språk flytende.
Ikke bruk for dem. Et finsk-norsk ektepar med doktorgrader fra MIT og Harvard fant ikke arbeid i Norge og måtte flytte ut igjen, enda de ikke forlangte amerikanske lønninger.
Vi ser ikke ut til å ha bruk for flinke mennesker.
Hvorfor skjer dette? Jeg tror ikke problemet er rasisme eller utlendingsfrykt, selv om det kanskje for noen er en faktor. Det er heller en form for makelighet: Siden det er litt mer jobb og en større utfordring å ansette flinke utlendinger, lar man det være.
Provinsiell holdning. Mange norske bedrifter har i sin provinsialitet også et meget snevert bilde av hva som er relevant erfaring og kunnskap: Med mindre du har jobbet med akkurat deres type produkter eller har utdanning akkurat lik den de andre i firmaet har, kan du ikke brukes. Av og til blir det latterlig: En bekjent med doktorgrad fra Oxford fikk i fullt alvor beskjed om at, jo da, utdanningen var grei nok den, men den kom jo ikke opp mot NTH.
Man vet hva man får. Den største grunnen er nok likevel kunnskapsfrykt: Mange ledere og organisasjoner nøler med å ansette flinke folk fordi de er redd for å virke dumme. Som en administrerende direktør sa til meg en gang: «Vi ansetter helst idrettsfolk, for de er så gode lagspillere».
Heller en middelmådig nordmann enn en topp utlending. Da vet man hva man får.
Veien til suksess. Dette er en meget kortsiktig strategi både for bedriften og karrieren. En venn av meg har en topplederstilling i et stort og meget anerkjent konsulentfirma. Jeg har kjent ham lenge, også hans svake sider, og spurte hvorfor i all verden han hadde gjort det så bra. Han gliste bredt og sa han hadde suksess fordi han konsekvent ansatte folk som var mye flinkere enn han selv.
Ikke helsvart. Mange internasjonalt rettede softwarebedrifter og mange store konsulentselskaper fargeblinde og lite opptatt av at folk skal «gli inn i miljøet» – rettere sagt, de har et så internasjonalt miljø at det å gli inn ikke blir så vanskelig. Yngre næringslivsledere er mer åpne enn de gamle, og et presset arbeidsmarked hjelper.
Men av og til blir det trist: En flink ung mann jeg fikk inn på mitt kontor, norsk med utenlandsk bakgrunn, hadde et dilemma: Han hadde etter mye leting fått en saksbehandlerstilling hvor han jobbet med innvandrerungdom. Nå hadde han tilbud om en spennende lederstilling i et europeisk selskap – men han ønsket å være forbilde og rollemodell for utenlandsk ungdom i Norge. Han ba meg om råd, og jeg anbefalte ham å dra utenlands – både for sin egen del, og fordi han antagelig blir et bedre forbilde på den måten.
Hvorfor skal en flink ung nordmann måtte dra utenlands for å bli anerkjent?
Utenlandsk en fordel. Egentlig burde bedrifter foretrekke medarbeidere med utenlandsk bakgrunn. Ikke bare har de mer livserfaring, de er også mer motivert for å gjøre det bra. Dessuten er de mindre tilbøyelige til å bytte jobb hvis de finner et sted de blir behandlet som jevnbyrdige. Men store deler av norsk næringsliv gjør ikke det. Og taper etter hvert disse folkene til utenlandske selskaper, som rekrutterer aktivt og ikke engang legger merke til nasjonalitet eller hudfarge.
Under sin kompetanse. Neste gang du møter en kompetent utlending i Norge, spør om han eller hun er gift med en nordmann. Det er helst derfor de er her – og arbeider langt under sitt kompetansenivå.
Vår fremste mekanisme for å tiltrekke oss kompetente utlendinger er å få dem spleiset med en pen norsk gutt eller jente. En «strategi» som minner ikke så lite om organisert prostitusjon.
Kompleks og uensartet. Dette holder ikke i lengden. Norge har en liten, åpen og svært eksportavhengig økonomi. Skal man selge til utlandet, vil jo nettopp utenlandsk erfaring og bakgrunn være en fordel, ikke en ulempe.
Hvis ditt marked er komplekst og uensartet, må du bygge opp en tilsvarende kompleks og uensartet organisasjon. Skal norsk næringsliv kunne konkurrere globalt, må man komme seg over sin kompetansefrykt, og se på hva folk kan heller enn hvordan de ser ut og hvordan de snakker. Og man må ikke bare ansette dem, man må også utvikle og forfremme dem i like stor grad som etniske nordmenn.
For hvis du kan overleve selv om du ikke ansetter de beste, konkurrerer du ikke hardt nok – og da er du ikke rustet når den virkelige konkurransen kommer.
I alle kunnskapsbedrifter er det – og skal være – en spenning mellom markedssiden, som er fokusert på hva kundene vil ha, og den faglige siden, som heller vil grave seg ned i det som er faglig interessant. Hvis den ene siden får lov til å dominere for mye, blir det feil, uansett. Langsiktig forretningsutvikling i kunnskapsbedrifter handler om å skape en produktiv spenning mellom disse to fløyene.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
En kunnskapsbedrift lever av å ha kunnskap og selge den. Kunnskap kan eksistere og selges i mange former, men en stor del av kunnskapen vil alltid ligge i og formidles av mennesker. Det er en klisjé for alle som leder kunnskapsbedrifter at alt bedriften eier, forsvinner ut døren hver ettermiddag, og det er ledelsens jobb å sørge for at den dukker opp igjen neste morgen.
I virkeligheten er det litt mer komplisert. En ting er at mye kunnskap kan konserveres og pakkes i form av dokumenter, databaser og kode. En annet – og mye viktigere – moment er at kunnskapsbedrifter skaper verdi ikke bare ved å ha kunnskap og selge den, men å sette sammen ulike former for kunnskap rundt en kundes problem. Skal man bevege seg ut av nerd-to-nerd markedsføring, må man ha en markedsrettet side av organisasjonen – og den siden må ha en viss makt til å sette kundenes ønsker først.
Organisering – marked vs. kunnskap
Hvis man ser på rene kunnskapsbedrifter over en viss størrelse som konkurrerer i et marked, vil man finne at organisasjonen er designet rundt to akser: Kunnskap og marked. Kunnskap handler om spesialisering, om å ha dype kunnskaper innen enkeltområder. Marked handler om å forstå hva kundene vil ha.
Kunnskapsbedrifter skaper verdi gjennom å ha kunnskaper og selge dem, men også å kunne kombinere kunnskaper rundt kundens problem, enten ved å ha dem innen sin egen kunnskapsportefølje, eller ved å finne andre kunnskapsbedrifter å samarbeide med.
Store konsulentselskaper, for eksempel, har ofte organisasjonsstrukturer som reflekterer denne dikotomien. Et av de reneste eksemplene jeg vet om, er konsulentselskapet Accenture’s organisering fra ca. 20 år siden, som hadde fire kunnskapsområder (strategi, prosess, endring og teknologi) og seks markedsområder (energi, telekom, finans, industri, offentlig og transport). På BI, hvor jeg jobber, er den faglige siden representert ved ni institutter og markedssiden ved fire forretningsområder (bachelor, master, executive og bedriftsinterne kurs).
Tanken er at markedssiden skal ha kontakt med kunden, forstå behovet, og snu seg mot kunnskapssiden og hente inn det man trenger.
Balanse i alt
En kunnskapsorganisasjon fungerer som regel best når det er en viss balanse mellom marked og fag, mellom markedsoversikt og spesialiseringsdybde. Hvis den ene siden får lov til å dominere, skaper det vanskeligheter.
En markedsdominert organsiasjon tenderer til å overselge – noe man ofte ser hos konsulentselskaper i nedgangstider. Desperate etter oppdrag erklærer organisasjonen seg klar til å løse hva som helst, og ender opp enten med oppdrag som ikke er godt nok betalt til å dekke utgiftene, eller med å ta på seg ting man ikke klarer å løse godt nok. Det siste er ekstra skummelt, fordi en kunnskapsbedrift lever at sitt omdømme, og det skal ikke mange slike bommerter til før man er ute av dansen.
En kunnskapsdominert organisasjon er like ille. Dette oppstår gjerne i situasjoner der markedssiden av en eller annen grunn er svekket eller satt ut av spill. Dette kan skje hvis ekspertene er for dominerende – for eksempel i softwarebedrifter startet av utviklere, som gjerne vil utvikle i visse verktøy og med visse typer løsninger, uansett hva kundene sier. Sålenge etterspørselen er stor går dette greit, men all teknologi som er ny og banebrytende blir ganske fort gjenstand for konkurranse – og da holder det ikke å sortere køen lenger.
Markedssiden kan også svekkes ved at den blir offentlig regulert, slik det f.eks. er i offentlig helsevesen og tildels i utdanning. Et sykehus i Norge skal levere til alle, betalt av det offentlige, og kan ikke sette opp prisen for å få ned etterspørselen. Dermed kan man få en situasjon med for høy etterspørsel i forhold til kapasitet. Resultatet er ofte overspesialisering – en lege kan ikke behandle alle, og ikke sette opp prisen, så da er svaret ofte å begrense hva slags pasienter man kan ta ut fra kategorisering, til mengden pasienter er overkommelig. (Merk: Jeg argumenter ikke for en privatisering av helsevesenet i Norge her, men vil bare påpeke at fravær av markedsmekanismer kan skape sine egne problemer.) Resultatet er, som jeg tidligere har påpekt, at det helhetlige pasientperspektivet blir borte og pasienter i stedet oppfattes som enkeltdiagnoser.
Produktiv spenning
En velfungerende kunnskapsorganisasjon har hva jeg kaller en produktiv spenning mellom kunnskaps- og markedssiden, der kunnskapssiden har folk som forstår kundenes perspektiv og behov uten å gå på akkord med hva de kan og vil levere, og markedssiden har nok spesialkunnskap til å kunne forme og kommunisere kundesiden uten å overselge. Dette krever også gjensidig respekt for hverandre egenart – at de som selger forstår at fagfolkene er slik de er fordi de bryr seg om kvalitet og utvikling, at de som er fagspesialister forstår at disse folkene i dress faktisk gjør et viktig arbeid med å sile kundekrav og vurdere gjennomføringsevne slik at fagfolkene slipper.
Denne balansegangen mellom fag og marked er den sentrale lederutfordringen i kunnskapsbedrifter, og en av grunnene til at markedskontakten for en kunnskapsbedrift – enten den er et konsulentselskap, en høyskole eller et sykehus – bør ivaretas eller i alle fall nøye overvåkes av folk med lang erfaring fra begge sider.
Som en svært erfaren konsulentleder sa til meg for mange år siden: Denne bransjen – rådgivning – «er den eneste bransjen hvor du forfremmes til selger». Den erkjennelsen kan være vanskelig å ta for en ekspert som helst vil drive med sitt fag (og kanskje grunnen til at ikke alle eksperter skal bli ledere). Det betyr også at dette kundeperspektivet ikke er noe som kan delegeres uten videre til en stab av selgere – i hvert fall ikke uten at de har dyp kjennskap og et edruelig forhold til hva organisasjonen kan og ikke kan levere.
Så, kjære ekspert – husk at du kommer til å ende opp som selger, og planlegg deretter…
Det skrives mye om gutter og menn og hvordan i hvert fall en del av dem blir akterutseilt økonomisk og utdanningsmessig. Denne artikkelen fra Harvard Magazine oppsummerer og rapporterer om data jeg ikke visste om (at menn og gutter har seilt akterut siden 50-tallet), og artikulerer noe jeg har tenkt, men ikke helt satt fingeren på: Støtten for Trumps presidentskap og de mange rare økonomiske utspillene ser ut til å være drevet av et slags mål om å komme tilbake til 50-talls industriell og tildels kjønnssegregert verden. Og, som denne artikkelen sier: Det er nettopp det det er. Trumps kjernevelgere er menn uten utdannelse (og partner), av alle raser, som gjerne vil tilbake til en verden der det var nok, for å sitere min forlovede/samboer: Å være mann, ha gjennomført 7 års folkeskole, se nogenlunde OK ut, ha lappen og bil, og kunne danse. Det holdt til at dama og fremtiden var sikret.
You want facts. You want explanations of those facts. And then you want solutions. Jason Furman, professor Kennedy School, Harvard University
Det interessante med artikkelen er at den gjør det som man skal gjøre når man skal lage politikk: Tar for seg data, forståelse, og mulige (ikke mange) løsninger. Mangler man data og forståelse, oppstår et tomrom, som nå er fylt med mannlige influensere, snåle politikere, incels og andre. Effekten er svært ujevnt geografisk fordelt – i USA handler det om det rurale mot det urbane, men det samme oppstår i Norge, der en langvarig effekt av mobilitet, kvinnefrigjøring og utdanning har ført til at distriktene tømmes for folk med utdannelse (slik programmet Norgebygda dokumenterte for 25 år siden). Folk utdanner seg vekk fra sine fødesteder, og resultatet er en økende polarisering, både økonomisk og kulturelt. Når Senterpartiets primærforslag er å reversere ting som har skjedd, er det fordi man ønsker seg tilbake til noe som var trygt og godt, i hvert fall med tilbakeblikkets rosa briller.
Løsningen har tradisjonelt vært subsidiering av distriktene, ulike utjamnings- og støtteordninger, men selve manneproblemet har ikke blitt borte eller engang adressert. Støtteordninger gjør at man ikke sulter (i USA er sikkerhetsnettet dårligere, så der er desperasjonen større), men som rekefisker Sigurd Kristoffersen sier i Aftenposten: Jeg vil ikke ha penger fra staten. Jeg ønsker å utøve mitt yrke som rekefisker (i 13. generasjon). Jeg har bodd på Malmøya og kjenner Sigurd og noen andre der ute med båt- og fiskeerfaring. Noen av dem forteller at det å kunne jobbe med båt og fiske reddet dem fra å havne på et svært tilgjengelig skråplan. (Som en digresjon: Vi har på mange måter skapt et samfunn der det selv i Oslo ikke er plass til én – kun én – fisker, og der byen (representert ved Plan og Bygg) ønsker å fjerne ethvert spor av annet enn park- og rekreasjonsvirksomhet fra kystlinjen. Det får i alle fall meg til å sympatisere litt med Sp, selv om jeg synes de mangler noen prinsipper.)
I Norge er ikke konsekvensene så store – vi har et av verdens likeste samfunn og er dessuten så små at folkebevegelser ikke oppnår de helt store konsekvensene, bortsett fra å holde oss utenfor EU (noe som antakelig kommer til å endre seg etterhvert som EU blir en militær allianse i tillegg til en økonomisk.) I USA, derimot, er ulikhetene og forholdene større, sikkerhetsnettet svakere, og dermed finner milliardærene ut at de kan komme til makten ved å appellere til en gruppe som har problemer fra en utvikling de selv har blitt milliardærer på.
Så konsekvensene kan bli store her hjemme – på grunn av hva som skjer i USA.
Så hva skal man gjøre? Som artikkelen viser, kan man gjøre tiltak for å tilby utdanning, men det ser ut til at det er fattige kvinner som benytter seg av og har effekt av det. Andre, inkludert Norge, har pekt på mannsrollen og det manglende markedet for maskulinitet (i hvert fall tradisjonell maskulinitet). Man kan si mye rart om Jordan Peterson (inkludert hans dundrende taushet når Trump går til angrep på faktabasert forskning og akademisk handlefrihet), men han har rett når han påpeker at det ikke er menn generelt som har makt i samfunnet, men en liten andel menn – de med (i alle fall før Trump) utdannelse, penger og tilpasningsdyktighet.
Artikkelen fokuserer på å komme opp med alternative kilder til arbeid og verdighet – som å få flere menn inn i HEAL-yrker (healthcare, education, administration, and literacy). Hva med betalt lærerskole og sykepleierutdannelse for menn? Gitt at gutter sliter i skolen, er det ikke et opplagt tiltak (om ikke løsning) å få inn flere menn i skoler og helsevesen?
Men det er vanskeligere å komme opp med løsninger enn å påpeke problemer. Og det viktigste er kanskje å se problemene fra perspektivet til de som har dem, og kommunisere tiltak og virkelighetsoppfatning ut fra det.
Denne påsken har jeg vært på hytta, og i fravær av sne har jeg satt opp panel i noe som kommer til bli snekkerboden min (foreløpig heter den Furtebua), iført nyinnkjøpt arbeidsbukse fra Biltema. Det gir ro i sjelen, følelse av å få gjort noe konkret, og er en kilde til læring og hodebry for en som vanligvis sitter foran en skjerm. Det ligger mye kunnskap i snekkeryrket, og det å holde på med det som hobby øker respekten for dem som kan det mye bedre enn meg, enten det er å bygge hus og hytter eller finsnekre møbler. Kanskje vi skulle starte der, men å se verdien i det konkrete ut fra den kunnskapen som ligger i det som ikke oppfattes som intellektuelt, men kanskje er det likevel?
PS: Jeg har studert ved Harvard, og er naturlig nok stolt av det. Men når universitetet tar lederrollen i å stå i mot Trump-administrasjonens klønete forsøk på å ensrette forskning og sortere kunnskap, gjør det meg i alle fall ikke mindre stolt. Jammen på tide at noen «puts their money where their mouth is» og forstår hva som virkelig står på spill her.









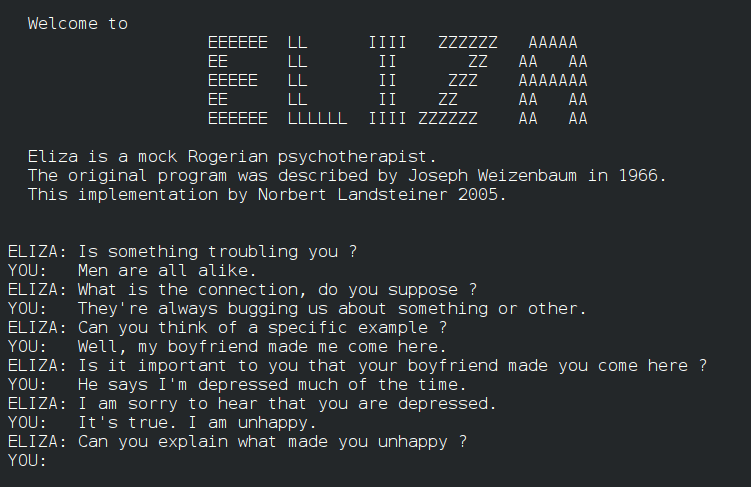





















{kind=link}