Da er første Master-kull (14 stk) på Informatikk: Digital Økonomi og Ledelse uteksaminert, og her er tolv av dem:

Og det er det jo all grunn til å feire! Mer om studiet finner du her.

Da er første Master-kull (14 stk) på Informatikk: Digital Økonomi og Ledelse uteksaminert, og her er tolv av dem:
Og det er det jo all grunn til å feire! Mer om studiet finner du her.
Her for noen uker siden skulle jeg presentere studiet Informatikk: Digital Økonomi og Ledelse for Rådgiverdagen på UiO. Jeg møtte opp med foiler og en historie, men fikk beskjed om at på grunn av en misforståelse skulle jeg ikke holde foredrag likevel. Nuvel, sånt skjer, men jeg hadde jo forberedt meg, så derfor bestemte jeg meg for å lage en liten video om hvorfor og hvordan dette studiet ble til, hva det inneholder, og hvordan det går med studentene som nå kommer ut med en Master. Informasjon som sikkert har interesse for poden som skal søke seg videre i livet til våren.
Hint: Det går bra med studentene. Svært bra.
Og hvis du aner at jeg er litegrann stolt av dette studiet, vel, så stemmer det.

Etter en liten sommerpause kommer nok en kommentar i digi.no. denne gang om hvordan man må tenke annerledes om Akson-prosjektet. Mitt hovedpoeng er at systemet må skaleres ned til bare å handle om det medisinske og dataene rundt det – med et teknisk uttrykk, at systemet må tenkes på som kun et system for utveksling av informasjon, ikke som et system som skal løse alle punkter på en enorm ønskeliste som kommer til å endres masse frem til systemet blir ferdig – om det noensinne blir det.
Megaprosjekter innen software går ikke, ganske enkelt. Og medisinske systemer bør bygges ut fra det medisinske, ikke det byråkratiske.
Akson bør bli hodeløst. Så spørs det om noen har hode til det.
Og her er lydfilen (også tilgjengelig på Spotify.)
Forrige torsdag skulle jeg forelese på IFI, men den forelesningen er utsatt og (naturligvis) flyttet til nettet. Jeg tenkte først jeg skulle gjøre den som en videokonferanse, men så fant jeg ut av jeg kunne jo lage en video studentene kunne se på forhånd, og så ta diskusjonen i et forum som tillater interaksjon begge veier. Det å lage video er endel arbeid, men den kan brukes i mange sammenhenger (noe som er grunnen til at jeg laget den på engelsk. Her er resultatet:
Til mine foreleserkolleger: Det faglige innholdet her er antakelig ikke så interessant for de fleste, men det er noen tips og erfaringer i de første to minuttene og de siste fem.
For andre, her er en innholdsfortegnelse med omtrentlige tider:
Dette er ikke første gangen jeg har laget videoer, men det er første gangen jeg har laget en såpass lang video selv, og med en fremtidig forelesning som hensikt. Noen refleksjoner:
Min eminente kollega Ragnvald Sannes påpekte i en telefonsamtale i morges at dette har konsekvenser for hvordan vi organiserer og belønner forelesning. Vi kommer til å bruke mye mer tid på å lage innhold og mye mindre tid på å stå og gjenta det. Det betyr at vi ikke lenger kan betale folk ut fra undervisningstimer – eller i det minste at vi redefinerer hva begrepet betyr.
If you think you understand quantum mechanics, you don’t understand quantum mechanics. (Richard Feynman)
Notater fra et seminar i Forskningsparken. Advarsel: Notater tatt underveis – mangler, misforståelser og digresjoner i massevis.
Hva er en kvantedatamaskin? Franz Fuchs (SINTEF)
Introduction: Google’s «quantum supremacy» isn’t that… Quantum computers outperform regular computers on certain tasks (such as integer factorisation) but are unlikely to have practical use in the near future. Moore’s law is saturating, transition to a quantum age. Short history of quantum computing:

Quantum computers are at the stage of ENIAC at this point.
Two challenges for quantum computers: Hardare and software. Lots of research: EU has a quantum computing technologies flagship, worth 1b Euros, similar in the US and China. IBM has done a lot of research, up to 20 qubits devices. D-Wave uses quantum annealing, a kind of analog computing, free access for 1 minute, open source python tools. Alibaba, Microsoft, Google all experiment. Intel, Rigetti has technologies (the latter a hybrid), IonQ. In sum: Heavy investments into development from many parties. But: Classical algorithms run on a quantum computer will not run faster. Shor’s algorithm is not parallelism… Developments:

Applications will be quantum chemistry, AI, optimization, and simulations. In addition, cryptography, China is using quantum satellites to have safe video calls, and a quantum tunnel between Beijing and Shanghai, though this is not strictly quantum computing.
Question: Quality of qubits? IBM has a measure, depends on errors in measuring, connections, etc.
Question: Languages? A number of high-level languages (QISKit, Forest), mostly assembly at this point. Will be more general.
Kvanteberegning og IoT. Ketil Stølen
Naivt bilde av IoT: Data opp i skyen. Pipeline en flaskehals, dermed går man til fog computing (LAN-nivå) og edge computing (tingene selv). Stort problem at teknologien er fragmentert og umoden, mangler særlig testet software for integrering og interaksjon. Sikkerhet ofte et problem på grunn av manglende kapasitet. Samtidig gir nettforbindelse en kolossal angrepsflate. Eksempel: Casino angrepet gjennom et akvarium som sto i foajeen. Et annet problem er at man er svært avhengig av leverandører. Personvern også et stort problem – og mye av motivasjonen for edge computing.
Kan QC hjelpe til med disse problemene? Masse hype. Noen problemer: Størrelse (pga. behov for superkjøling.) På kort sikt må man jobbe med store QC-maskiner, hvordan kan dette gjøres. Forskning ved Delft snakker om behov for algoritmekunnskap go lokale satellitt-maskiner. Problem er at QC gir omtrentlige svar. Min digresjon: Bør kunne brukes til PGP-oppaknining og løsning av visse typer knapsack-problemer, der en omtrentlig løsning er bra nok.
Kvanteberegning ned til fog og edge vil antakelig kunne takle et sikkerhetsproblem. Kontra: QC kan føre til at man kanskje lager sikrere arkitekturer fra bunnen av.
Diskusjon: Ca. 95 algoritmer der man har funnet at QC er raskere, det er nokså lite. Optimalisering det som D-Wave driver med, annealing fungerer for optimalisering. Men smalt spektrum av brukerområder til nå.
En arkitektur som ikke er nevnt: Photonic quantum computing, skal kunne ha romtemperaturløsninger om 5-10 år. Gir et sikkerhetsproblem ved at dagens kryptering ikke holder for fremtidige metoder.
Kvantekryptering, kvantehacking og sikkerhet. Johannes Skaar (UiO)
Kvantekryptering kan gjøres i dag med en liten dings, Sende fire fotoner som detekteres, enkelt å gjøre. Quantum key distribution trenger en ekstra kanal, BB84-protokoll:
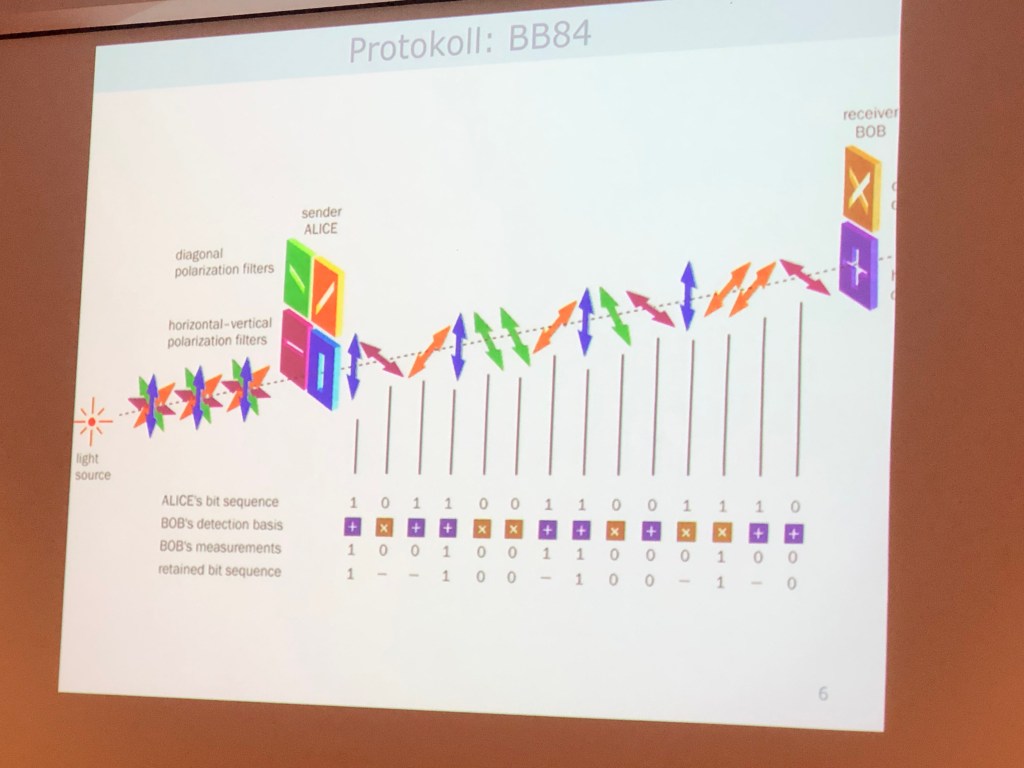
Dette er sikkert pga to prinsipper: Ikke mulig å klone kvanteinformasjon. Måling vil forstyrre kommunikasjonen. I praksis: nokså enkelt å hacke kvantekommunikasjon. Kvantehacking, russer (Vadim Makarov) med postdoc på UiO, laget en koffert som kunne gjøre dette.
Alternativer til kvantekryptering: Assymetrisk offentlig nøkkelkryptering. Symmetrisk privat nøkkelkryptering, Oppsummering: Mange problemer med kvantekryptering, men verdt å forske på dersom vi mister assymetrisk kryptering som alternativ.
Kvanteresistent kryptografi. Thomas Gregersen (NSM)
QC et problem fordi tradisjonelle algoritmer brukes lenge etter at de er obsolent, derfor må vi utvikle kvanteresistent krypto før QC finnes. Grovers algoritme (generell) og Shors algoritme (spesiell for integer faktorisering) er utfordring fordi den finner løsninger i lineær tid. Initiativer fra NIST og PQCRYPTO (EU) mot å utvikle dette.
Nye algoritmer vil måtte ha nøkler og signaturer som ikke tar for stor plass. Skal ikke ta for lang tid, og bruke kjente vanskelige beregningsprosesser. Mange kandidater:

En hel del av dette kommer til å bli implementert, scenariet er at det skal kunne kjøres på en klassisk maskin og beskytte mot en angriper med tilgang til kvanteanalyse. Ulike algoritmer har ulike fordeler/ulemper, mulig at man kan løse dette ved å rullere algoritmer for samme melding. Men det gjenstår å se om det rent praktisk er relevant å lage maskiner som kan angripe skikkelig krypto, men vi må bruke tid på denne forskningen i tilfelle noen klarer det.
Diskusjon: Mye av kryptoknekking skjer pga. dårlig implementering. Det å øke antallet algoritmer gjør at man øker risikoen for dårlige implementeringer, særlig i hardwarebaserte løsninger. Fascinerende at dette er det samme vi har sett før: Nytt domene, blir et nytt kappløp mellom knekkere og kodere.
Kvanteberegning og kunstig intelligens. Phillip Turk (SINTEF)
Innledning om AI og ulike metoder, fokus på søkealgoritmer, siden mye AI går ut på å søke over et stort antall mulige løsninger. Algoritmer er forskjellige – input er hvordan man organiserer gates – alle løsninger finnes i superposisjonene, algoritmene siler seg frem til den korrekte løsningen.
Kommentar: Kan man bruke en QC til å finne heuristikk som så kan gjøres om til en algoritme som kan brukes av en vanlig datamaskin? Første anvendelse antakelig maskinlæring ved hjelp av quantum annealing, kanskje innen ti år. Ennå ingen problemer der man har quantum supremacy, noe uklart om vi har det ennå, men det kan kanskje komme for et eller annet problem snart.
I dag hadde jeg med meg mine unge og smarte DigØk-studenter på besøk hos FINN.no, et av nokså få selskaper i Norge som er a) heldigitale og b) har en eksplisitt og datadrevet innovasjonsstrategi. Jens Hauglum hadde lagt opp et spennende program som inkluderte perspektiver fra organisasjonssiden (Kristin Sætevik), eiersiden (Schibsteds konsernstrategi ved Sven Thaulow) og ledersiden (Ruben Søgaard) i bedriften.

Det ble et meget vellykket besøk, med høyt engasjement fra studentenes side (de var vel forberedt, vi hadde diskutert Schibsteds utvikling frem til 2007 i en tidligere forelesning basert på et case fra HBS). I tillegg til foredrag og diskusjoner fikk de prøve seg på en aldri så liten idegenerering selv, i et forsøk på bedre å forstå FINN.nos innovasjonsprosess, kalt «ledersnurren«.
FINN.no og Schibsted er forbausende lite kjent i norsk næringslivspresse, noe som er litt rart, gitt at selskapet (inkludert Adevinta, verdsatt til 33 milliarder, en av Oslos største børsintroduksjoner) har omsetning for 20 milliarder totalt med EBITDA på 40-tallet innenfor markedsplassene. Men norsk business-presse er stort sett opptatt av oljeprisen…
I alle fall – takk til FINN.no for et supert opplegg – og det skulle ikke forundret meg om ikke en hel del av studentene kunne tenke seg en karriere i FINN.no.

Fredag var jeg på «toppmøte» om digitalisering, et møte der regjeringsmedlemmer (8 ministre på hvert sitt bord), universitetsrektorer, og andre samfunnstopper diskuterte digitalisering i Norge, primært rundt offentlig sektor. Det var innledende presentasjoner av Camilla Tepfers, Morten Dæhlen, Camilla Serck-Hanssen og Hege Skryseth. Gjennomgangstemaene var de det pleier å være: Vi mangler digital kompetanse, mangler tverrfaglighet (i mange dimensjoner) og skal det skje noe i offentlig sektor må vi rive eller i alle fall forbinde siloene.
Jeg fikk mye å tenke på og skrive om – og mitt hovedinntrykk er at vi vet hva vi skal gjøre, men vi gjør det bare ikke.
Nok om det. I denne omgang skal jeg ta for meg noe mer spesifikt, nemlig kunnskapsrepresentasjon.
Morten hadde et utmerket innlegg som han har delt på mat-nats blogg, og der hadde han dette som et av fire hovedpunkter:
Digital representasjon og visualisering. Behovet for kunnskap om digital representasjon av kunnskap synes å være undervurdert, men dette området er i vekst, noe som i all hovedsak skyldes dataeksplosjonen. Kunnskap om hvordan digitale representasjoner presenteres og visualiseres er også en vesentlig del av dette.
Jeg kunne ikke vært mer enig, men hva betyr egentlig digital representasjon og visualisering? Ved første øyekast kan det se ut som evnen til å lage delikate fremstillinger av data, som for eksempel Hans Roslings fantastiske TED-foredrag. Men egentlig betyr uttrykket mer å klare å gjøre data tilgjengelig i en form som datamaskiner kan behandle.
Wikipedia beskriver knowledge representation and reasoning som «the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks». Er det en ting jeg har funnet ut ved å undervise kurs i strategisk dataanalyse, så er det at det å få dataene inn i en form og med et innhold der man faktisk kan gjøre noe med dem er kanskje den nest største vanskeligheten. (Den største er å formulere spørsmål som faktisk lar seg besvare, mer om det en annen gang.)
La oss ta et helt banalt eksempel: Sett at du underviser et kurs (som jeg ofte gjør) og du skal lage deg et regneark for å holde orden på studentene. Du ber administrasjonen om en liste over hvem som er med i kurset, og får et regneark eller en tabell som ser slik ut:
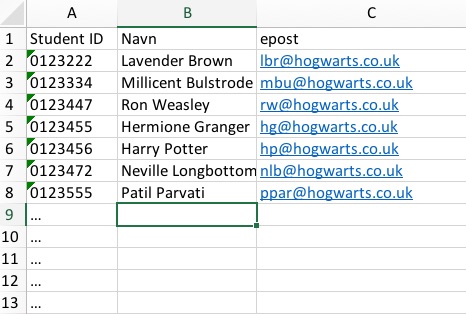
Utmerket, i og for seg. Men vent litt – hva om jeg har lyst til sortere studentene alfabetisk på etternavn, eller å lage navneskilt til studentene med fornavnet på en linje og etternavnet under? Da er det ganske klart at kolonne B ikke er satt opp for dette, siden for- og etternavn ikke er adskilt. Hvis jeg skal gjøre det, må jeg enten gå gjennom alle studentene og manuelt skille for- og etternavn (tidkrevende og kjedelig), eller skrive en liten makro som gjør det automatisk. Den siste løsningen introduserer feilkilder: En av Harry Potters medstudenter hetter «Choo Chang» og omtales som Choo, men egentlig burde hun jo vært «Chang Choo» siden navnet er aseatisk. For ikke å snakke om studenter med navn som «Jose Maria Casiento Gomez-Caseres de Monteleon», hvor det ikke er helt enkelt å finne ut hva man skal kalle dem.
Og her er vi fremme ved hva kunnskapsrepresentasjon er – hvordan gjør man data tilgjengelig slik at man kan bruke det til noe, uten at man på forhånd vet hva dette «noe» er?
Dette er vanskeligere enn man tror, og har å gjøre med informasjonsarkitektur, databasestrukturer, metadata, APIer og masse annet morsomt. Men bare ha dette lille eksempelet i mente, så har du i alle fall litt av den digitale kompetansen Morten etterlyser…
 I går morges ringte Morten Dæhlen, Dekan for Mat-Nat på Universitetet i Oslo, med meget hyggelige nyheter: Studiet Informatikk: Digital Økonomi og Ledelse, som jeg er initiativtaker til og har jobbet med Institutt for Informatikk for å utvikle, har nettopp mottatt søkertallene fra Samordnet opptak: Til 27 studieplasser har vi fått 514 søkere med studiet som førsteprioritet, og over 3000 som har det som annen- eller tredjeprioritet.
I går morges ringte Morten Dæhlen, Dekan for Mat-Nat på Universitetet i Oslo, med meget hyggelige nyheter: Studiet Informatikk: Digital Økonomi og Ledelse, som jeg er initiativtaker til og har jobbet med Institutt for Informatikk for å utvikle, har nettopp mottatt søkertallene fra Samordnet opptak: Til 27 studieplasser har vi fått 514 søkere med studiet som førsteprioritet, og over 3000 som har det som annen- eller tredjeprioritet.
Dette betyr at studiet har 19 førsteprioritetssøkere per studieplass, og dermed er det mest ettertraktede studiet i Norge.
Made my day. Og ser frem til å møte flinke og motiverte studenter til høsten!
Oppdatering: Nå også i Dagens Næringsliv. Og i Aftenposten.
Et problem – i Norge kanskje mer enn andre land – er at vi mangler folk som forstår både teknologi og forretning. Det er en kultur i Norge for at gode ledere kan lede hva som helst (noe jeg mener er det reneste sludder), og at teknologi er noe som man kan overlate til teknologene. Dette gir seg mange utslag, blant annet i at det er forbausende få studier som kombinerer teknologi og business, selv om et av de få studiene som gjør det – Indøk (Industriell Økonomi) på NTNU – er av de mest søkte i Norge.

Det har jeg gjort noe med – ved (sammen med Stein Gjessing) å opprette et nytt studium ved Institutt for Informatikk ved Universitetet i Oslo. Det nye studiet er et bachelorprogram og heter Informatikk: Digital økonomi og ledelse.
Studiet har to tredjedeler informatikk – skikkelig hardcore, med programmering og teknologi – og en tredjedel forretningsfag. Tanken er å lage et motstykke til IndØk i Trondheim, men rettet mot IT-bransjen (som stort sett ligger i Oslo-området.)
På forretningssiden blir det fire nye kurs innen økonomi- og ledelsesfag, som jeg har utviklingsansvar for:
Hver av disse kursene blir et oversiktskurs der mange forretningsfag integreres i ett – noe jeg ikke tror blir noe problem, siden vi kommer til å ha svært dyktige studenter. Planen er at etter denne bacheloren kan man velge om man vil gå videre med en teknisk master (på IFI, kanskje) eller en forretningsmaster (BI?). Jobbmulighetene vil uansett være aldeles utmerket, selv i disse ulvetider.
Så – hvis du har ambisjoner om å være en av disse sjeldne personene som forstår både teknologi og forretning og kan kommunisere med begge sider (en posisjon som både er interessant karrieremessig og potensielt lukrativ): Søk Digøk!
