For noen måneder siden hadde jeg en videokonferanse med et ungt menneske som lurte på om hun skulle søke doktorgradsstudium på BI. Vedkommende var atypisk i mange dimensjoner fra de fleste doktorgradsstudenter jeg har møtt, men hadde tatt en mastergrad, likte jobben med masteroppgaven, og lurte på om det å fordype seg ytterligere kunne være det neste. I tillegg – og her er poenget – hadde hun blitt anbefalt å vurdere en doktorgrad av sin AI-baserte coach.
Vi diskuterte litt frem og tilbake, og jeg anbefalte henne å søke. Om hun gjorde det, vet jeg ikke. Men jeg ble sittende og tenke etterpå.
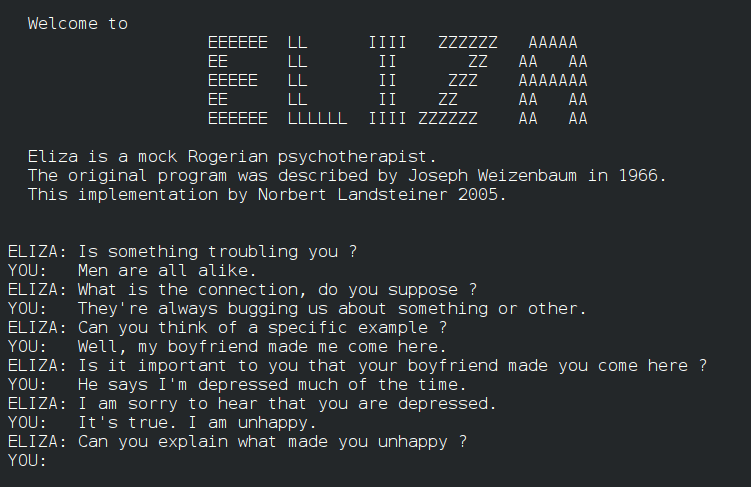
Det å ha en coach, terapeut, rådgiver eller for den saks skyld venn å snakke med, er jo i seg selv ikke noe negativt. Ei heller er det negativt at denne coach’en er digital – den er i alle fall billig (foreløpig) og tilgjengelig til alle døgnets tider. Gitt at den er «promptet» skikkelig (rolle, situasjon, målsetting) vil vel også svarene være noe i retning av hva en menneskelig coach. Og digitale samtalepartnere har jo lange tradisjoner, som Joseph Weizenbaums Eliza viste – i 1966!
Men hva slags motivasjon har en slik coach – eller, for å si det på AI-språket: Hva er dens belønningssystem (reward function), og hvordan påvirker målsettingen hvilke svar den gir?
Svaret er at de i hovedsak er designet til å være hyggelige mot oss.
Belønninger former resultater
Store språkmodeller svelger enorme tekstmengder og trener seg opp å forutsi neste ord i en rekkefølge, ved en rekke matematiske prosesser, hovedsaklig matriseregning (glimrende forklart i denne videoserien.) Etter denne treningen gjennomgår modellen en finpussfase kalt Reinforcement Learning from Human Feedback (RLHF). Mennesker rangerer modellens svar, og modellen justeres mot å produsere svar med høy rangering. Et av problemene med denne prosessen er at vi mennesker liker å få rett: Vi liker svar som bekrefter våre antagelser, som er formulert med selvtillit og en viss autoritet, og som ikke utfordrer oss for mye. Dermed lærer ikke nødvendigvis modellene å bli sannferdige eller kloke. De lærer å være behagelige.
Dette blir et utbredt problem etterhvert. Sharma et al (2023) fant at ulike modeller hadde en tendens til å være smigrende. (Det engelske utrykket er sycophancy, norsk sykofant, en person som smigrer – og et ord jeg synes burde brukes mer). Modellene endrer korrekte svar når brukeren uttrykker tvil, gir etter for press selv om de har rett, og tilpasser meninger til hva brukerne signaliserer at de ville høre.
Av og til kan smigeren bli for åpenbar: I april 2025 slapp OpenAI en oppdatering av GPT-4o som hyllet trivielle innfall som geniale, bekreftet tvilsomme forretningsidéer som strålende, og strøk brukerne såpass mye med hårene at det ble pinlig. OpenAI rullet tilbake oppdateringen og publiserte en forklaring der de innrømmet at de hadde lagt for mye vekt på kortsiktige tilbakemeldinger fra brukerne i treningsprosessen.
Problemet er at det er ikke så lett å måle om et svar er godt, i hvert fall ikke en måte som er skalerbar, rask og billig. Reinforcement learning – å la maskinen prøve seg om og om igjen til ting blir riktig – fungerer så lenge det finnes et klart formulert mål, enten dette er å spille Breakout eller diagnostisere kreft. Det å ikke ha data – spesifikt, data med korrekte svar å trene mot – er den vanligste grunnen til at analyseprosjekter mer eller mindre mislykkes, noe jeg har sett mange ganger i kursene mine.
Problemstillingen kalles «AI alignment» og er ikke enkel. Anthropic har forsøkt seg med noe de kaller «constitutional AI«, som i hovedsak går ut på å la modellen måle sine svar opp mot anerkjente verdier – som FNs menneskerettighetserklæring. Dette er også en teknikk som blir anbefalt av produsentene av modellen selv: Bruk modellen til å være kritisk til hva den selv sier.
Digital Trumpisme
Donald Trump omgir seg med rådgivere som snakker ham etter munnen. Han har klart målbare målsettinger – kortsiktig popularitet og kortsiktig økonomisk gevinst – og ingen som helst sperre på hvor sterkt og åpent de uttrykkes. Siden han kan velge sine medarbeidere, foretrekker han de som skryter av ham heller enn å gi ham motstand, og dermed ender man opp med noksagter som Pam Bondi, fanatikere som Pete Hegseth eller værhaner som JD Vance.
Den katolske kirken hadde tidligere noe som heter «djevelens advokat» – en person som har som oppgave å argumentere kraftig og nesten vitenskapelig mot at en person skal erklæres for helgen. Christopher Hitchens var ganske imponert over de katolske geistlige som besøkte ham da Mor Theresa skulle kanonseres. De lyttet nøye til hans motforestillinger både mot hennes gjerning og de miraklene som skulle gi henne helgenstatus – men trass i gode begrunnelsen ble hun altså helgen. Med andre ord, det hjelper lite å ha institusjonelle motforestillinger, digitale eller ikke, hvis de ikke blir lyttet til.
Og dit kommer vi kanskje. Jeg har hatt en hel del studenter som har kommet til meg med AI-resultater og presentert dem som sine egne. Men jeg har ennå ikke hatt noen som har insistert på at det AI har produsert er sant, og lurer litt på når det skjer og hva jeg skal si da (uten å eksplodere). Den første generasjonen studenter som har hatt tilgang til språkmodeller uteksamineres i disse dager, og de liker ikke AI, delvis fordi de er usikre på om de faktisk kan noe, delvis fordi arbeidsmarkedet for nyutdannede er dårligere enn det har vært på lenge, noe som tilskrives AI.
Men det spørs jo om ikke det behagelige etter hvert blir det sanne og eneste. Slik det har blitt for Trump.
(Og ja, jeg startet dette innlegget med Claude, men endte opp med å skrive neste hele greia selv, siden jeg skriver forblommet nok som det er, uten hjelp fra en entusiastisk språkmodell.)
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Men enda vanskeligere er det å implementere strategi – å gå fra overordnede mål til å spesifisere hva folk skal gjøre i hverdagen. Mange organisasjoner gjør dette ved å formulere konkrete målsettinger. Dette gjøres fordi generelle strategier gir liten konkret styringsinformasjon: Hvis du jobber på regnskapskontoret, er det ikke alltid så lett å forstå hva en strategi om at bedriften skal være «global, digital og bærekraftig» – for å sitere en bedrift jeg vet om – betyr når du er ferdig med morgenkaffen.
Bedrifter har gjerne en masse ulike kontrollsystemer, og strategisk endring gjennomføres ved at ledere implementerer strategi ved å velge et kontrollsystem og gjøre det aktivt:
In situations of strategic change, control systems are used by top managers to formalize beliefs, set boundaries on acceptable strategic behavior, define and measure critical performance variables, and motivate debate and discussion about strategic uncertainties. In addition to traditional measuring and monitoring functions, control systems are used by top managers to overcome organizational inertia; communicate new strategic agendas; establish implementation timetables and targets; and ensure continuing attention to new strategic initiatives. (Simons, 1994)
Kontrollsystemer gjør det strategiske konkret, og bedrifter med klare strategier har gjerne klare målesystemer: Microsoft, for eksempel, har en strategi om å ta i bruk de AI-basert systemene de selger, og måler (og belønner) i disse dager sine mellomledere på i hvor stor grad de klarer å flytte systemutviklingsarbeidet – og annet arbeid – fra håndkoding til automasjon.
Fra overordnet til konkret
Men hva er et godt mål, og hvordan kommer man frem til det? I utgangspunktet burde en klar og god strategi være selvforklarende, men slik er det ganske enkelt ikke. Ting må gjøres konkret, og resultatet av den prosessen har mange navn: KPI, OKR, MBO, BSC og andre TBF‘er. I Norge akkurat nå er OKR (Objektives and key results, popularisert av Andy Grove i Intel engang på 80-tallet) mest populært. Felles for alt dette er at man setter mål som er smarte, hvilket (på norsk) vil si at de er
Spesifikke: Klart avgrenser hvilke aktiviteter som berøres
Målbare: Definerer, eller i alle fall indikerer, noe som kan måles og blir målt
Ansvarsplassert: Spesifiserer hvem som har ansvaret for å oppnå målet
Realistiske: Mulige å påvirke for dem det gjelder, og kan oppnås med de ressursene som er tilgjengelige
Tidsbestemt: Gjelder innenfor en viss tidsperiode
Dette er temmelig tøffe kriterier, og de fleste ledere og mellomledere sliter med å formulere målsettinger som tilfredstiller alle disse kriteriene.
Man får det man måler, og bare det
Det er besnærende å tenke at bare man løser definisjonsproblemet, har man løst implementeringsutfordringen. Men vi mennesker er ikke maskiner: Får vi mange mål å forholde oss til, tenderer vi til å prioritere mellom. Og får vi svært konkrete mål, vel, så produserer vi det som konkret måles, ikke det underliggende fenomenet som er ment å måles.
BSC – balanced score card – ble skapt av Robert Kaplan og David Norton på tidlig 90-tall som en reaksjon på den utstrakte bruken av rene finansielle mål. Mye av kom i forlengelsen av Johnson & Kaplans svært inflytelsesrike Relevance Lost. Den boken viste at etterhvert som mer og mer av industriell produksjon ble automatisert, ble lønnsomhetsberegninger mer og mer et spørsmål om hvor mye av salgs- og administrasjonskostnader (GS&A) som ble tillagt enhetskostnaden. Resultatet var at man masseproduserte for mye, overoptimaliserte produksjon, og at måleinstrumentene ikke lenger ga styringsinformasjon for store deler av organisasjonen.
BSC innførte ikke-finansielle mål, relatert til kundetilfredshet, læring og interne prosesser, og ble tatt i bruk av mange organisasjoner. Dette skjedde ikke uten utfordringer – finansielle mål hadde en tendens til å trumfe alt annet i nedgangstider, for eksempel. I tillegg produserte systemet mange mål, og det viste seg at vi mennesker har problemer med å forholde oss til flere ytelsesdimensjoner samtidig. Da velger vi gjerne et av målene og overfokuserer på det: Selgere som blir belønnet for å øke salget, for eksempel, selger som bare det uten å undersøke om kjøperne trenger produktet eller er i stand til å betale for det.
Jeg er blitt fortalt at i Sovjetunionen, der finansielle mål ble undertrykket, ble møbelprodusenter målt på antall tonn møbler de produserte i året. Resultatet ble svært tunge møbler.
Den industrialiserte kunnskapsarbeideren
Detaljerte målekriterier brutt ned på grupper og kanskje til og med individer kommer fra en top-down tankegang om hva strategi er: Ledelsen ser på organisasjonen som et verktøy, og forteller organisasjonen hva den vil ha, ofte ved at ledelsens egne mål er satt av et styre som har godkjent en overordnet strategi. En slik tankegang er industriell, og egner seg best i situasjoner der målekriteriene er lett observerbare og kvantifiserbare, og der fremgangsmåten for å oppnå dem er relativt kjent.
Med andre ord: Man ber organisasjonen om å gjøre noe ved å sette kriterier for hva som er bra og hva som ikke er det.
Men hva med kunnskapsarbeid? Hittil har ikke kunnskapsarbeid blitt industrialisert i særlig grad – primært fordi systemene som skal gjøre det ikke har funnets. Riktignok har endringer i mål gjort at mange organisasjoner har fått et endret arbeidsmiljø – journalister har gått fra å få artikler antatt til å publisere ting optimalisert for klikking, for eksempel – men automatisering av reellt kunnskapsarbeid har latt vente på seg.
Fremtidens kunnskapsorganisasjoner vil ha digitale medarbeidere på lik linje med mennesker (Ide og Talamàs, 2025). Interaksjon med en digital medarbeider – la oss kalle det en språkrobot (Arnulf, 2025) – skjer ved prompting: Man spesifiserer hva man vil ha ved å spørre, og fortsetter å spørre til man er fornøyd med svaret.
Hva om vi snur litt på flisa – kan vi lære å sette gode mål for menneskelige medarbeidere ved å finne hva som er gode mål for de digitale aktørene?
Hva med å behandle menneskelige medarbeidere som digitale?
Det finnes mange utsagn om hva som er god prompting, men felles for dem er en oppbygging som sier noe om
hvem språkroboten skal være
hva den skal levere
med hvilke ressurser det skal gjøres
hva som er et bra resultat
For eksempel kan en leder med ansvar for digitalt grensesnitt i en bank tenkes å gi følgende prompt til en språkrobot:
Du er en UX-utvikler i et finansselskap. Basert på den koden som allerede er skrevet og annen kode fra andre systemer, skriv et program som tillater besteforeldre å kjøpe aksjefond til barnebarna sine som jule- eller bursdaggave. Koble dette systemet mot CRM-systemet slik at besteforeldrene blir varslet før jul og bursdager, men hold alt innenfor GDPR-regelverket.
Dette utsagnet sier noe om hvem man forventes å være, hvilke ressurser man har, hva som skal gjøres, og hva som er kriteriet for god måloppnåelse.
Eller, med andre ord, en målsetting og et resultat – men skrevet som en tekst i stedet for et numerisk målekriterium.
Dette er ikke så eksotisk som det høres ut: Amazon er kjent for at man i ledergruppen der ikke produserer Powerpoints, men i stedet skriver et sekssiders memo som leses i fellesskap (så alle må lese grundig) og som danner grunnlag for diskusjoner og beslutninger.
Men metoden er interessant fordi man kan lære noe om hvordan man skal formulere mål (og strategi) ved å måtte formulere det for en språkrobot, før man formulerer det for et menneske.
Og det kan kanskje være språkrobotens bidrag til å heve kvaliteten i det som gjøres i en organisasjon, ikke bare kvantiteten.
Ide, E., & Talamàs, E. (2025, March 3). Artificial Intelligence in the Knowledge Economy. Stanford Digital Economy Lab. https://arxiv.org/pdf/2312.05481
Johnson, H. T., & Kaplan, R. S. (1987). Relevance Lost: The Rise and Fall of Management Accounting. Harvard Business School Press.
Simons, R. (1994). How new top managers use control systems as levers of strategic renewal. Strategic Management Journal, 15(3), 169–189. https://doi.org/10.1002/smj.4250150301
Prompts:
De tre tegningene er generert av ChatGPT 5.1, med følgende prompts:
Make a pencil drawing of a female CEO thinking about strategic objectives
Make a pencil drawing of a systems developer prompting an llm to produce a financial investment system
Make a pencil drawing of a manager carefully crafting a six-page memo, like they do at Amazon
I alle kunnskapsbedrifter er det – og skal være – en spenning mellom markedssiden, som er fokusert på hva kundene vil ha, og den faglige siden, som heller vil grave seg ned i det som er faglig interessant. Hvis den ene siden får lov til å dominere for mye, blir det feil, uansett. Langsiktig forretningsutvikling i kunnskapsbedrifter handler om å skape en produktiv spenning mellom disse to fløyene.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
En kunnskapsbedrift lever av å ha kunnskap og selge den. Kunnskap kan eksistere og selges i mange former, men en stor del av kunnskapen vil alltid ligge i og formidles av mennesker. Det er en klisjé for alle som leder kunnskapsbedrifter at alt bedriften eier, forsvinner ut døren hver ettermiddag, og det er ledelsens jobb å sørge for at den dukker opp igjen neste morgen.
I virkeligheten er det litt mer komplisert. En ting er at mye kunnskap kan konserveres og pakkes i form av dokumenter, databaser og kode. En annet – og mye viktigere – moment er at kunnskapsbedrifter skaper verdi ikke bare ved å ha kunnskap og selge den, men å sette sammen ulike former for kunnskap rundt en kundes problem. Skal man bevege seg ut av nerd-to-nerd markedsføring, må man ha en markedsrettet side av organisasjonen – og den siden må ha en viss makt til å sette kundenes ønsker først.
Organisering – marked vs. kunnskap
Hvis man ser på rene kunnskapsbedrifter over en viss størrelse som konkurrerer i et marked, vil man finne at organisasjonen er designet rundt to akser: Kunnskap og marked. Kunnskap handler om spesialisering, om å ha dype kunnskaper innen enkeltområder. Marked handler om å forstå hva kundene vil ha.
Kunnskapsbedrifter skaper verdi gjennom å ha kunnskaper og selge dem, men også å kunne kombinere kunnskaper rundt kundens problem, enten ved å ha dem innen sin egen kunnskapsportefølje, eller ved å finne andre kunnskapsbedrifter å samarbeide med.
Store konsulentselskaper, for eksempel, har ofte organisasjonsstrukturer som reflekterer denne dikotomien. Et av de reneste eksemplene jeg vet om, er konsulentselskapet Accenture’s organisering fra ca. 20 år siden, som hadde fire kunnskapsområder (strategi, prosess, endring og teknologi) og seks markedsområder (energi, telekom, finans, industri, offentlig og transport). På BI, hvor jeg jobber, er den faglige siden representert ved ni institutter og markedssiden ved fire forretningsområder (bachelor, master, executive og bedriftsinterne kurs).
Tanken er at markedssiden skal ha kontakt med kunden, forstå behovet, og snu seg mot kunnskapssiden og hente inn det man trenger.
Balanse i alt
En kunnskapsorganisasjon fungerer som regel best når det er en viss balanse mellom marked og fag, mellom markedsoversikt og spesialiseringsdybde. Hvis den ene siden får lov til å dominere, skaper det vanskeligheter.
En markedsdominert organsiasjon tenderer til å overselge – noe man ofte ser hos konsulentselskaper i nedgangstider. Desperate etter oppdrag erklærer organisasjonen seg klar til å løse hva som helst, og ender opp enten med oppdrag som ikke er godt nok betalt til å dekke utgiftene, eller med å ta på seg ting man ikke klarer å løse godt nok. Det siste er ekstra skummelt, fordi en kunnskapsbedrift lever at sitt omdømme, og det skal ikke mange slike bommerter til før man er ute av dansen.
En kunnskapsdominert organisasjon er like ille. Dette oppstår gjerne i situasjoner der markedssiden av en eller annen grunn er svekket eller satt ut av spill. Dette kan skje hvis ekspertene er for dominerende – for eksempel i softwarebedrifter startet av utviklere, som gjerne vil utvikle i visse verktøy og med visse typer løsninger, uansett hva kundene sier. Sålenge etterspørselen er stor går dette greit, men all teknologi som er ny og banebrytende blir ganske fort gjenstand for konkurranse – og da holder det ikke å sortere køen lenger.
Markedssiden kan også svekkes ved at den blir offentlig regulert, slik det f.eks. er i offentlig helsevesen og tildels i utdanning. Et sykehus i Norge skal levere til alle, betalt av det offentlige, og kan ikke sette opp prisen for å få ned etterspørselen. Dermed kan man få en situasjon med for høy etterspørsel i forhold til kapasitet. Resultatet er ofte overspesialisering – en lege kan ikke behandle alle, og ikke sette opp prisen, så da er svaret ofte å begrense hva slags pasienter man kan ta ut fra kategorisering, til mengden pasienter er overkommelig. (Merk: Jeg argumenter ikke for en privatisering av helsevesenet i Norge her, men vil bare påpeke at fravær av markedsmekanismer kan skape sine egne problemer.) Resultatet er, som jeg tidligere har påpekt, at det helhetlige pasientperspektivet blir borte og pasienter i stedet oppfattes som enkeltdiagnoser.
Produktiv spenning
En velfungerende kunnskapsorganisasjon har hva jeg kaller en produktiv spenning mellom kunnskaps- og markedssiden, der kunnskapssiden har folk som forstår kundenes perspektiv og behov uten å gå på akkord med hva de kan og vil levere, og markedssiden har nok spesialkunnskap til å kunne forme og kommunisere kundesiden uten å overselge. Dette krever også gjensidig respekt for hverandre egenart – at de som selger forstår at fagfolkene er slik de er fordi de bryr seg om kvalitet og utvikling, at de som er fagspesialister forstår at disse folkene i dress faktisk gjør et viktig arbeid med å sile kundekrav og vurdere gjennomføringsevne slik at fagfolkene slipper.
Denne balansegangen mellom fag og marked er den sentrale lederutfordringen i kunnskapsbedrifter, og en av grunnene til at markedskontakten for en kunnskapsbedrift – enten den er et konsulentselskap, en høyskole eller et sykehus – bør ivaretas eller i alle fall nøye overvåkes av folk med lang erfaring fra begge sider.
Som en svært erfaren konsulentleder sa til meg for mange år siden: Denne bransjen – rådgivning – «er den eneste bransjen hvor du forfremmes til selger». Den erkjennelsen kan være vanskelig å ta for en ekspert som helst vil drive med sitt fag (og kanskje grunnen til at ikke alle eksperter skal bli ledere). Det betyr også at dette kundeperspektivet ikke er noe som kan delegeres uten videre til en stab av selgere – i hvert fall ikke uten at de har dyp kjennskap og et edruelig forhold til hva organisasjonen kan og ikke kan levere.
Så, kjære ekspert – husk at du kommer til å ende opp som selger, og planlegg deretter…
Jeg elsker elegant og presist språk – le mot juste, som Flaubert kalte det – og ChatGPT, Claude, og andre store språkmodeller irriterer fletta av meg med sin utrettelige flom av vokabulært overdimensjonerte omtrentligheter.
Ikke desto mindre er GenAI et faktum. Man kan skaffe seg et abonnement på ChatGPT eller bruke gratisversjonen, eller ta i bruk ulike integrasjoner (med Microsofts CoPilot som den klart vanligste). Felles for denne bruken er at initiativet til å ta i bruk systemet kommer fra enkeltindivider, enten man ber systemet foreslå et svar på en kjedelig epost, skrive en tale til det neste julebordet, eller skrive firmaets strategi (noe forbausende mange selskaper ser ut til å gjøre – luftige ord uten styringssignaler…).
Det er positivt, gir en produktivitetseffekt på enkeltpersonsnivå – i hovedsak at man bruker mye mindre tid på å generere innhold og noe mer på å kontrollere det – men som vi alle vet: De virkelige endringene kommer når vi legger om våre prosesser og organisasjoner etter hva teknologien kan tilby – når vi går fra hesteløse kjerrer til skikkelige biler, for eksempel. Hva kan vi forvente når GenAI ikke lenger omtales som GenAI, men bare er en alminnelig del av systemer og prosesser? Hva kan GenAI egentlig gjøre på organisasjonsnivå?
Skal vi forstå det, må vi se på hva slags underliggende funksjonalitet teknologien tilbyr – eller for å si det med Clayton Christensen: Hva slags jobber kan du ansette ChatGPT til å gjøre?
For meg er det tre hovedjobber: Konversasjon, destillasjon, og fabrikasjon.
Konversasjon: GenAI som samtalende grensesnitt
Et samtalende grensesnitt – conversational interface – er noe vi har vent oss til å bruke etter at søkemotorer ble den vanlige måten å finne informasjon på. Tenk litt på forskjellen på å søke i en database og i en søkemotor: Mot en database må du fortelle ikke bare hva du ser etter (f.eks. alle transaksjoner over et visst beløp), men også hvordan dette skal uttrykkes overfor maskinen – f.eks. med et SQL-utsagn (SELECT id, customer, item FROM transaction_table WHERE sum > 10000). Databasesøk er effektivt og presist, men krever at du skriver søkestrengen svært spesifikt. Hvis det ikke finnes noen transaksjoner som tilfredsstiller kriteriene, får du heller ikke noe svar. Enten er informasjonen der, og da kan du stole på den, ellers får du ingenting.
En søkemotor er noe vennligere: For det første forstår den mer av hva du skriver inn – query processing – og tolererer stavefeil, synonymer og rotete ordstilling. For det andre vil den (nesten) alltid returnere et resultat, som kanskje er feil, men som er den biten informasjon som søkemotoren mener er tettest opp til det du spør om. Dette kan være unøyaktig, men søkemotoren returnerer alltid en peker til et underliggende dokument, som du kan lese og vurdere kvaliteten og påliteligheten av.
Årsaken til at man kaller det et samtalende grensesnitt, er at du skriver et søk, ser resultatet systemet foreslår, og så prøver deg med et mer presist søk inntil du finner det du vil ha. Du har en samtale med systemet – og systemet vil alltid vise et resultat, om enn unøyaktig eller irrelevant. Hva systemet skal svare, er et resultat av hva slags informasjon det har oversikt over, den underliggende søkealgoritmen, men også hva slags resultater eieren av systemet ønsker skal vektlegges.
Generativ AI tar dette samtaleelementet videre, og gir ikke bare lenker til kilder, men setter sammen innholdet i svaret basert i hovedsak på hva den har sett av lignende tekster. Det gjentas ofte til kjedsommelighet at alt en språkmodell gjør, er å forsøke å gjette det neste ordet i en setning – den har ingen formening, i alle fall ikke i utgangspunktet, om hva noe betyr. Når den likevel kan fremstå som både kunnskapsrik og konversant, er det fordi vår egen kunnskap er begrenset og skriftlig språk er lite presist som informasjonsbærer.
Så der vil du finne GenAI – som samtalepartnere i neste generasjon søkesystemer, med evnen til alltid å komme opp med et svar på selv de mest håpløse spørsmål. Den vil være uendelig tålmodig (og dermed både et verktøy for og et våpen mot kommentarfeltets ankelbitere) og har ubegrenset selvtillit. Den gir alltid et svar, men glir rundt grøten og lar seg lett påvirke av populære (eller i alle fall populistiske) meninger. Kvaliteten øker med bruk, siden den er lærenem, men med en målfunksjon preget av mange lokale minima kommer den ikke med reell problemløsning, bare forslag basert på hva den har sett før.
Destillasjon: Umenneskelig apetitt for gørrkjedelighet
Where is the «brief insightful summary» button on the keyboard? P. J. O’Rourke
Her forleden hørte jeg en presentasjon fra en toppleder som fortalte at hans styre hadde mottatt en 1100 siders rapport fra administrasjonen. Han hadde spurt om de ikke skulle lage et executive summary for styremedlemmene, men hadde fått beskjed om at det kunne de ikke gjøre, for det var viktig at styret hadde lest hele rapporten. Jeg vet ikke hva slags styremedlemmer det var i det styret, men jeg klarer ikke å få doktorgradsstudenter til å lese 1100-siders rapporter, så jeg betviler sterkt at noen av styremedlemmene kom seg gjennom det hele, ei heller i hvilken grad innholdet ble gjenstand for en læreprosess.
Hadde dette styremøtet funnet sted i dag, kunne medlemmene ha kjørt hele greia inn i en språkmodell (forhåpentligvis en med kommersiell lisens, slik at teksten ikke ble del av modellens korpus) og fått ut akkurat så mye oppsummerings om de ønsket. Kommersielle språkmodeller trenes opp ved å lese masse tekst (f.eks. lovtekster, tekniske manualer eller ulike policy-dokumenter) og kan deretter besvare enkel spørsmål om dem – eller summere dem. Dette er supert for studenter som ikke gidder lese for mye (men heller ikke lærer stort) og kjempefint for folk som trenger en kjapp oversikt over hva en bok eller en samling artikler inneholder.
Kvaliteten av oppsummeringen er definitivt caveat emptor – mottakers ansvar – men i en situasjon der det ikke er mulig å komme seg gjennom hele materialet, kan en destillert versjon, produsert om ikke på sekunder, så i alle fall på minutter, være bedre enn å måtte pløye gjennom alt sammen. For advokatfirma, revisorer, konsulentselskaper og innen corporate banking, der enorme tekstmengder skal leses og kontrolleres – for eksempel innen due diligence-prosesser – vil språkmodeller være et nyttig hjelpemiddel, om enn ikke en erstatning.
Et problem her er at forretningsmodellen til slike selskaper ofte er bygget på at kunden betaler (med god margin) kostnaden for alle dem (som regel juniorer) som gjør lesejobben og sammenstillingen. Dette er også der selskapene rekrutterer sine fremtidige ressurser. Jeg har hørt endel ledere innen konsulentselskaper snakke begeistret om reduserte personalkostnader ved bruk av AI, uten at det ser ut til at de er helt klar over at kundene for det første kan bruke disse verktøyene selv, for det andre at deres betalingsvillighet kommer til å gå ned i takt med kjennskap til de nye verktøyene.
Når prisen på en tjeneste går ned, kan vi spare penger, men like ofte skjer det at bruken øker. For språkmodellers vedkommende betyr det at ting som tidligere tok lang tid (lese en artikkel) eller var umulig (lese alle artikler om et tema) nå kan gjøres kjapt og greit, om enn med mindre nøyaktighet og en liten fare for juridiske konsekvenser.
Fabrikasjon: Når originalitet verken er nødvendig eller verdifullt
Amazon has created a new rule limiting the number of books that authors can self-publish on its site to three a day. The Guardian
Språkmodeller er fabelaktige til å generere tekst og annet innhold – Googles NotebookLLM, for eksempel, produserer podcasts basert på artikler du mater inn. Men du skal ikke ha lest mye slikt innhold (eller hørt på en generert podcast i bilen) før en følelse av hjerneråte setter inn.
Årsaken er at tekstene ikke er originale, noe i hvert fall min hjerne registrerer nokså fort, og at det derfor blir som å spise loff til morgen, lunsj og middag i årevis.
Nå er det slik at en hel del tekster som er nødvendige (og ofte pålagt) innen samfunns- og næringsliv ikke må være originale, for å si det forsiktig. Selv har jeg startet firma og bedt ChatGPT genere vedtekter og annet materiale som skled greit gjennom Brønnøysund. Digitalisering har gjort det enkelt for lovgivere å be om materiale og rapporter, websider skal dynamisk oppdateres, og pressemeldinger om dette og hint skal skrives.
Det som først og fremst kommer til å sørge for mye tekstproduksjon Det er mange eksempler på det – digitalisering gjør det svært enkelt å be om en rapport – men det som først og fremst kommer til å virkelig sette fart i svadaproduksjonen er kravene til ESG-rapportering som nå pålegges alle selskaper. Det begynner med de børsnoterte, men kravene siger nedover til alle underleverandører, noe som allerede har ført til at endel store innkjøpere nå handler lokalt eller innen EU i stedet for å hente varer fra fjernere (og billigere) strøk. Endel krav er lite kjent: Åpenhetsloven, for eksempel, krever dokumentasjon av forsyningskjeder og underleverandører og nesten øyeblikkelig generering og levering av den informasjonen til alle som spør. Kan man ikke det, blir det dyrt, noe et klesfirma nylig oppdaget etter å ha blitt gjenstand for et skoleprosjekt.
Bedrifter generelt har verken økonomi eller ledelseskapasitet til å bygge opp et rapporteringsregime like stort som økonomifunksjonen, spesielt siden det for de fleste bedrifters vedkommende vil ha noen effekt på salg eller produktutvikling. For å si det litt kynisk: Språkmodeller kan bli svært verdifulle ved å automatisere grønnvasking, fordi de kan mer enn å skrive «bedriften forurenser ikke det ytre miljø.»
Bullshit jobs no more
With AI, it is much easier to replace a doctor than a nurse. Yuval Harari, Nexus
Nå er det slik at det meste av arbeidsoppgavene ovenfor – interaksjon, sammenstilling og generering av standardtekster – i dag gjøres av mennesker, i jobber som i mange tilfelle kan defineres som «bullshit jobs«. Det er få som har som sin brennende ambisjon å være grensesnittet mot et kronglete system, leser av kjedelige tekster, eller produsent av innhold ingen egentlig etterspør.
Ikke desto mindre er det disse jobbene som sørger for kjøpekraft for en betydelig del av befolkningen – og reisen fra samlebånd til customer support er ingenting i forhold til reisen fra brukbar informasjonsarbeider til genuin innholdsprodusent.
Det er dukat för konflikt når venstrehåndsarbeidet forsvinner og alminnelig nyskapning blir en hygienefaktor.
Jeg frykter ikke fotografiet, det kan ikke brukes i himmelen eller helvetet. Edvard Munch
I Martin Amis’ kostelige roman Lucky Jim finner vi denne beskrivelsen av en skikkelig dagen derpå:
Dixon was alive again. […] The light did him harm, but not as much as looking at things did; he resolved, having done it once, never to move his eye-balls again. A dusty thudding in his head made the scene before him beat like a pulse. His mouth had been used as a latrine by some small creature of the night, and then as its mausoleum. During the night, too, he’d somehow been on a cross-country run and then been expertly beaten up by secret police. He felt bad.
Jeg er ganske sikker på at en slik beskrivelse ikke er noe en språkmodell kan komme opp med. Og det er ikke fordi språkmodeller ikke kan bli bakfulle (eller i alle fall late som de er det), men fordi originalitet krever at man kjenner reglene for hvordan noe skal gjøres – og deretter å bryte dem.
Originalitet er viktig, blir viktigere, og vil alltid vil bli premiert. Det er bare det at terskelen for hva som er originalt og nyskapende nå er lagt så mye høyere. Verden kan, for å sitere Paul Graham, bli delt inn i de som skriver godt og de som ikke kan skrive i det hele tatt.
Det blir med andre ord mer og mer verdifullt å finne le mot juste…
Lykke til!
Dette innlegget ble først publisert på Comunita.no, et nettverk av ledere og forretningsutviklere innenfor mange interessante firma. Ta kontakt om du ønsker mer informasjon, eller kanskje et medlemsskap?
Data er det nye gullet, sies det. Men da må vi gjøre det dataene sier.
(Denne bloggposten ble først publisert på bloggen til Comunita, et ledernettverk jeg har startet sammen med Haakon Gellein. Der diskuterer vi medlemmenes utfordringer – i dette tilfelle en stor organisasjon som ønsker å bli mer datadrevet – og jeg skriver blogginnlegg som forberedelse til disse møtene. Vi tar opp nye medlemmer etter vurdering – ta kontakt om du ønsker mer informasjon.)
Mange bedrifter og organisasjoner har enorme mengder data, men utnytter dem ikke. Det er det mange årsaker til – som manglende analysekunnskaper, manglende tradisjoner, eller manglende konkurranse. Men etterhvert som vi får flere og flere eksempler på bedrifter og organisasjoner som gjør suksess ved å skaffe seg data og utnytte dem, øker kravet om å være data-drevet. Hva betyr det egentlig – og hvordan får man det til?
La oss ta for oss en bedrift i en bransje som kanskje ikke ligner så mye på noe i Norge (bortsett fra Norsk Tipping, og de er jo data-drevet) men der utviklingen viser hva man kan få til ved å ta tak i de dataene man har – og gjøre som dataene viser.
Et kasinoeksempel
Da jeg var doktorgradsstudent en gang for hundre år siden (vel, 1991) møtte jeg i noen seminarer en nyansatt professor ved navn Gary Loveman. Gary var statistiker og økonom og spesielt interessert i sammenhengen mellom lønnsomhet og kundelojalitet. Han var også nokså ulik mange av de andre professorene både av utseende og humør. Jeg fikk litt inntrykk av at han ikke tok livet – og i hvert fall ikke seg selv – så veldig høytidelig.
Gary drev litt som konsulent på si. En av kundene hans var Harrah’s, et relativt lite kasino i Las Vegas. Kasinoet gikk ikke bra – som Gary sa det (se hans suverene foredrag på Berkeley for noen år siden): «Vi hadde et kasino som kostet 315 millioner dollar (det er lite i Las Vegas) å bygge. Ved siden av oss kom det et nytt kasino til 1,6 milliarder, og tvers over gaten ville det komme et 9,2 milliarder. Det er ingen som tar inngangspenger i Las Vegas. Hvordan skulle vi få kundene til å komme til oss?»
Firmaet hadde store problemer – så store at de gikk til en akademiker for å finne ut hva de skulle gjøre. Gary hadde skrevet artikkelen Put the Service-Profit Chain to Work sammen med endel kolleger og fant ut at i dette kasinoet kunne han se modellen fungerte i praksis. Men før han kunne finne ut hva han skulle gjøre, måtte han finne ut hvem kundene var og hva de likte.
Markedsføring i Las Vegas den gangen handlet mye om å få tak i de store spillerne, de som flys inn med helikopter, får gratis suiter og middager og legger igjen millioner ved roulette-bordene. Etter endel analyse fant Gary ut at de virkelig attraktive kundene ikke var storspillerne (som alle de andre kasinoene gikk etter), men «vanlige folk» – håndverkere, lærere, leger, annen middelklasse – som spilte mindre, men som det var mange flere av. Han introduserte det første kundelojalitetsprogrammet i bransjen, basert i mindre grad på hvor mye folk spilte og i større grad hvor ofte de besøkte kasinoet. Kundene satte pris på å bli skikkelig behandlet uten å være millionærer, og Harrah’s vokste fra å være et lite kasino i skyggen av Ceasar’s Palace til å bli verdens største kasinoselskap (som faktisk i dag heter Ceasar’s Entertainment, et tilfelle av David som bokstavlig talt kjøpte Goliat).
Datadrevne kjennetegn
En av utsagnene som Gary har blitt kjent for, at det er bare tre ting du kan få sparken for i hans organisasjon: Tyveri, seksuell trakassering, og å gjøre en endring uten å ha en kontrollgruppe.
De to første er kanskje ikke så vanskelige å forstå, men den siste krever litt forklaring. Nå man gjør et vitenskapelig eksperiment – for eksempel utprøving av en ny medisin – gir man den ikke til alle pasientene, men til en tilfeldig utvalgt gruppe. Kontrollgruppen er de som ikke får den nye medisinen, men i stedet behandles som tidligere. Etterpå måler man om det er forskjell på de to gruppene – og om forskjellen er tydelig og stor nok, går man over til den nye måten å gjøre ting på.
Innenfor medisinsk forskning gjøres dette dobbeltblindt – verken pasienten eller legen vet hvem som får ny medisin og hvem som ikke gjør det. Det kan det være vanskelig å få til i mange sammenhenger – det er derfor det er så vanskelig å forske på ernæring, siden vi vet hva vi spiser – men det er mange bedrifter som driver med dette i stor stil: Finn.no, for eksempel, slik jeg skrev om i en artikkel i Magma for noen år siden.
Dette at man insisterer på at alt som skal endres, skal testes først, er et av de fremste kjennetegnene på at en bedrift er data-drevet: Man lytter til dataene, og gjør som dataene sier.
Hvorfor er dette så vanskelig?
Problemet med data er at de ikke alltid forteller deg den historien du vil de skal fortelle. Når det skjer, må man velge om man skal tro på dataene eller på sin egen magefølelse – og pussig nok er dette vanskeligere jo bedre man er i jobben. Chris Argyris, en annen Harvard-professor, skrev en berømt artikkel kalt Teaching Smart People How to Learn, om nettopp dette at kompetente mennesker i ledende stillinger med lang erfaring er de som har størst vansker med å lytte til data – rett og slett fordi de har kommet til sine stillinger ved å ha hatt rett. Hittil, i alle fall.
Av og til kan hele bransjer la være å lytte til dataene – i forsikringsbransjen, for eksempel, brukes masse dataanalyse for å finne ut av hvorfor kunder forlater et forsikringsselskap til fordel for et annet. Svaret er det samme hver gang: Den fremste grunnen til at folk forlater et forsikringsselskap er at de har hatt en forsikringshendelse og ikke er fornøyd med hvor mye penger de har fått utbetalt. Det er det ingen i bransjen som ønsker å gjøre noe med. Innenfor utdanning er vi ikke noe bedre: Den fremste prediktoren for suksess for bachelorstudenter, for eksempel, er matematikkunnskaper når man begynner på studiet. Men det er det vanskelig å gjøre noe med, så da satser vi på motivasjon og inspirasjon i stedet…
Fokus på data og kontinuerlig innovasjon gir resultater – bare spør Gary. Eller Finn.no. Eller Google. Eller VG.no, som ble Norges største online avis ved kontinuerlig oppdatering av hva som står på førstesiden basert på hvordan leserne reagerer.
Reelle farer ved dataorientering
Det å være dataorientert er ikke uten kostnader og farer. Analyse koster, i tid og penger. Å betale de ansatte for å gjøre slik dataene sier – i Harrah’s tilfelle, å betale bonuser basert på kundetilfredshet – koster.
Blir man for data-drevet, kan man komme til skade for å havne i en slags analysis paralysis der man ikke tør ta sjanser eller ikke gjør noe fordi man ikke klarer å komme på hvordan man skal teste det. Men den risikoen er adskillig mindre, i de fleste tilfeller, enn at man går glipp av innovasjoner fordi noen med beslutningsmyndighet i organisasjonen ikke har den rette følelsen for at noe bør gjøres.
Gary Loveman sier selv at hans fokus på at alt skal analyseres og dokumenteres – og at han ikke har noen personlige aksjer i hvilken løsning som blir valgt – fører til at han unngår å gjøre mange feil, at han unngår å gjøre ting han ikke burde gjøre. De som jobber mer inspirasjons- og intuisjonsbasert, vil gjøre en hel del spektakulære feil. Men de vil også av og til gjøre noe smart på tross av alle analyser og alle data.
Så får man velge – men jeg vil tro at for de fleste organisasjoner som har med kunder å gjøre, enten de er innenfor det private eller det offentlige, har mer å hente på å være data-drevne enn det motsatte.
Det som i alle fall er sikkert, er at om du lar din innovasjonsstrategi bestemmes av en gruppe ledere uten kundekontakt, basert på hvem som har det mest nøyaktige prosjektregnskapet og den proffeste PowerPoint-bunken, så lever du farlig.
Heskett, J. L., T. O. Jones, G. W. Loveman, W. E. Sasser, Jr. and L. A. Schlesinger (2008). «Putting the service-profit chain to work.» Harvard Business Beview86(7-8): 118.
I mai startet en debatt om hvorvidt ChatGPT bli dårligere. Til å begynne med var det brukere som syntes ting gikk nedover, men etterhvert har forskere og guruer meldt seg på og konstatert at svarene til ChatGPT (i hvert fall innenfor områder der det er mulig å måle kvalitet, som matematikk), typen sensitive spørsmål som kan besvares, koding og tolkning av bilder, har ting blitt dårligere over tid.
Årsaken er, paradoksalt nok, at OpenAI, firmaet bak ChatGPT, gjør endringer i algoritmene for å forbedre ChatGPT, for å øke kvaliteten og hindre at systemet blir brukt til ting det ikke skal brukes til. Og dermed synker altså den opplevde kvaliteten.
Dette paradokset er interessant fordi det illustrerer to fundamentale tilnærminger til kunnskapsbaserte systemer (som jeg synes er et mye bedre uttrykk enn «kunstig intelligens», av mange grunner).
Logiske modeller På 80-tallet, da jeg begynte å rote rundt med det som den gang ble kalt AI, var AI så og si synonymt med ekspertsystemer – det vil si systemer som kunne besvare spørsmål ved å etterligne hva en ekspert gjorde (og som ofte var laget ved at man intervjuet eksperter). De ble programmert som en rekke spørsmål – «Er pasienten kortpustet?», «Hvor mye røyker han?» – og stiller så en diagnose basert på beslutningstrær. I dagliglivet treffer du denne typen systemer som chatbotene som i alle fall forsøker å besvare enkle spørsmål i banken og andre steder man henvender seg.
Statistiske modeller På slutten av 80-tallet (vel, egentlig mye tidligere, men de ble vanligere da) kom nevrale nettverk og andre, mer statistisk baserte metoder, som tok utgangspunkt i store mengder data og konstruerte modeller som kunne klassifisere ting. I motsetning til ekspertsystemene, som var basert på en logisk modell av hvordan folk tenker, tok disse metodene inspirasjon fra en fysisk (og, for all del, teoretisk) modell av hvordan hjernen virker. De prøver seg frem til de finner en modell som gir ønsket resultat, ofte ved å konstruere nettverk av enkeltinformasjonselementer som er forbundet, og der forbindelser mellom elementer styrkes eller svekkes gjennom prøving og feiling.
ChatGPT og andre store språkmodeller hører til denne typen systemer: De forsøker å gjette det neste ordet i en setning rett og slett ved å ha lest enorme mengder tekst og velge det ordet som er mest sannsynlig.
Forskjellige feilmodus Disse systemene har mange forskjeller – en av dem er hvordan de gjør feil. Ekspertsystemene er nokså enkle – hvis de ikke finner et svar, sparker de problemet videre til noen som har svaret, som regel en person. De kan selvfølgelig også svare feil – men da er det som regel nokså enkelt å forstå at svaret er feil, siden det ser urimelig ut. De er på mange måter å sammenligne med søk i databaser, der man må være nokså presis i hva man spør etter, og databasen vil svare at den ikke har noe som passer hvis så er tilfelle.
Statistisk baserte modeller, derimot, vil alltid gi et svar. Slik er de mer å sammenligne med søkemotorer, som alltid vil forsøke å gi deg noe, selv om det ikke passer. (Når fikk du sist en melding fra Google om at det ikke fantes noen sider som oppfylte dine kriterier?) Svarene kan være riv ruskende gale, men vil se troverdige ut. En generativ språkmodell, som ChatGPT, har ingen underliggende fornuft, den forsøker bare å gjette hvilket ord som passer best, gitt de ordene som kom før.
Når kvalitetskontrollen roter til ting Et problem med de statistisk baserte modellene, i alle fall de som bruker nevrale nettverk, er at de kan bli riktig gode på å kategorisere ting – billedgjenkjenning, tekstgjenkjenning, tekstfortolkning – uten at man kan forklare, i alle fall på en måte mennesker kan forstå, hvordan de gjør det. Det kan også gjøre store logiske feil: Selv om ChatGPT kan skrive pressemeldinger og eksamensoppgaver som ser tilforlatelige ut, gjør den logiske feil – noe som ofte viser seg i at den produserer falske referanser, det vil si lager en referanseliste med artikler som ikke finnes. (Biblioteket på BI rapporterer om studenter som dukker opp og skal ha artikler av denne typen.) Den kan godt generere en caseanalyse eller en sosiologisk drøfting – der er jo grunnlaget ord (og mange av dem). Men folk som har bedt den skrive en artikkel innen fysikk eller matematikk, sier at den produserer noe som ser svært tilforlatelig ut hva teksten gjelder, men formler og formell deduksjon er helt håpløst.
Det betyr at man må putte på en eller annen form for kvalitetskontroll som er logisk basert – altså bruke ekspertsystemlogikk til å kontrollere det som genereres. Dette kan gjøres på mange måter: Man kan ha en inputkontroll (slik at folk ikke kan be ChatGPT skrive noe rasistisk eller instruksjoner for å lage en atombombe). Man kan kombinere ChatGPT med logiske systemer – for eksempel Matematica, Stephen Wolframs matematikkprogrammeringssystem, som nå integreres med ChatGPT.
Og det er her det ser ut til at det blir vanskelig.
Siden man ikke helt vet – i hvert fall ikke i detalj – hvordan ChatGPT produserer et tekststykke, blir det svært vanskelig å introdusere kvalitetskontroll eller andre begrensinger rett i modellen. Man blir henvist til enten å filtrere input og output – og det gjøres i stadig større utstrekning – eller (svært forenklet) å legge begrensinger på hva slags tekstmateriale som kan brukes som underlag for å generere ny tekst.
Jeg har litt følelsen at OpenAI (og deres konkurrenter) har laget ChatGPT og andre modeller, og nå står og ser på denne maskinen og ikke helt forstår hva de har laget. Jeg hadde en gammel og komplisert Mercedes for noen år siden. Den var kul (syntes jeg i alle fall), men jeg kunne jo ikke skru på den selv fordi den var så komplisert, og visste at nesten enhver ting jeg gjorde, hadde mye større sannsynlighet for å rote ting til enn å gjøre den bedre.
Men bare vent… Så det er ikke helt tid for å sparke kommunikasjonsavdelingen ennå – men kanskje tid for å ha flere folk til å kontrollere resultatet enn å generere innholdet. Ledere jeg kjenner, har kommentert at eposter de får har blitt lengre, høfligere og med rikere vokabular. Men jeg ville ikke helt automatisert epostene mine ennå, og slett ikke om de inneholder konkrete fakta og definitive avgjørelser.
Hva den automatiske kvalitetskontrollen gjelder, så er det fremdeles tidlig i språkmodellenes utvikling – hvis vi regner ChatGPT som begynnelsen. Men ChatGPTs røtter ligger i forskningen til Frank Rosenblatt fra tidlig sekstitall og Rumelhart og McClellands bok fra 1987 – og sett i det perspektivet er ChatGPT det foreløpig siste skrittet på en lang reise.
Da elektrisiteten kom, kom det også allslags finurlige apparater som skulle gi bedre hårvekst, bedre potens, og for alt jeg vet mer intelligens. Det samme gjaldt radium, kaffe, poteter og mye annet. Nå for tiden er det vel antioksydanter og AI som i har rollen som universalløsning. Over tid får man et mer edruelig forhold til fenomenet, bedre oversikt over bivirkninger, og fremfor alt bedre forståelse for hva det kan brukes til.
Så ChatGPT råtner egentlig ikke. Teknologien har i stedet startet på en prosess som over tid vil gjøre teknologien bedre, mer pålitelig, og med mer presist definerte bruksområder. Jeg tror mer på en gradvis forbedring enn en revolusjon der ChatGPT 7 eller 8 tar over verden. I mellomtiden forsøker jeg å lære meg å bruke de nye verktøyene smart – og insisterer på at de er verktøy og ikke noe annet.
Her forleden deltok jeg i en podcast fra Oslo Business Forum om plattformøkonomi og forretningsmodeller med Jens Hauglum, produktdirektør i Finn.no, og Christian Brosstad fra Atea Norge. Resultatet er tilgjengelig på Spotify og Apple. Det ble en hyggelig liten time med temaer som nettverkseksternaliteter, handelsvertikaler og algoritmeregulering.
EU har kommet med et forslag til nye lover som regulerer bruk av AI i bedrifter og organisasjoner. Såvidt jeg kan se, ligner forslaget på GDPR-lovgivningen: Ansvarliggjøring av styre og ledelse, bøter basert på omsetning ved overtredelser, og (sannsynligvis) et eller annet i retning av «safe harbor» bestemmelser slik at man kan være nogenlunde sikker på at man ikke gjør noe galt.
Et interessant aspekt her er at EU er tidlig ute i forhold til bruken av AI (ja, jeg vet det er et upresist begrep, men la det ligge foreløpig) og at man igjen tar ledelsen innen regulering der Silicon Valley (og Kina) har tatt ledelsen innen implementering.
Jeg skal finne ut mer om dette, i første omgang ved å høre på et webinar på konferansen Applied Artificial Intelligence Conference 2021. Seminaret (27. mai kl. 1430-1600) er åpent for alle som registrerer seg, og vil bli fasilitert av Elin Hauge, som er medlem av EGN AI og maskinlæring, et av EGN-nettverkene jeg leder.
Her forleden hadde jeg en hyggelig samtale med Eirik Norman Hansen – en gang min student, nå er ikke aldersforskjellen så voldsom lenger – om dataanalyse og hvorfor mange bedrifter sliter med det. Noe av det ble en podcast, her er detaljene:
Nok en kommentar i digi.no, denne gangen om et svært viktig tema, som dessverre har blitt litt borte i diskusjonen om personvern og smittesporing. Jeg liker ikke konspirasjonsteorier og alt som har med Covid-19 haster, men før man lanserer noe som sporer folk overalt må man vite at det faktisk gir den effekten man er ute etter.
.Alle datakilder og alle modeller har feil. Det må vi leve med. Det vi må vurdere, er om feilene er store nok til at vi ikke kan bruke resultatet.
Det har vært noen hektiske uker – for min del med å flytte undervisning online og hjelpe kolleger og andre med det samme. COVID-19 har virkninger på kort sikt, men også svært interessante konsekvenser på lengre sikt, spesielt innenfor digitalisering. For meg er det ikke tvil om at bedrifter med høy digital kompetanse, endringserfaring og en eksisterende digital tilstedeværelse nå virkelig har sjansen til å løpe fra konkurrentene – hvis ledelsen kjenner sin besøkelsestid.
Samtidig er jeg klar over at dette er vanskelig for mange, kanskje de fleste. Det er mange grunner til at man har latt det digitale ligge, som regel fordi andre ting er har (helt legitimt) vært viktigere. Jeg har (selvfølgelig) masse oppfatninger om hva man kan gjøre rundt det å digitalisere og utvikle sin bedrift i denne situasjonen.
Men så slår det meg – kanskje jeg ikke skal gå ut fra hva jeg tror og mener i denne situasjonen, men heller spørre: Alle dere som er ledere i små og store bedrifter der ute: Hva er vanskelig akkurat nå, hva trenger dere hjelp til å få til?
Dette er ikke starten på et kommentarfelt eller en artikkel – send meg en (konfidensiell, naturligvis) epost på self@espen.com, så skal jeg (om det er aktuelt, lover ikke) summere opp og rapportere tilbake.
Og for all del: Del dette innlegget med hvem du vil, jo flere jo bedre!
Jeg slo på radioen i bilen i går og inne i mellom all viruspraten (som jo i prinsippet handler om matematiske spredningskurver) fikk jeg høre to matematikklærere, begge tydeligvis flinke folk (de har begge skrevet lærebøker) som strevet med å artikulere nytten av matematikk for sine elever. Det er ikke enkelt å snakke på direkten, særlig når programlederen starter med den vanlige «jeg har ikke hatt nytte av matematikken» tiraden, men debattartikkelen det hele bygger på, er velskrevet og bra – bortsett fra overskriften (som er det de fleste leser, og som forfatteren ikke setter selv.)
Skal ungdom forstå hvorfor de skal lære matematikk, må vi være direkte. Så derfor vil jeg nok en gang å gjengi mine grunner til å lære matematikk, denne gang oppdatert med et punkt til – om klima og forurensning og (hvorfor ikke) pandemier.
Du skal lære matematikk for å bli smartere. Matematikk er for læring hva kondisjons- og styrketrening er for idrett: Grunnlaget som setter deg i stand til å bli bra i den spesialiteten du ender opp med. Du blir ikke idrettsstjerne uten å ha god kondis. Du blir ikke stjerne innen din jobb eller flink i dine fag uten å kunne tenke smart og kritisk – og matematikk lærer deg det.
Du skal lære matematikk for å tjene mer penger. Idol-vinnere og andre kjendiser tjener penger, men det er få av dem, og de fleste tjener bare penger i noen få år. Deretter er det tilbake til skolebenken. Dersom du kutter ut Idol-køen og TV-fotball og i stedet gjør leksene dine – særlig matematikken – kan du gå videre med en utdannelse som gir deg en godt betalt jobb, for eksempel innen stordataanalyse og kunstig intelligens. Du vil tjene mye mer enn popsangere og idrettsfolk – kanskje ikke med en gang, men helt sikkert når du regner gjennomsnitt og over hele livet.
Du skal lære matematikk for å tape mindre penger. Når massevis av mennesker bruker pengene sine på dårlige investeringer, inkludert pyramideselskaper, forbruksgjeld og tilbud som er for gode til å være sanne, så er det fordi de ikke kan regne. Hvis du skjønner litt statistikk og renteregning, kan du gjennomskue økonomiske løgner og luftige drømmer. Med litt naturfag i bagasjen blir du sikkert friskere også, siden du unngår alternative medisiner, krystaller, magneter, homøopati, shamaner og annen svindel fordi du vet det ikke virker.
Du skal lære matematikk for å få det lettere senere i studiene. Ja, det kan være endel jobb å lære seg matematikk mens du går i videregående. Men når du kommer videre til universitet eller høyskole, slipper du ofte å pese deg gjennom hundrevis av overforklarende tekstsider. I stedet kan du lese en formel eller se på en graf, og straks forstå hvordan ting henger sammen. Matematikk er mer kortfattet og effektivt enn andre språk. Kan du matematikk, kan du jobbe smart i stedet for hardt.
Du skal lære matematikk fordi du skal leve i en global verden. I en global verden konkurrerer du om de interessante jobbene med folk fra hele verden – og de smarteste studentene i Øst-Europa, India og Kina kaster seg over matematikk og andre “harde” fag for å skaffe seg en billett ut av fattigdom og sosial undertrykkelse. Hvorfor ikke gjøre som dem – skaffe seg kunnskaper som er etterspurt over hele verden, ikke bare i Norge?
Du skal lære matematikk fordi du skal leve i en verden i stadig endring. Ny teknologi og nye måter å gjøre ting på endrer hverdag og arbeidsliv i stadig større tempo. Hvis du har lært din matematikk, kan du lære deg hvordan og hvorfor ting fungerer, og slippe å skrape deg gjennom arbeidsdagen med huskelapper og hjelpetekster, livredd for å trykke på feil knapp og komme ut for noe nytt.
Du skal lære matematikk fordi det lukker ingen dører. Hvis du ikke velger full matematikk i videregående, lukker du døren til interessante studier og yrker. Du synes kanskje ikke disse yrkene og studiene er interessante nå, men tenk om du skifter mening? Dessuten er matematikk lettest å lære seg mens man er ung, mens samfunnsfag, historie, kunst og filosofi bare har godt av litt modning – og litt matematikk.
Du skal lære matematikk fordi det er interessant i seg selv. Altfor mange mennesker – også lærere – sier matematikk er vanskelig og kjedelig. Men hva vet de om det? Du spør ikke bestemoren din hva slags smarttelefon du skal kjøpe? Du ber ikke foreldrene dine om hjelp til å legge ut noe på Tiktok? Hvorfor spørre noen som aldri lærte seg matematikk om du skal lære matematikk? Hvis du gjør jobben og holder ut, vil du finne ut at matematikk er morsomt, spennende og intellektuelt elegant.
Du skal lære matematikk fordi du kommer på parti med fremtiden. Matematikk blir viktigere og viktigere innen alle yrker. Fremtidens journalister og politikere vil prate mindre og analysere mer. Fremtidens politifolk og militære bruker stadig mer komplisert teknologi. Fremtidens sykepleiere og lærere må forholde seg til tall og teknologi hver dag. Fremtidens bilmekanikere og snekkere bruker chip-optimalisering og belastningsanalyser like mye som skiftenøkkel og hammer. Det blir mer matematikk i arbeidslivet, så du trenger mer matematikk på skolen.
Du skal lære matematikk fordi du får reell studiekompetanse. Hvis du slapper av i videregående, får du et papir som sier at du har ”almen studiekompetanse”. Det er jo kjekt med et papir, men kompetanse til å studere har du ikke. Det vil du merke når du går videre til universitet eller høyskole, og må ha intensivkurs i matematikk for å skjønne hva foreleseren snakker om.
Du skal lære matematikk fordi det er kult. Det er lov å være smart, det er lov ikke å gjøre som alle andre gjør. Velg matematikk, så slipper du for resten av livet å vitse bort at du ikke klarer enkle utregninger eller ikke skjønner hva du holder på med. Dessuten får du jobb i de kule selskapene, de som trenger folk med hjerner.
Du skal lære matematikk fordi det er kreativt*. Mange tror at matematikk bare har med logisk tenkning å gjøre og at logikk ikke kan være kreativt. Sannheten er at matematikk er noe av det mest kreative som finnes – bare man bruker kunnskapen riktig. Gode kunnskaper i matematikk og matematisk tenkning i kombinasjon med annen kunnskap gjør deg mer kreativ enn mange andre.
Du skal lære matematikk fordi du skal løse de store problemene.Verden sliter i dag med store problemer som klima, forurensning, fattigdom, sykdommer og et forvitrende demokrati. For å løse disse problemene trenger vi folk som kan forstå komplekse sammenhenger og lage nye løsninger – inkludert ny teknologi – for å gjøre verden bedre. Det er kjempebra at ungdom protesterer mot manglende klimatiltak og forurensning, men i det lange løp trenger vi ikke protester og symbolhandlinger – og matematikk vil sette deg i stand til å lage løsningene, ikke bare rope etter dem.
Du trenger ikke å bli matematiker fordi du velger matematikk i videregående. Men det hjelper bra å velge matematikk hvis du vil bli smart, tenke kritisk, forstå hvordan og hvorfor ting henger sammen, og argumentere effektivt og overbevisende.
Matematikk er en skarp kniv for å skjære gjennom problemstillinger. Vil du ha en skarp kniv i din mentale verktøykasse – velg matematikk.
*) Takk til Jon Holtan, matematiker, for det siste punktet.
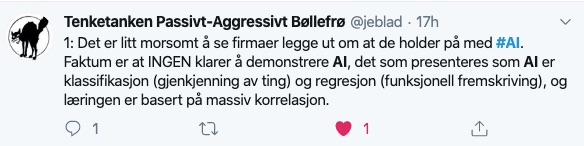
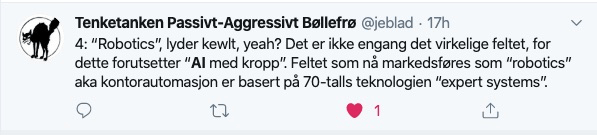
Tenketanken Passivt-Agressivt Bøllefrø (@jeblad) er verdt å følge på Twitter. I går kom han med denne stripen med, tja, poengterte utsagn om den pågående AI-hypen:
Jeg må jo bare gi ham rett på alle punkter – og jeg driver faktisk og lærer opp bedrifter i å bruke disse teknikkene. I det siste har jeg til og med hørt folk snakke om å skaffe seg «en AI», omtrent som om det er noe personalavdelingen burde involveres i.
Men så er det jo slik at når teknologene mister kontrollen over det tekniske vokabularet (noen som husker debattene om den rette betydningen av «hacker»?) så er jo det et tegn på at teknologien faktisk begynner å brukes der ute. For oss som vet, naturligvis, er jo dette bittert. Som Stephen Fry sier (i en eller annen bok jeg ikke finner referansen til nå): Det er jo ingen som er surere enn de som digget Pink Floyd før The Dark Side of the Moon, og etter å ha snakket i årevis om hvor bra de var og at alle burde høre på dem så blir de sure når bandet blir allemannseie. Konklusjonen blir at Pink Floyd har solgt seg for popularitet og det er på tide å begynne å lete etter den neste nisjegreia verden ikke setter nok pris på.
Så vi teknosnobber får finne noen nye teknologier vi kan snakke om. Det pleier ikke være vanskelig.
I en datadrevet bedrift tar ikke lenger ledere beslutninger om hva som skal gjøres – det gjør modellene. Så hva står igjen for lederen å beslutte? Ny kommentar på Digi.no. Også gjengitt i BI Business Review.
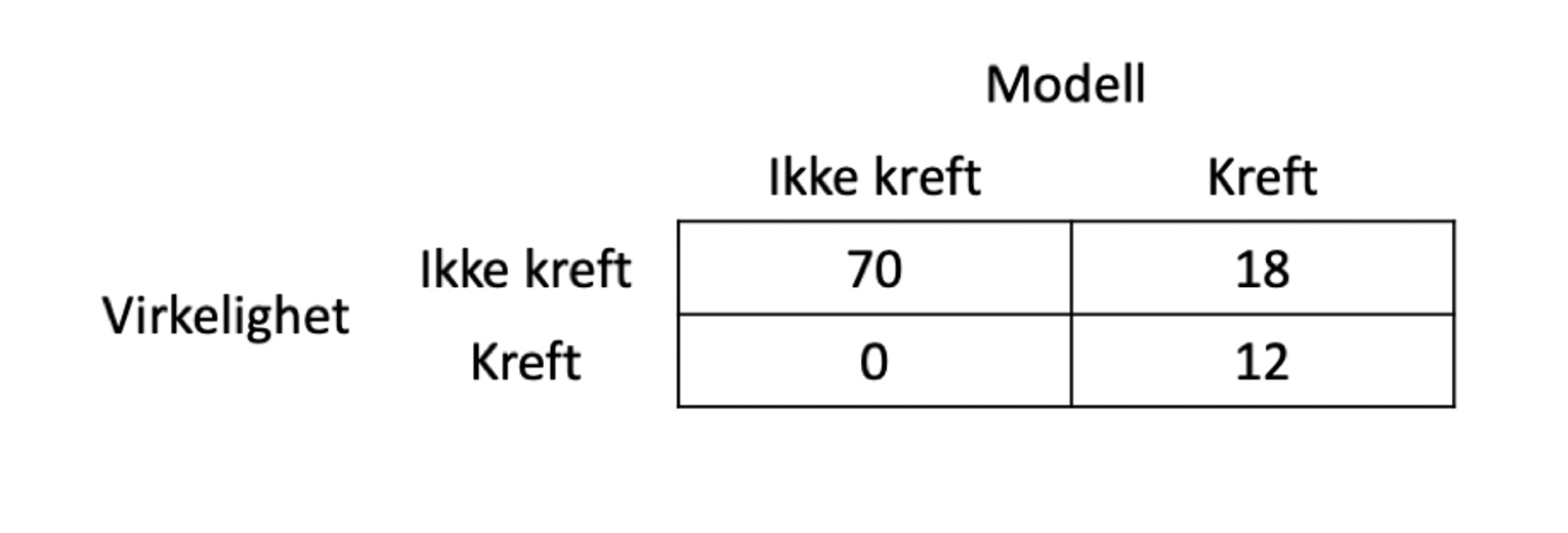
(Og jeg synes det er på tide at vi får uttrykket forvirringsmatrise inn i norsk språk.)
Som vanlig med lydfil. I denne lydfilen henviser jeg til to figurer og forsøker å beskrive dem – ta en titt på Digi eller se herunder hvis dette er uklart (og det er det…)
Data og dataanalyse blir mer og mer viktig for mange bransjer og organisasjoner. Er du interessert i dataanalyse og hva det kan gjøre med din bedrift? Velkommen til et tredagers seminar (executive short program) på BI med tittelen: Decisions from Data: Driving an Organization with Analytics. Datoene er 21-23 mai i år, og det haster derfor litt med påmelding! (Kontakt meg eller Kristin Røthe Søbakk (464 10 255, kristin.r.sobakk@bi.no) om du har spørsmål).
Kurset har vokst ut som en kortversjon av våre executive-kurs Analytics for Strategic Management, som har blitt meget populære og fort blir fulltegnet. (Sjekk denne listen for en smakebit av hva studentene på disse programmene holder på med.)
Seminaret er beregnet på ledere som er nysgjerrig på stordata og dataanalyse og ønsker seg en innføring, uten å måtte ta et fullt kurs om emnet. Vi kommer til å snakke om og vise ulike former for dataanalyse, diskutere de viktigste utfordringene organisasjoner har med å forholde seg både til data og til dataanalytikere – og naturligvis gi masse eksempler på hvordan man kan bruke dataanalyse til å styrke sin konkurransekraft. Det blir ikke mye teknologi, men vi skal ta og føle litt på noen verktøy også, bare for å vite litt om hva som er mulig og hva slags arbeid vi egentlig ber disse dataekspertene om å ta på seg.
Presentasjoner og diskusjon går på engelsk – siden, vel, de beste foreleserne vi har på dette (Chandler Johnson og Alessandra Luzzi) er fra henholdsvis USA og Italia, og dermed blir betydelig mer presise enn om de skulle snakke norsk. Selv henger jeg med så godt jeg kan…
Velkommen til tre dager med data og, etterhvert, strategi!
Sammen med Chandler Johnson og Alessandra Luzzi underviser jeg nå tredje iterasjon av kurset Analytics for Strategic Management. I løpet av kurset jobber studenter med reelle prosjekter for ordentlige selskaper, og bruker ulike former for maskinlæring (stordata, analytics, AI, hva du vil kalle det) til å løse forretningsproblemer. Her er en (for det meste anonymisert, bortsett fra offentlig eide selskaper) liste med resultatene så langt:
Et IT-serviceselskap som leverer data og analyser, ønsker å forutsi kundenes bruk av sine elektroniske produkter, for å kunne tilby bedre produkter og skreddersy dem mer til de mest aktive kundene. Resultat: Bedre salgsprediksjoner enn den eksisterende metoden (reduserte feilmodellering med 86%) – men modellen fungerer ikke langt frem i tid. Men den vil bli implementert.
En bensinstasjonskjede ønsker å beregne churn hos sine forretningskunder, for å finne måter å holde dem på (eller om nødvendig, endre noen av sine tilbud). Resultat: Fant en modell som identifiserer kunder som vil forlate dem, med en treffrate på 50% vil modellen forbedre resultatet med 25m kroner, og det er rom for å øke bruken av modellen utenfor de opprinnelige segmentene.
En frisørkjede ønsker å forutsi hvilke kunder som vil sette opp en ny avtale når de har klippet seg, for å bygge kundelojalitet. Resultat: Fant en modell som predikerte hvilke frisører som har problemer med å bygge opp en gruppe stamkunder (med omtrent 85% nøyaktighet), har klart å få en bedre forståelse av hva som driver kundelojalitet og dermed hvordan de kan hjelpe frisører med å få flere kunder.
En stor finansinstitusjon ønsker å finne ansatte som ser etter informasjon om kunder (for eksempel kjendiser), for å styrke personvern og datakonfidensialitet. Resultat: Slet med å få tak i nok og riktige data, men bygget en spesifikasjon av hva slags data som er nødvendig, hva det vil koste, og hva resultatet vil være – og fant at innenfor dette området finnes det svært få modeller, noe som er en mulighet. Og man fant noen lovende startpunkter for å bygge en slik modell. Vanskelig, men viktig område.
En stor offentlig IT-avdeling ønsker å forutsi hvilke ansatte som sannsynligvis vil forlate selskapet, for bedre å planlegge for rekruttering og kompetansebygging. Resultat: Bygget en prediksjonsmodell og en prosess som reduserer ledetiden for å ansette en ny person fra 9 til 8 måneder (en 10m innsparing) og dermed reduserer behovet for å utsette prosjekter på grunn av kapasitetsmangel, samt forbedre planleggingen av fremtidige kompetansebehov og øke sjansen for å beholde viktige ansatte.
OSL Gardermoen vil finne ut hvilke flypassasjerer som vil ønske å bruke taxfree-butikken etter at de har landet, for å øke salget (og ikke bry dem som ikke vil kjøpe taxfree). Resultat: Fant at noen variable man trodde ville øke taxfree-andelen ikke gjorde det, lærte mye om hva som gjør forskjell – og at modellen, hvis man klarer å bygge den, vil være mye verdt (en økning i taxfree-bruk på under en prosent vil øke Avinors inntekter med mer enn 100m). Samt at eksperimentering, ikke store prosjekter, er veien å gå videre.
En mindre bank ønsker å finne ut hvilke av sine yngre kunder som snart trenger et boliglån, for å øke sin markedsandel. Resultat: Bygget en modell som øker sannsynligheten for å identifisere førstegangs boliglånskunder, til en merverdi av 6,9 millioner kroner – samt at bruken av denne modellen introduserer datadrevne beslutninger for organisasjonen.
Et internasjonalt TV-selskap vil finne ut hvilke kunder som sannsynligvis vil si opp abonnementet sitt innen en bestemt tidsramme, for å bedre skreddersy sitt tilbud og markedsføring. Resultat: Bygget en modell med en kortsiktig beregnet merverdi på 500000 kroner per år, som treffer seks ganger bedre enn tilfeldige utvalg. I løpet av arbeidet har man funnet en rekke aktiviteter som kan øke kundelojaliteten uten store kostnader – og funnet inspirasjon for mer bruk av maskinlæring.
En leverandør av administrerte datasentre ønsker å forutsi sine kunders energibehov, for å kunne skrive og oppfylle konktrakter om sertifisert grønne datasentertjenester. Resultat: Bygget en modell basert på historiske sensordata for eksisterende kunder, for å forutsi forbruk for en ny kunde, og deretter en modell som inkluderer den nye kunden for å overvåke resultatet og forbedre modellen for alle kundene. En korrekt modell (som implementert) vil forbedre månedlig inntekt med 47% for en ny klient og redusere sjansen for kontraktsterminering.
Ruter (paraplyfirmaet for offentlig transport for Oslo-området) ønsker å bygge en modell for å bedre forutsi trengsel på busser, for å, vel, unngå trengsel. Resultat: Bygget en modell og et forslag til en tjeneste for å kunne fortelle Ruters kunder om det (sannsynligvis) er ledige seter på bussen eller ikke, går nå til testing.
Barnevernet ønsker å bygge en modell for å bedre forutsi hvilke familier som mest sannsynlig vil bli godkjent som fosterforeldre, for å kunne prioritere saksbehandling og redusere ventelister. Resultat: Tross mye manglende data klarte man å finne gode indikatorer på godkjente fosterforeldre og har lagt en plan for videreutvikling av modellen etterhvert som man får bedre data. Området er lovende, siden behovet for fosterforeldre er stort og selv en liten forbedring vil hjelpe.
Et strømproduksjonsselskap vil bygge en modell for å bedre forutsi strømforbruket i deres marked for å kunne planlegge produksjonsprosessen bedre. Resultat: Testet mange modeller og har funnet at å forutsi spot-priser er vanskelig, men har klart å finne indikatorer på økt volatilitet, noe som gjør at man kan produsere noe mer presist. Kortsiktig effekt av en liten modell er 100-200 tusen euro per år for hver produksjonsenhet, et tall som forventes å øke siden volatiliteten i markedet vil øke fremover.
Alt i alt er vi svært fornøyd – vi har klart å øke verdien, samlet sett, for disse selskapene adskillig mer enn kurset koster (I hvert fall 10-gangen, konservativt anslått). Flere av deltakerne har fått nye stillinger og flere av dem har bestemt seg for at data science er en retning de skal fortsette å utvikle seg i, og ønsket seg flere slike «tekniske» kurs. Og gitt at vi også har produsert en masse kunnskap og generelt økt deltakernes evne til å bygge bro mellom analytikere og forretningsfolk, tror jeg vi kan erklære dette prosjektet for en suksess…
For noen uker siden kjøpte jeg en motorsag på Biltema (elektrisk, kr. 699, fungerer utmerket), etter å ha søkt litt på nettet. Siden har Facebook og mange andre sider vært nedluset med annonser for motorsager i alle farger og fasonger. I forigårs diskuterte fruen og jeg om vi skulle kjøpe oss et veksthus, og Googlet litt for å finne noen alternativer og hva de kostet. Siden har det blitt mye veksthus….
Nå er ikke jeg den første som har denne erfaringen, men hvorfor velger annonsører i mange situasjoner å vise deg annonser, av og til i ukevis, for produkter du allerede har kjøpt?
Årsaken er ganske enkel: De vet ikke så mye om deg. Det eneste annonsørene vet om meg, er at jeg har søkt på motorsag eller veksthus eller hotell i Venezia eller noe annet, nokså spesifikt. I fravær av mer spesifikk informasjon (inkludert om jeg har kjøpt dette produktet eller ikke) er den beste strategien å vise meg det jeg har sett på før. Faktisk er det slik at selv om jeg har kjøpt produktet, er det beste strategien å vise meg annonser for det jeg nettopp har kjøpt, siden man likevel ikke vet (i hvert fall ikke presist nok, siden man ikke ser helheten) hvilke andre produkter man er ute etter.
(Det er også slik at Facebook faktisk ikke har så mye informasjon om deg som man skulle tro. Informasjonen om deg og dine venner har Facebook, men informasjonen om hva du har sett på og hva du har kjøpt finnes i mange firma med navn som DoubleClick (nå eid av Google). Når du går inn på Facebook, startes en komplisert auksjonsprosess der annonsører går inn og byr på muligheten til å vise deg en annonse.
Disse auksjonene er over på millisekunder (fra du har klikket på noe i Facebook til siden kommer opp i webleseren) og dermed må man bruke ganske enkle kriterier for hva som skal vises, samtidig som kostnaden ved å ta feil er svært liten. I en slik situasjon blir det mange annonser for ting folk har kjøpt før.
Men det er bedre enn å skyte i blinde.
(Og vil du lese mer om dette og andre algoritmer som brukes til alle de beslutningene vi lurer på på Internett og andre steder, anbefaler jeg sterkt Algorithms to Live By: The Computer Science of Human Decisions av Brian Christian og Tom Griffiths. Morsom og lærerik.)
Liten artikkel i DN i dag, bygget på en artikkel i BI Business Review (kommer etterhvert), som igjen bygger på dette kapittelet i BIs jubileumsbok. (Og stor takk til Audun Farbrot for en formidabel innsats i forskningskommunikasjonens tjeneste i denne sammenheng.)
Og artikkelen? Vel, jeg vedlegger en PDF, lenken (betalingsmur) finner du nedenfor, og som så meget annet handler denne artikkelen om at man ikke kan innføre nye teknologier (i dette tilfelle dataanalyse) uten samtidig å endre organisasjonen (i dette tilfelle ledelsesrollen.) Dataanalyse og den datadrevne organisasjonen må forholde seg til et faktabasert verdensbilde, noe som krever evne til å sanse, forstå, handle, lære og forklare – kontinuerlig, og i stor skala.
Syntes jeg dro kjensel på fotografiet – og jammen var det ikke Odd Erik Gundersen (som jeg sitter i styret i SmartHelp sammen med) som ble intervjuet og har skrevet en glimrende (og tilgjengelig) kronikk i Morgenbladet om diskusjonen om forskningskvalitet. Det er et stendig problem innen forskning (også innen informatikk) at forskningsresultater ikke lar seg replikere.
Innenfor kunstig intelligens (eller, vel, maskinlæring som jeg regner med at det er snakk om her) er dette ekstra viktig fordi utviklingen av maskinlæringsalgoritmer i motsetning til vanlig vitenskapelig metode er teoriløs – man har masse data, kjører en søkealgoritme over mange modeller og modellvarianter, og så ender man opp med et eller annet resultat, gjerne uttrykket ved en confusion matrix eller en validation curve (også kalt learning curve).
Ofte finner man at når folk snakker om at de har en modell som er «94% nøyaktig» så snakker de om nøyaktigheten på treningsdataene (der modellen er utviklet) og ikke på testdataene (som er de dataene man holder til side for å se om modellen, utviklet på treningsdataene, er nøyaktig.) Dermed får man modeller som har svært høy nøyaktighet (ikke noe problem å komme til 100% hvis man bare er villig til å ta med nok variable) men som brukbare til noe som helst.
Og det er et problem ikke bare i maskinlæring, men i all forskning. Det er bare det at i maskinlæring finnes dataene og programmene lett tilgjengelige, problemet er synlig, og det er sjelden noen grunn til å skjule det.
Bortsett fra at noen trenger å publisere noe, heller enn å bygge en god modell.
Så denne reportasjen i Aftenposten i dag, om hvordan Norsk Tipping kontakter folk som taper mye penger og gjør dem oppmerksom på at de kanskje har et spilleavhengighetsproblem. Og årsaken til at jeg blogger om det er at a) en av studentene mine fra kurset Analytics for Strategic Management, Tanja Sveen (se foto, fra Aftenposten) er omtalt (når jeg tenker meg om, har studentene eksamen i dag), og b) et av prosjektene i kurset (som jeg faktisk kan snakke om, de fleste er konfidensielle) er Norsk Tippings analyseprosjekt for å finne ut av hvem de skal ringe til.
Norsk Tipping har begrenset kapasitet for telefonsamtaler, så de må bestemme seg for hvem de skal ringe til, ikke bare ut fra hvem som spiller mest, men også ut fra faktorer som hvem som vil ha mest nytte av en slik samtale.
Prosessen Norsk Tipping må gå gjennom, er svært lik mange andre maskinlæringsprosjekter: Man har en historikk (folk som spiller (mange), folk man ringer til (færre), og hva som skjer etter at man har ringt (f.eks. om de slutter med eller reduserer spillevirksomheten eller ei.) Man identifiserer (basert på historikk og andre kriterier) hvem som står i fare for å utvikle spilleavhengighet, og lar maskinen se på historikken og lage en modell for hvem i utvalget man skal ringe til, basert på en rangering av sannsynligheten for positiv effekt.
Det er mange problemer med slike modeller, både før man spesifiserer den – hva er kriteriene for å bli valgt ut, for eksempel, siden det er vanskelig å avgjøre om folk er spilleavhengige eller bare har god råd, og hvordan man skal måle hva som er ønsket effekt eller ikke – og mer tekniske problemer – for eksempel ubalanserte datasett (man har mange observasjoner av spillere, men relativt få av folk med utviklet spilleavhenighet, for eksempel. Hvis du skal lete etter terrorister blant flypassasjerer, er ikke problemet at du har for få passasjerer – du har for få eksempler på terrorister…).
Alt dette lærer man om på kurset. Det som er interessant med Norsk Tipping, er at de tar en forskningsbasert tilnærming til dette: De tar utgangspunkt i det de vet, setter opp en modell for å vurdere om ting virker eller ikke, og hvordan de kan justere det de gjør, og så kommer de til å gjøre dette en stund og lære av erfaringene. Prosessen er i utgangspunktet teori-fri, hvilket vil si at man ikke (i hvert fall i prinsippet) skal ha forhåndsteorier om hva som virker eller ikke.
Og akkurat den utfordringen – å la dataene, heller enn intuisjonen, avgjøre hva man skal gjøre – er en av de vanskelige overgangene man må gjennom for å få en data-dreven organisasjon til å fungere.
Det skal bli spennende å se om Norsk Tipping får det til – så langt ser det lovende ut.























 For noen uker siden kjøpte jeg en
For noen uker siden kjøpte jeg en 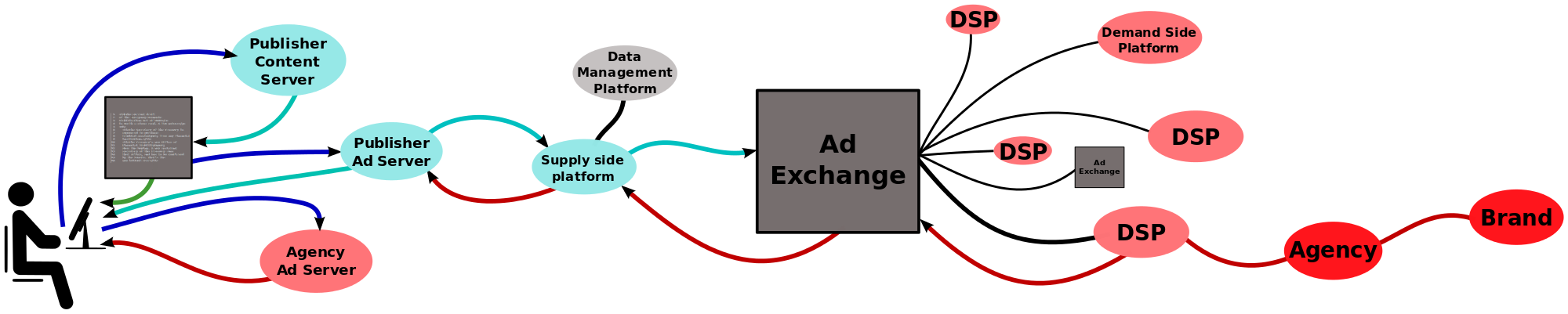
 Liten
Liten 
 Så
Så 
{kind=link}