Siden tidenes morgen har store bedrifter slitt med antikverte kjernesystemer, vanskelige å endre og vanskelige å få data ut av. Nå har noen av dem begynt å få orden på det – og hva skjer da?
ChatGPTs versjon av en COBOL-programmerer – de har tydeligvis bare tre fingre per hånd.
(Denne bloggposten ble først publisert på Comunita.no – et ledernettverk for folk med interesse for, nettopp, strategisk forretningsutvikling. Ta kontakt om du ønsker å vite mer om Comunita!)
Museumsgjenstanden i kjelleren
De grunnleggende datasystemene man bruker i store bedrifter – særlig banker og forsikringsselskaper – ble først laget på sekstitallet. De gjorde helt grunnleggende ting, som å holde orden på hva kundene hadde betalt og fått, og var programmert enten i maskinspråk, Assembler, eller (vanligvis) COBOL. COBOL – designet av ingen ringere enn kontreadmiral Grace Hopper – har vist seg å være forbausende standhaftig: Det er lett å programmere i, men når programmene blir store, er det forbausende vanskelig å endre dem. Etterhvert som ny teknologi har kommet, har de fleste bedrifter utviklet en arkitektur der de har noen svært gamle kjernesystemer – ofte i COBOL – og en mengde andre systemer rundt kjernen – systemer som kommuniserer med kjernesystemet men ikke endrer det.
Dermed ender man opp med et monster i kjelleren – et gammelt system ingen tør røre, delvis fordi det er mangel på folk som kan, dels fordi enhver endring har forgreninger inn i hundrevis, kanskje tusenvis av andre rutiner i egen og andres organisasjon. Siden ingen tør å røre det, bruker man systemene rundt – for dataanalyse, for eksempel, dumper man det som har skjedd i kjernesystemet ut i ulike lagringsløsninger, og gjør analysene derfra.
Fordelen med å trekke data ut fra systemet og gjøre det tilgjengelig er at ulike deler av organisasjonen trenger ulike typer analyser – og har man dataene separat, man man gi dem til folk og la dem gjøre hva de vil. Ulempen er at – med mindre man har en selvdisiplin av en annen verden – de ulike delene av organisasjonen snart skaper sine egne begreper og sine egne bilder av hvordan verden ser ut. Det betyr at uttrykk som «lagerbeholdning» eller «lønnsomhet» har ulike betydninger for ulike deler av organisasjonen, som jo kan gjøre det vanskelig å bli enige om ting. «Single source of truth» er et viktig prinsipp fra informatikk – masterdata skal lagres kun et sted og det skal aldri være tvil om hva som er riktige data. Dette har etterhvert blitt et begrep innen ledelse også, og en viktig motivasjon for å la kjernesystemer og dataanalyse nærme seg hverandre.
Heisenberg i regnskapet
En annen effekt – og viktig motivasjon – for å hente data fra kjernesystemene er oppdatering. Det er en klisje at all regnskapsanalyse handler om å se på fortiden for å predikere fremtiden – ofte sammenlignet med å kjøre bil ved å se i bakspeilet. Jo fersker data, jo bedre styring.
Eller kanskje ikke?
De som har sett Breaking Bad, husker sikkert at hovedpersonen Walter White brukte pseudonymet Heisenberg. Det er ikke tilfeldig – Werner Heisenberg er mannen bak usikkerhetsprinsippet, som sier at (innen kvantemekanikk) er det ikke mulig å presist måle både posisjon og hastighet for en partikkel samtidig. Jo mer presist du måler hvor en partikkel er, jo mindre vet du om hvor fort den beveger seg, og omvendt.
Innen forretningslivet må vi hele tiden ta beslutninger som krever målinger av et eller annet slag – for en bank, for eksempel, må man vurdere kredittverdigheten til en bedrift. Den samme banken vil gjerne også kunne finne ut av hvilke privatkunder som kommer til å flytte lånene sine eller slutte å betale dem – eller mer presist kunne vurdere likviditetsbehov på kort sikt, kanskje fra minutt til minutt.
Når data blir øyeblikkelig tilgjengelig, vil vel dette bli lettere?
Lager er ikke lager
Vel, ting er ikke så enkelt. La oss ta et enkelt begrep, som uttrykket «lager» – er produktet på lager?
Skal du kjøpe noe på IKEA, for eksempel, kan du jo gå på deres webside og se om det ønskede produktet er i butikken – bare for å finne at det ikke er der likevel når du kommer dit. Sjansen for at lagerbeholdningen er feil, er mindre nå enn før, fordi man har fått raskere oppdateringer. For noen år siden ble lagerbeholdningen oppdatert daglig, i en batchprosess. Så koblet man det til POS-systemet i kassen, og dermed ble tallet oppdatert når noen gikk gjennom kassen og betalte for det.
Nå er IKEAs forretningsmodell den at du henter det du skal ha, for så å bruke masse tid på å vandre rundt i en labyrint eller stå i kø mens du fristes med lysestaker, varmelys og marsipan. Den flatpakken du har på handlevognen, er fortsatt – i følge IKEA – på lager, i den forstand at de ikke har solgt den ennå. Men den er ikke på lager for neste kunde, som kommer til en tom hylle – medmindre IKEA monterer strekkodelesere eller vekter på lagerhyllene sine.
Begrepet «lagerbeholdning» er altså ikke bare tidsavhengig, men også forskjellig for forskjellige brukere, og årsaken er ikke slapp datadisiplin, men genuine forskjeller i informasjonsbehov. Dermed blir det til at man må endre beregningsmetode ikke bare ut fra hvilket tidspunkt man ønsker data på (historisk, i sanntid, eller i fremtiden) men også ut fra hvem som spør (kunde, selger, markedsansvarlig, produsent, eller den som er ansvarlig for lagerlokalene.)
Dermed blir noe så enkelt som «lager» et begrep som involverer ikke bare tall, men også relasjoner mellom ulike deler av verdikjeden, der systemene er simuleringer av virkeligheten.
Med andre ord: Jo mer presist man ønsker å måle et begrep, jo mer presist må det defineres.
ChatGPTs svar på «make an image that illustrates how AI can make managers more productive». Hvorfor en digital leder trenger skrivebordsskuffer er noe jeg ikke helt forstår, men et eller annet sted skal man jo ha matpakken…
(Denne bloggposten ble først publisert på bloggen til Comunita, et ledernettverk jeg driver sammen med Haakon Gellein. I neste møte skal vi ta opp dette temaet – og derfor har jeg skrevet dette blogginnlegget som en forberedelse.Vi tar opp nye medlemmer etter vurdering – ta kontakt om du ønsker mer informasjon.)
Her forleden snakket jeg med en leder i et stort, internasjonalt selskap. Han var ansvarlig for en intern leverandør av IT- og administrative tjenester, og hadde nettopp fått ordre fra toppledelsen om å doble tjenesteproduksjonen uten å øke antall ansatte. Det er jo ikke så enkelt, men toppledelsen mente det burde gå greit for «nå har vi AI».
Og det fikk meg til å lure på hvordan vi egentlig skal få noe produktivitet ut av AI – særlig generativ AI, også kalt store språkmodeller – i et tradisjonelt selskap?
Produktivitet og informasjonsteknologi
Produktivitet er definert som hvor mye resultat vi får av en innsats – men som regel betyr det hvor mange ansatte vi trenger for å få gjort noe. Når det gjelder fysisk produksjon, er det ikke så vanskelig å måle produktivitet: Flere produkter produsert, gitt samme innsats og kvalitet, er økt produktivitet.
Og det er jo greit nok – få inn en maskin som gjør jobben raskere, og hvis økningen i hastighet er verdt prisen på maskinen, vel, der har du konklusjonen.
Problemet oppstår når effekten av produktiviteten oppstår et annet sted, eller ikke som et direkte resultat av maskinen.
I 1998 ble jeg involvert i en diskusjon om produktivitet og datamaskiner. En forsker hadde skrevet et innlegg i Aftenposten om at PCer ikke økte produktiviteten noe særlig. Han viste til forskning der man hadde tatt tiden på hvor fort det gikk å skrive et dokument på en skrivemaskin og på et PC-tastatur, og konkluderte med at det gikk bare ca. 10% raskere å skrive på PCen, så det var liten vits i å investere i dem. Jeg skrev et motinnlegg der jeg påpekte at når jeg skrev mitt innlegg, sendte jeg det til Aftenposten som e-post, og at de kunne ta det rett inn i avisen uten å måtte skrive det om igjen. Det var en voldsom produktivitetsgevinst for Aftenposten – i hvert fall hvis de kunne få gjort noe med typografenes fagforening, som insisterte på å skrive alt om igjen.
Eksemplet er banalt, men viser to viktige ting: For det første oppstår produktivitet av informasjonsteknologi gjerne andre steder enn der teknologien er synlig. Da blir det vanskelig å se og måle effekten. For det andre, og mye viktigere: For virkelig å få effekt av ny teknologi, må man reorganisere det man driver med rundt teknologien. Det er enda vanskeligere å måle, og er en av årsakene til at nye organisasjoner, som ikke har en gammel måte å gjøre ting på, ofte drar nytte av teknologien lenge før de gamle.
Produktivitetsparadokset
I 1987 skrev den kjente økonomen Robert Solow at «Vi finner datamaskinene overalt, bortsett fra i produktivitetsstatistikken.» Han pekte på store investeringer i datamaskiner på 1970- og 1980-tallet, uten at de store kostnadsbesparelsene hadde kommet. I debatten som fulgte, ble mange årsaker foreslått, fra forsinkelser forårsaket av læring og omorganisering rundt den nye teknologien til kulturelle forklaringer («ledere ønsker å administrere mange ansatte» eller vanskeligheter med å måle kostnader og fordeler.
I løpet av 90-tallet skjøt imidlertid produktiviteten fart – banker, for eksempel, fant ut hvordan de kunne redusere antall ansatte ved å flytte kundene over fra filialer til digitale kanaler. Internett og etter hvert mobiltelefoni gjorde at mange «call centers» kunne legges ned. Innen offentlig forvaltning fikk vi digitale skattemeldinger og hjemmesider med informasjon og digitale søknadsskjema. Effektene kommer, men vi glemmer at vi har dem: I høydigitale samfunn, som Norge, lurer du noen ganger på hvor produktivitetseffekten av IT ble av, helt til du innser at du svært sjelden står i kø for noen form for informasjonsbasert transaksjon, som å kjøpe en billett eller levere et skjema.
Men: Økt produktivitet betyr ikke nødvendigvis økt lønnsomhet. En rekke studier ledet av Erik Brynjolfsson fra MIT dokumenterte at økt produktivitet nok kunne føre til endringer innen en bransje (et firma som var tidlig ute kunne utkonkurrere andre firma), men lønnsomheten konkurreres bort og havner hos forbrukeren (Brynjolfsson og Hitt 2000). Som en bekjent av meg pleide å si: I næringslivet må vi hvert år bli mer effektive, jobbe hardere og smartere, og belønningen er at neste år får vi lov til å gjøre det en gang til.
Med mindre vi endrer hvordan vi er organisert.
Dette at eksisterende selskaper sliter med nye organisasjonsformer, gjør at i mange tilfeller er det nye selskaper, organisert med teknologien som basis, som definerer nye normaler. Automattic, selskapet bak WordPress-plattformen som rundt 43 % av alle nettsteder er programmert i, har (ifølge deres egen nettside) kun 1 994 ansatte i 94 land. I Norge har vi sett det der f.eks. Skandiabanken kom inn og flerdoblet antall kunder per ansatt ved kun å være en Internettbank. Skandiabanken er nå overtatt av Norges største bank, DNB – men det er en bank som nå er kun en tredjedel av størrelsen av hva den var da Skandiabanken ble lansert, og som har krympet ved å kopiere mye av det Skandiabanken gjorde.
AI og produktivitet: Individuelle, organisatoriske og samfunnsmessige effekter
For enkeltpersoner kan GenAI være utrolig produktivt. Nylig satt jeg med en programmerer som ønsket å teste om et nettsted kunne bygge inn et Google-dokument. Det viste seg at det ikke gik, men det kunne bygge inn HTTP (hypertekst). Så han tok Google Doc-lenken, hoppet over til ChatGPT, skrev «legg denne i en iFrame». ChatGPT produserte pliktoppfyllende den nødvendige koden i løpet av noen sekunder. Han kopierte koden, limte den inn – og det fungerte.
Dette er utvilsomt en produktivitetsøkning for denne programmereren, som ellers ville ha måttet huske og skrive koden for en iFrame-omslag (eller i det minste vite hvor den skulle finne den.) Dette eksemplet viser også hva ChatGPT er flott for: Reprodusere, med rimelig kontekstualisering, varianter av det som har blitt produsert før. Selv har jeg brukt det til å generere det første utkastet til kontrakter, emnebeskrivelser og, ja, elementer av essays (ikke dette). ChatGPT og dets konkurrenter kan hjelpe deg med å generere tekst, bilder, presentasjoner og annet materiale, så lenge originalitet ikke er nødvendig eller verdsatt – og kan gi nokså store produktivitetsgevinster på individnivå.
På organisasjonsnivå er det litt annerledes. Fra store bedrifter i USA har man sett at opplæring og kvalitet på kundesentre er forbedret ved bruk av generativ AI, men resultatene er ikke voldsomt høye foreløpig (Brynjolfsson et al 2023). En leder jeg snakket med fortalte meg at hovedeffekten av ChatGPT han hadde sett så langt var at e-poster hadde blitt mye høfligere. Men veltalenhet er ikke informasjonsdybde, og jeg tviler på om raskere generering av tekst og bilder vil føre til produktivitetsgevinster i organisasjonen, siden de som skal motta informasjonen også må øke sin produktivitet.
Mine studenter kan nå produsere svada i et imponerende tempo og med en kompleksitet verdig en fransk postmodernist. Men min evne (og vilje) til å lese og forstå det som kommer er ikke økt. På den annen side kan jo jeg bruke ChatGPT til å lese og karaktersette – et eksempel på at studentene later som de skriver og jeg later som jeg leser.
Om dette er en situasjon vi egentlig vil ha, er jo noe vi bør diskutere. Er dette et tegn på tidens forfall, eller begynnelsen på en ny kommunikasjonsform, der min AI snakker til din AI og avtaler ting på våre vegne? Kanskje jeg endelig kan få tilbake den sekretæren jeg hadde på nittitallet…
En parallell til søketeknologi?
For noen år siden deltok jeg i et forskningsprosjekt som studerte bruken og effektene av søketeknologi. En av konklusjonene (Andersen 2012) var at søkemotorer fungerte utmerket i generelle Internett-søk (dvs. Google, Baidu og Bing), ganske bra på kunderettede nettsider (dvs. aviser, Amazon, teknologiselskaper som Dell), men nokså dårlig for interne søk. Mens teknologien var den samme, var både hvordan den ble brukt (dvs. hva folk lette etter) og hvordan resultatene ble prioritert forskjellig. I en generell søkemotor søker folk over millioner av nettsider. Vanligvis vil man ha det samme som andre – så Google viser de mest populære resultatene. For et kommersielt nettsted søker folk etter spesifikke ting (som et fysisk produkt, et svar på vanlige spørsmål eller en nyhetsartikkel), og generelt vil de enten ha det mest populære valget eller det selskapet ønsker å vise dem – f.eks. varer som er på lager og lønnsomme.
For bedriftssøk, der du søker på tvers av enten all informasjonen din bedrift har, eller spesifikke samlinger av informasjon (for eksempel en lovdatabase eller et sett med interne instruksjoner), har du problemer: For det første har du ikke nok data til å virkelig få maskinlæringsmodellene til høy presisjon, fordi selv store selskaper vil ha begrensede samlinger av informasjon sammenlignet med hele Internett. For det andre er målfunksjonen til søket – det vil si hva du leter etter – normalt ikke den mest populære varen, men noe mye mer spesifikt. I en bedriftssetting er det mye mer sannsynlig at du søker etter et spesifikt dokument, ofte bare relevant for deg eller en liten arbeidsgruppe, og som sådan vil du måtte stole mer på kategorisering (Andersen 2006), i form av kuraterte data og hierarkiske, menneskelig navigerbare datastrukturer.
For meg er det i hvert fall fullt mulig at produktivitetsgevinstene fra generativ AI vil komme saktere i eksisterende selskaper av omtrent samme årsak som søketeknologi ofte svikter der: Datasettet er ikke stort nok, og kravene ikke enhetlige nok.
AI-ing, AI-isering, AI-transformasjon
Unruh og Kiron (2017) deler digitalt drevet endring inn i digitisering (gjør det analoge digitalt), digitalisering (endringsprosesser for å utnytte den digitale teknologien) og digital transformasjon som den komplette omorganiseringen rundt den nye teknologien. David (1990) observerte at det tok omtrent tretti år å realisere de fulle produktivitetsgevinstene fra den andre industrielle revolusjon (dvs. å erstatte damp- eller vannkraft overført gjennom belter og trinser med elektrisk kraft distribuert gjennom kabler) fordi fabrikkeierne fortsatte å stille opp maskinene der beltene og trinsene hadde vært.
Nåværende innsats for å bruke AI for å øke produktiviteten er fremdeles i den den første fasen. Teknologien er rettet mot prosesser som er repeterbare, kjedelige og arbeidskrevende, for eksempel automatisk klassifisering og kontroll av reiseutgifter, talegjenkjenning for å rute kundeanrop til riktig agent, chat-bots for å håndtere enkle kundeforespørsler, og tale- og bildegjenkjenning for å fremskynde opplæring av ansatte. Produktivitetsgevinster har en tendens til å være beskjedne i spesifikke tilfeller, men kan være ganske dramatiske samlet sett – og de kommer først og fremst for de enkle oppgavene.
Så ja, det kommer til å bli produktivitet ut av AI. ChatGPT også. Men det kommer til å ta tid, og det kommer til å skje andre steder enn der man har trodd.
Og vi må reorganisere for å få det til.
Referanser:
Andersen, E. (2006). «The Waning Importance of Categorization.» ACM Ubiquity7(19).
Andersen, E. (2012). «Making Enterprise Search Work: From Simple Search Box to Big Data Navigation». Cambridge, MA, MIT CISR.
Brynjolfsson, E. and L. Hitt (2000). «Beyond Computation: Information Technology, Organizational Transformation and Business Performance.» Journal of Economic Perspectives14(4): 23-49.
Brynjolfsson, E., D. Rock and C. Syverson (2017). Artificial Intelligence and the Modern Productivity Paradox: A Clash of Expectations and Statistics. Cambridge, MA, National Bureau of Economic Research.
Brynjolfsson, E., D Li and L.R.Raymond (2023), «Generative AI at Work«, National Bureau of Economic Research working paper 31161.
David, P. A. (1990). «The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox.» American Economic Review80(2): 355-361.
Hitt, L. and E. Brynjolfsson (1996). «Productivity, Business Profitability, and Consumer Surplus: Three Different Measures of Information Technology Value.» MIS Quarterly20(2): 121-142.
Data er det nye gullet, sies det. Men da må vi gjøre det dataene sier.
(Denne bloggposten ble først publisert på bloggen til Comunita, et ledernettverk jeg har startet sammen med Haakon Gellein. Der diskuterer vi medlemmenes utfordringer – i dette tilfelle en stor organisasjon som ønsker å bli mer datadrevet – og jeg skriver blogginnlegg som forberedelse til disse møtene. Vi tar opp nye medlemmer etter vurdering – ta kontakt om du ønsker mer informasjon.)
Mange bedrifter og organisasjoner har enorme mengder data, men utnytter dem ikke. Det er det mange årsaker til – som manglende analysekunnskaper, manglende tradisjoner, eller manglende konkurranse. Men etterhvert som vi får flere og flere eksempler på bedrifter og organisasjoner som gjør suksess ved å skaffe seg data og utnytte dem, øker kravet om å være data-drevet. Hva betyr det egentlig – og hvordan får man det til?
La oss ta for oss en bedrift i en bransje som kanskje ikke ligner så mye på noe i Norge (bortsett fra Norsk Tipping, og de er jo data-drevet) men der utviklingen viser hva man kan få til ved å ta tak i de dataene man har – og gjøre som dataene viser.
Et kasinoeksempel
Da jeg var doktorgradsstudent en gang for hundre år siden (vel, 1991) møtte jeg i noen seminarer en nyansatt professor ved navn Gary Loveman. Gary var statistiker og økonom og spesielt interessert i sammenhengen mellom lønnsomhet og kundelojalitet. Han var også nokså ulik mange av de andre professorene både av utseende og humør. Jeg fikk litt inntrykk av at han ikke tok livet – og i hvert fall ikke seg selv – så veldig høytidelig.
Gary drev litt som konsulent på si. En av kundene hans var Harrah’s, et relativt lite kasino i Las Vegas. Kasinoet gikk ikke bra – som Gary sa det (se hans suverene foredrag på Berkeley for noen år siden): «Vi hadde et kasino som kostet 315 millioner dollar (det er lite i Las Vegas) å bygge. Ved siden av oss kom det et nytt kasino til 1,6 milliarder, og tvers over gaten ville det komme et 9,2 milliarder. Det er ingen som tar inngangspenger i Las Vegas. Hvordan skulle vi få kundene til å komme til oss?»
Firmaet hadde store problemer – så store at de gikk til en akademiker for å finne ut hva de skulle gjøre. Gary hadde skrevet artikkelen Put the Service-Profit Chain to Work sammen med endel kolleger og fant ut at i dette kasinoet kunne han se modellen fungerte i praksis. Men før han kunne finne ut hva han skulle gjøre, måtte han finne ut hvem kundene var og hva de likte.
Markedsføring i Las Vegas den gangen handlet mye om å få tak i de store spillerne, de som flys inn med helikopter, får gratis suiter og middager og legger igjen millioner ved roulette-bordene. Etter endel analyse fant Gary ut at de virkelig attraktive kundene ikke var storspillerne (som alle de andre kasinoene gikk etter), men «vanlige folk» – håndverkere, lærere, leger, annen middelklasse – som spilte mindre, men som det var mange flere av. Han introduserte det første kundelojalitetsprogrammet i bransjen, basert i mindre grad på hvor mye folk spilte og i større grad hvor ofte de besøkte kasinoet. Kundene satte pris på å bli skikkelig behandlet uten å være millionærer, og Harrah’s vokste fra å være et lite kasino i skyggen av Ceasar’s Palace til å bli verdens største kasinoselskap (som faktisk i dag heter Ceasar’s Entertainment, et tilfelle av David som bokstavlig talt kjøpte Goliat).
Datadrevne kjennetegn
En av utsagnene som Gary har blitt kjent for, at det er bare tre ting du kan få sparken for i hans organisasjon: Tyveri, seksuell trakassering, og å gjøre en endring uten å ha en kontrollgruppe.
De to første er kanskje ikke så vanskelige å forstå, men den siste krever litt forklaring. Nå man gjør et vitenskapelig eksperiment – for eksempel utprøving av en ny medisin – gir man den ikke til alle pasientene, men til en tilfeldig utvalgt gruppe. Kontrollgruppen er de som ikke får den nye medisinen, men i stedet behandles som tidligere. Etterpå måler man om det er forskjell på de to gruppene – og om forskjellen er tydelig og stor nok, går man over til den nye måten å gjøre ting på.
Innenfor medisinsk forskning gjøres dette dobbeltblindt – verken pasienten eller legen vet hvem som får ny medisin og hvem som ikke gjør det. Det kan det være vanskelig å få til i mange sammenhenger – det er derfor det er så vanskelig å forske på ernæring, siden vi vet hva vi spiser – men det er mange bedrifter som driver med dette i stor stil: Finn.no, for eksempel, slik jeg skrev om i en artikkel i Magma for noen år siden.
Dette at man insisterer på at alt som skal endres, skal testes først, er et av de fremste kjennetegnene på at en bedrift er data-drevet: Man lytter til dataene, og gjør som dataene sier.
Hvorfor er dette så vanskelig?
Problemet med data er at de ikke alltid forteller deg den historien du vil de skal fortelle. Når det skjer, må man velge om man skal tro på dataene eller på sin egen magefølelse – og pussig nok er dette vanskeligere jo bedre man er i jobben. Chris Argyris, en annen Harvard-professor, skrev en berømt artikkel kalt Teaching Smart People How to Learn, om nettopp dette at kompetente mennesker i ledende stillinger med lang erfaring er de som har størst vansker med å lytte til data – rett og slett fordi de har kommet til sine stillinger ved å ha hatt rett. Hittil, i alle fall.
Av og til kan hele bransjer la være å lytte til dataene – i forsikringsbransjen, for eksempel, brukes masse dataanalyse for å finne ut av hvorfor kunder forlater et forsikringsselskap til fordel for et annet. Svaret er det samme hver gang: Den fremste grunnen til at folk forlater et forsikringsselskap er at de har hatt en forsikringshendelse og ikke er fornøyd med hvor mye penger de har fått utbetalt. Det er det ingen i bransjen som ønsker å gjøre noe med. Innenfor utdanning er vi ikke noe bedre: Den fremste prediktoren for suksess for bachelorstudenter, for eksempel, er matematikkunnskaper når man begynner på studiet. Men det er det vanskelig å gjøre noe med, så da satser vi på motivasjon og inspirasjon i stedet…
Fokus på data og kontinuerlig innovasjon gir resultater – bare spør Gary. Eller Finn.no. Eller Google. Eller VG.no, som ble Norges største online avis ved kontinuerlig oppdatering av hva som står på førstesiden basert på hvordan leserne reagerer.
Reelle farer ved dataorientering
Det å være dataorientert er ikke uten kostnader og farer. Analyse koster, i tid og penger. Å betale de ansatte for å gjøre slik dataene sier – i Harrah’s tilfelle, å betale bonuser basert på kundetilfredshet – koster.
Blir man for data-drevet, kan man komme til skade for å havne i en slags analysis paralysis der man ikke tør ta sjanser eller ikke gjør noe fordi man ikke klarer å komme på hvordan man skal teste det. Men den risikoen er adskillig mindre, i de fleste tilfeller, enn at man går glipp av innovasjoner fordi noen med beslutningsmyndighet i organisasjonen ikke har den rette følelsen for at noe bør gjøres.
Gary Loveman sier selv at hans fokus på at alt skal analyseres og dokumenteres – og at han ikke har noen personlige aksjer i hvilken løsning som blir valgt – fører til at han unngår å gjøre mange feil, at han unngår å gjøre ting han ikke burde gjøre. De som jobber mer inspirasjons- og intuisjonsbasert, vil gjøre en hel del spektakulære feil. Men de vil også av og til gjøre noe smart på tross av alle analyser og alle data.
Så får man velge – men jeg vil tro at for de fleste organisasjoner som har med kunder å gjøre, enten de er innenfor det private eller det offentlige, har mer å hente på å være data-drevne enn det motsatte.
Det som i alle fall er sikkert, er at om du lar din innovasjonsstrategi bestemmes av en gruppe ledere uten kundekontakt, basert på hvem som har det mest nøyaktige prosjektregnskapet og den proffeste PowerPoint-bunken, så lever du farlig.
Heskett, J. L., T. O. Jones, G. W. Loveman, W. E. Sasser, Jr. and L. A. Schlesinger (2008). «Putting the service-profit chain to work.» Harvard Business Beview86(7-8): 118.
I mai startet en debatt om hvorvidt ChatGPT bli dårligere. Til å begynne med var det brukere som syntes ting gikk nedover, men etterhvert har forskere og guruer meldt seg på og konstatert at svarene til ChatGPT (i hvert fall innenfor områder der det er mulig å måle kvalitet, som matematikk), typen sensitive spørsmål som kan besvares, koding og tolkning av bilder, har ting blitt dårligere over tid.
Årsaken er, paradoksalt nok, at OpenAI, firmaet bak ChatGPT, gjør endringer i algoritmene for å forbedre ChatGPT, for å øke kvaliteten og hindre at systemet blir brukt til ting det ikke skal brukes til. Og dermed synker altså den opplevde kvaliteten.
Dette paradokset er interessant fordi det illustrerer to fundamentale tilnærminger til kunnskapsbaserte systemer (som jeg synes er et mye bedre uttrykk enn «kunstig intelligens», av mange grunner).
Logiske modeller På 80-tallet, da jeg begynte å rote rundt med det som den gang ble kalt AI, var AI så og si synonymt med ekspertsystemer – det vil si systemer som kunne besvare spørsmål ved å etterligne hva en ekspert gjorde (og som ofte var laget ved at man intervjuet eksperter). De ble programmert som en rekke spørsmål – «Er pasienten kortpustet?», «Hvor mye røyker han?» – og stiller så en diagnose basert på beslutningstrær. I dagliglivet treffer du denne typen systemer som chatbotene som i alle fall forsøker å besvare enkle spørsmål i banken og andre steder man henvender seg.
Statistiske modeller På slutten av 80-tallet (vel, egentlig mye tidligere, men de ble vanligere da) kom nevrale nettverk og andre, mer statistisk baserte metoder, som tok utgangspunkt i store mengder data og konstruerte modeller som kunne klassifisere ting. I motsetning til ekspertsystemene, som var basert på en logisk modell av hvordan folk tenker, tok disse metodene inspirasjon fra en fysisk (og, for all del, teoretisk) modell av hvordan hjernen virker. De prøver seg frem til de finner en modell som gir ønsket resultat, ofte ved å konstruere nettverk av enkeltinformasjonselementer som er forbundet, og der forbindelser mellom elementer styrkes eller svekkes gjennom prøving og feiling.
ChatGPT og andre store språkmodeller hører til denne typen systemer: De forsøker å gjette det neste ordet i en setning rett og slett ved å ha lest enorme mengder tekst og velge det ordet som er mest sannsynlig.
Forskjellige feilmodus Disse systemene har mange forskjeller – en av dem er hvordan de gjør feil. Ekspertsystemene er nokså enkle – hvis de ikke finner et svar, sparker de problemet videre til noen som har svaret, som regel en person. De kan selvfølgelig også svare feil – men da er det som regel nokså enkelt å forstå at svaret er feil, siden det ser urimelig ut. De er på mange måter å sammenligne med søk i databaser, der man må være nokså presis i hva man spør etter, og databasen vil svare at den ikke har noe som passer hvis så er tilfelle.
Statistisk baserte modeller, derimot, vil alltid gi et svar. Slik er de mer å sammenligne med søkemotorer, som alltid vil forsøke å gi deg noe, selv om det ikke passer. (Når fikk du sist en melding fra Google om at det ikke fantes noen sider som oppfylte dine kriterier?) Svarene kan være riv ruskende gale, men vil se troverdige ut. En generativ språkmodell, som ChatGPT, har ingen underliggende fornuft, den forsøker bare å gjette hvilket ord som passer best, gitt de ordene som kom før.
Når kvalitetskontrollen roter til ting Et problem med de statistisk baserte modellene, i alle fall de som bruker nevrale nettverk, er at de kan bli riktig gode på å kategorisere ting – billedgjenkjenning, tekstgjenkjenning, tekstfortolkning – uten at man kan forklare, i alle fall på en måte mennesker kan forstå, hvordan de gjør det. Det kan også gjøre store logiske feil: Selv om ChatGPT kan skrive pressemeldinger og eksamensoppgaver som ser tilforlatelige ut, gjør den logiske feil – noe som ofte viser seg i at den produserer falske referanser, det vil si lager en referanseliste med artikler som ikke finnes. (Biblioteket på BI rapporterer om studenter som dukker opp og skal ha artikler av denne typen.) Den kan godt generere en caseanalyse eller en sosiologisk drøfting – der er jo grunnlaget ord (og mange av dem). Men folk som har bedt den skrive en artikkel innen fysikk eller matematikk, sier at den produserer noe som ser svært tilforlatelig ut hva teksten gjelder, men formler og formell deduksjon er helt håpløst.
Det betyr at man må putte på en eller annen form for kvalitetskontroll som er logisk basert – altså bruke ekspertsystemlogikk til å kontrollere det som genereres. Dette kan gjøres på mange måter: Man kan ha en inputkontroll (slik at folk ikke kan be ChatGPT skrive noe rasistisk eller instruksjoner for å lage en atombombe). Man kan kombinere ChatGPT med logiske systemer – for eksempel Matematica, Stephen Wolframs matematikkprogrammeringssystem, som nå integreres med ChatGPT.
Og det er her det ser ut til at det blir vanskelig.
Siden man ikke helt vet – i hvert fall ikke i detalj – hvordan ChatGPT produserer et tekststykke, blir det svært vanskelig å introdusere kvalitetskontroll eller andre begrensinger rett i modellen. Man blir henvist til enten å filtrere input og output – og det gjøres i stadig større utstrekning – eller (svært forenklet) å legge begrensinger på hva slags tekstmateriale som kan brukes som underlag for å generere ny tekst.
Jeg har litt følelsen at OpenAI (og deres konkurrenter) har laget ChatGPT og andre modeller, og nå står og ser på denne maskinen og ikke helt forstår hva de har laget. Jeg hadde en gammel og komplisert Mercedes for noen år siden. Den var kul (syntes jeg i alle fall), men jeg kunne jo ikke skru på den selv fordi den var så komplisert, og visste at nesten enhver ting jeg gjorde, hadde mye større sannsynlighet for å rote ting til enn å gjøre den bedre.
Men bare vent… Så det er ikke helt tid for å sparke kommunikasjonsavdelingen ennå – men kanskje tid for å ha flere folk til å kontrollere resultatet enn å generere innholdet. Ledere jeg kjenner, har kommentert at eposter de får har blitt lengre, høfligere og med rikere vokabular. Men jeg ville ikke helt automatisert epostene mine ennå, og slett ikke om de inneholder konkrete fakta og definitive avgjørelser.
Hva den automatiske kvalitetskontrollen gjelder, så er det fremdeles tidlig i språkmodellenes utvikling – hvis vi regner ChatGPT som begynnelsen. Men ChatGPTs røtter ligger i forskningen til Frank Rosenblatt fra tidlig sekstitall og Rumelhart og McClellands bok fra 1987 – og sett i det perspektivet er ChatGPT det foreløpig siste skrittet på en lang reise.
Da elektrisiteten kom, kom det også allslags finurlige apparater som skulle gi bedre hårvekst, bedre potens, og for alt jeg vet mer intelligens. Det samme gjaldt radium, kaffe, poteter og mye annet. Nå for tiden er det vel antioksydanter og AI som i har rollen som universalløsning. Over tid får man et mer edruelig forhold til fenomenet, bedre oversikt over bivirkninger, og fremfor alt bedre forståelse for hva det kan brukes til.
Så ChatGPT råtner egentlig ikke. Teknologien har i stedet startet på en prosess som over tid vil gjøre teknologien bedre, mer pålitelig, og med mer presist definerte bruksområder. Jeg tror mer på en gradvis forbedring enn en revolusjon der ChatGPT 7 eller 8 tar over verden. I mellomtiden forsøker jeg å lære meg å bruke de nye verktøyene smart – og insisterer på at de er verktøy og ikke noe annet.
EU har kommet med et forslag til nye lover som regulerer bruk av AI i bedrifter og organisasjoner. Såvidt jeg kan se, ligner forslaget på GDPR-lovgivningen: Ansvarliggjøring av styre og ledelse, bøter basert på omsetning ved overtredelser, og (sannsynligvis) et eller annet i retning av «safe harbor» bestemmelser slik at man kan være nogenlunde sikker på at man ikke gjør noe galt.
Et interessant aspekt her er at EU er tidlig ute i forhold til bruken av AI (ja, jeg vet det er et upresist begrep, men la det ligge foreløpig) og at man igjen tar ledelsen innen regulering der Silicon Valley (og Kina) har tatt ledelsen innen implementering.
Jeg skal finne ut mer om dette, i første omgang ved å høre på et webinar på konferansen Applied Artificial Intelligence Conference 2021. Seminaret (27. mai kl. 1430-1600) er åpent for alle som registrerer seg, og vil bli fasilitert av Elin Hauge, som er medlem av EGN AI og maskinlæring, et av EGN-nettverkene jeg leder.
Her forleden hadde jeg en hyggelig samtale med Eirik Norman Hansen – en gang min student, nå er ikke aldersforskjellen så voldsom lenger – om dataanalyse og hvorfor mange bedrifter sliter med det. Noe av det ble en podcast, her er detaljene:
Tenketanken Passivt-Agressivt Bøllefrø (@jeblad) er verdt å følge på Twitter. I går kom han med denne stripen med, tja, poengterte utsagn om den pågående AI-hypen:
Jeg må jo bare gi ham rett på alle punkter – og jeg driver faktisk og lærer opp bedrifter i å bruke disse teknikkene. I det siste har jeg til og med hørt folk snakke om å skaffe seg «en AI», omtrent som om det er noe personalavdelingen burde involveres i.
Men så er det jo slik at når teknologene mister kontrollen over det tekniske vokabularet (noen som husker debattene om den rette betydningen av «hacker»?) så er jo det et tegn på at teknologien faktisk begynner å brukes der ute. For oss som vet, naturligvis, er jo dette bittert. Som Stephen Fry sier (i en eller annen bok jeg ikke finner referansen til nå): Det er jo ingen som er surere enn de som digget Pink Floyd før The Dark Side of the Moon, og etter å ha snakket i årevis om hvor bra de var og at alle burde høre på dem så blir de sure når bandet blir allemannseie. Konklusjonen blir at Pink Floyd har solgt seg for popularitet og det er på tide å begynne å lete etter den neste nisjegreia verden ikke setter nok pris på.
Så vi teknosnobber får finne noen nye teknologier vi kan snakke om. Det pleier ikke være vanskelig.
I en datadrevet bedrift tar ikke lenger ledere beslutninger om hva som skal gjøres – det gjør modellene. Så hva står igjen for lederen å beslutte? Ny kommentar på Digi.no. Også gjengitt i BI Business Review.
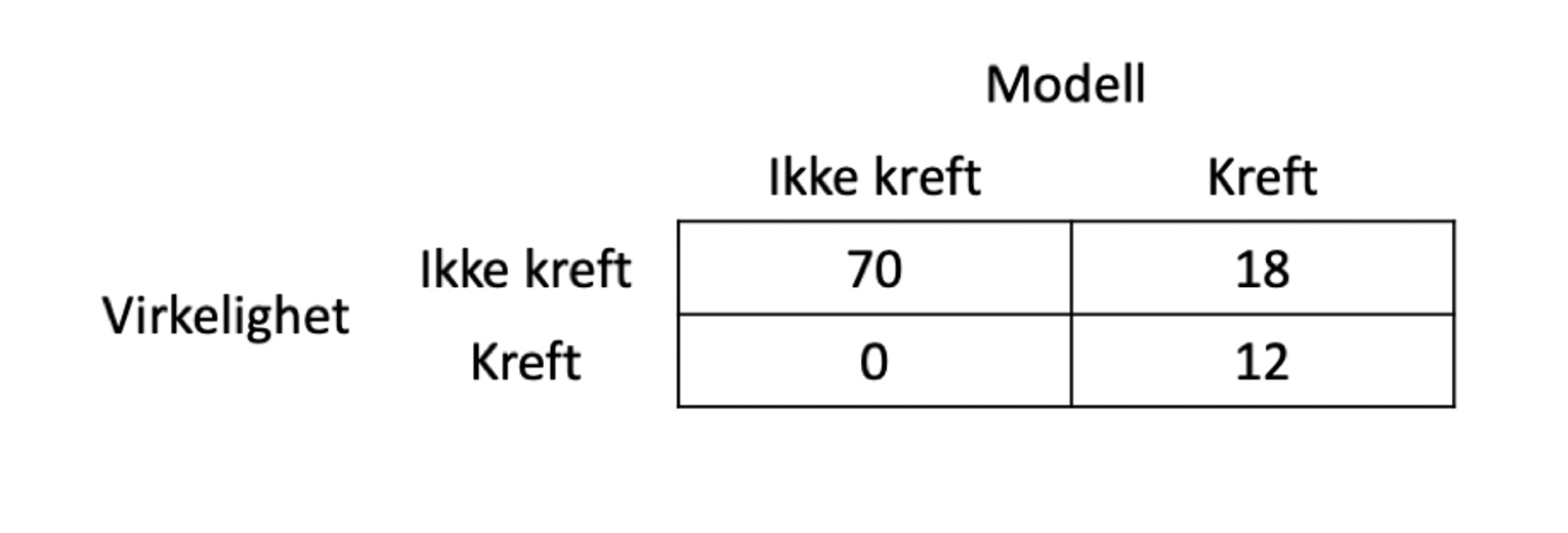
(Og jeg synes det er på tide at vi får uttrykket forvirringsmatrise inn i norsk språk.)
Som vanlig med lydfil. I denne lydfilen henviser jeg til to figurer og forsøker å beskrive dem – ta en titt på Digi eller se herunder hvis dette er uklart (og det er det…)
Data og dataanalyse blir mer og mer viktig for mange bransjer og organisasjoner. Er du interessert i dataanalyse og hva det kan gjøre med din bedrift? Velkommen til et tredagers seminar (executive short program) på BI med tittelen: Decisions from Data: Driving an Organization with Analytics. Datoene er 21-23 mai i år, og det haster derfor litt med påmelding! (Kontakt meg eller Kristin Røthe Søbakk (464 10 255, kristin.r.sobakk@bi.no) om du har spørsmål).
Kurset har vokst ut som en kortversjon av våre executive-kurs Analytics for Strategic Management, som har blitt meget populære og fort blir fulltegnet. (Sjekk denne listen for en smakebit av hva studentene på disse programmene holder på med.)
Seminaret er beregnet på ledere som er nysgjerrig på stordata og dataanalyse og ønsker seg en innføring, uten å måtte ta et fullt kurs om emnet. Vi kommer til å snakke om og vise ulike former for dataanalyse, diskutere de viktigste utfordringene organisasjoner har med å forholde seg både til data og til dataanalytikere – og naturligvis gi masse eksempler på hvordan man kan bruke dataanalyse til å styrke sin konkurransekraft. Det blir ikke mye teknologi, men vi skal ta og føle litt på noen verktøy også, bare for å vite litt om hva som er mulig og hva slags arbeid vi egentlig ber disse dataekspertene om å ta på seg.
Presentasjoner og diskusjon går på engelsk – siden, vel, de beste foreleserne vi har på dette (Chandler Johnson og Alessandra Luzzi) er fra henholdsvis USA og Italia, og dermed blir betydelig mer presise enn om de skulle snakke norsk. Selv henger jeg med så godt jeg kan…
Velkommen til tre dager med data og, etterhvert, strategi!
Sammen med Chandler Johnson og Alessandra Luzzi underviser jeg nå tredje iterasjon av kurset Analytics for Strategic Management. I løpet av kurset jobber studenter med reelle prosjekter for ordentlige selskaper, og bruker ulike former for maskinlæring (stordata, analytics, AI, hva du vil kalle det) til å løse forretningsproblemer. Her er en (for det meste anonymisert, bortsett fra offentlig eide selskaper) liste med resultatene så langt:
Et IT-serviceselskap som leverer data og analyser, ønsker å forutsi kundenes bruk av sine elektroniske produkter, for å kunne tilby bedre produkter og skreddersy dem mer til de mest aktive kundene. Resultat: Bedre salgsprediksjoner enn den eksisterende metoden (reduserte feilmodellering med 86%) – men modellen fungerer ikke langt frem i tid. Men den vil bli implementert.
En bensinstasjonskjede ønsker å beregne churn hos sine forretningskunder, for å finne måter å holde dem på (eller om nødvendig, endre noen av sine tilbud). Resultat: Fant en modell som identifiserer kunder som vil forlate dem, med en treffrate på 50% vil modellen forbedre resultatet med 25m kroner, og det er rom for å øke bruken av modellen utenfor de opprinnelige segmentene.
En frisørkjede ønsker å forutsi hvilke kunder som vil sette opp en ny avtale når de har klippet seg, for å bygge kundelojalitet. Resultat: Fant en modell som predikerte hvilke frisører som har problemer med å bygge opp en gruppe stamkunder (med omtrent 85% nøyaktighet), har klart å få en bedre forståelse av hva som driver kundelojalitet og dermed hvordan de kan hjelpe frisører med å få flere kunder.
En stor finansinstitusjon ønsker å finne ansatte som ser etter informasjon om kunder (for eksempel kjendiser), for å styrke personvern og datakonfidensialitet. Resultat: Slet med å få tak i nok og riktige data, men bygget en spesifikasjon av hva slags data som er nødvendig, hva det vil koste, og hva resultatet vil være – og fant at innenfor dette området finnes det svært få modeller, noe som er en mulighet. Og man fant noen lovende startpunkter for å bygge en slik modell. Vanskelig, men viktig område.
En stor offentlig IT-avdeling ønsker å forutsi hvilke ansatte som sannsynligvis vil forlate selskapet, for bedre å planlegge for rekruttering og kompetansebygging. Resultat: Bygget en prediksjonsmodell og en prosess som reduserer ledetiden for å ansette en ny person fra 9 til 8 måneder (en 10m innsparing) og dermed reduserer behovet for å utsette prosjekter på grunn av kapasitetsmangel, samt forbedre planleggingen av fremtidige kompetansebehov og øke sjansen for å beholde viktige ansatte.
OSL Gardermoen vil finne ut hvilke flypassasjerer som vil ønske å bruke taxfree-butikken etter at de har landet, for å øke salget (og ikke bry dem som ikke vil kjøpe taxfree). Resultat: Fant at noen variable man trodde ville øke taxfree-andelen ikke gjorde det, lærte mye om hva som gjør forskjell – og at modellen, hvis man klarer å bygge den, vil være mye verdt (en økning i taxfree-bruk på under en prosent vil øke Avinors inntekter med mer enn 100m). Samt at eksperimentering, ikke store prosjekter, er veien å gå videre.
En mindre bank ønsker å finne ut hvilke av sine yngre kunder som snart trenger et boliglån, for å øke sin markedsandel. Resultat: Bygget en modell som øker sannsynligheten for å identifisere førstegangs boliglånskunder, til en merverdi av 6,9 millioner kroner – samt at bruken av denne modellen introduserer datadrevne beslutninger for organisasjonen.
Et internasjonalt TV-selskap vil finne ut hvilke kunder som sannsynligvis vil si opp abonnementet sitt innen en bestemt tidsramme, for å bedre skreddersy sitt tilbud og markedsføring. Resultat: Bygget en modell med en kortsiktig beregnet merverdi på 500000 kroner per år, som treffer seks ganger bedre enn tilfeldige utvalg. I løpet av arbeidet har man funnet en rekke aktiviteter som kan øke kundelojaliteten uten store kostnader – og funnet inspirasjon for mer bruk av maskinlæring.
En leverandør av administrerte datasentre ønsker å forutsi sine kunders energibehov, for å kunne skrive og oppfylle konktrakter om sertifisert grønne datasentertjenester. Resultat: Bygget en modell basert på historiske sensordata for eksisterende kunder, for å forutsi forbruk for en ny kunde, og deretter en modell som inkluderer den nye kunden for å overvåke resultatet og forbedre modellen for alle kundene. En korrekt modell (som implementert) vil forbedre månedlig inntekt med 47% for en ny klient og redusere sjansen for kontraktsterminering.
Ruter (paraplyfirmaet for offentlig transport for Oslo-området) ønsker å bygge en modell for å bedre forutsi trengsel på busser, for å, vel, unngå trengsel. Resultat: Bygget en modell og et forslag til en tjeneste for å kunne fortelle Ruters kunder om det (sannsynligvis) er ledige seter på bussen eller ikke, går nå til testing.
Barnevernet ønsker å bygge en modell for å bedre forutsi hvilke familier som mest sannsynlig vil bli godkjent som fosterforeldre, for å kunne prioritere saksbehandling og redusere ventelister. Resultat: Tross mye manglende data klarte man å finne gode indikatorer på godkjente fosterforeldre og har lagt en plan for videreutvikling av modellen etterhvert som man får bedre data. Området er lovende, siden behovet for fosterforeldre er stort og selv en liten forbedring vil hjelpe.
Et strømproduksjonsselskap vil bygge en modell for å bedre forutsi strømforbruket i deres marked for å kunne planlegge produksjonsprosessen bedre. Resultat: Testet mange modeller og har funnet at å forutsi spot-priser er vanskelig, men har klart å finne indikatorer på økt volatilitet, noe som gjør at man kan produsere noe mer presist. Kortsiktig effekt av en liten modell er 100-200 tusen euro per år for hver produksjonsenhet, et tall som forventes å øke siden volatiliteten i markedet vil øke fremover.
Alt i alt er vi svært fornøyd – vi har klart å øke verdien, samlet sett, for disse selskapene adskillig mer enn kurset koster (I hvert fall 10-gangen, konservativt anslått). Flere av deltakerne har fått nye stillinger og flere av dem har bestemt seg for at data science er en retning de skal fortsette å utvikle seg i, og ønsket seg flere slike «tekniske» kurs. Og gitt at vi også har produsert en masse kunnskap og generelt økt deltakernes evne til å bygge bro mellom analytikere og forretningsfolk, tror jeg vi kan erklære dette prosjektet for en suksess…